🐉 龙哥读论文知识星球来了!还在为自动驾驶感知系统又慢又贵而头疼?想了解如何用一个摄像头搞定所有事?星球每日更新AI领域最新论文、资讯、招聘、开源代码,帮你快速抓住技术核心,节省90%读论文时间!👇扫码加入「龙哥读论文」知识星球,前沿干货、实用资源一站式拿捏~

龙哥推荐理由:
自动驾驶的“眼睛”既要看得准,又要反应快,这常常是个两难选择。今天解读的这篇论文提出了一个非常“接地气”的解决方案:LRHPerception。它不追求炫酷的多传感器融合,而是专注于如何用好一个普通的单目摄像头,把目标跟踪、轨迹预测、道路分割和深度估计这四大感知任务高效地“打包”处理。最吸引人的是,它在单块RTX 3090 GPU上跑出了29 FPS的实时速度,比最快的多摄像头建图方案还快55%!对于追求低成本、高实时性的自动驾驶应用(比如物流小车、园区接驳车)来说,这无疑是一个极具吸引力的技术路径。让我们一起来看看它是如何做到的。
原论文信息如下:
论文标题:
Single-Eye View: Monocular Real-time Perception Package for Autonomous Driving
发表日期:
2026年03月
发表单位:
未明确标注
原文链接:
https://arxiv.org/pdf/2603.21061v1.pdf
开源代码链接:
LRHPerception (论文中提及,但未提供具体URL)
想象一下,你正坐在一辆自动驾驶汽车里。工程师告诉你,为了确保安全,车上装了十几个摄像头、激光雷达和毫米波雷达,算力堪比一台小型服务器。听起来很靠谱,对吧?但成本呢?功耗呢?万一某个传感器出故障了呢?
另一边,有工程师提出:“人类开车不就靠两只眼睛吗?我们能不能也让AI只用‘一只眼睛’(单目摄像头)就看懂世界,并且反应足够快?”这个想法很诱人,但挑战巨大:一个摄像头,既要识别物体、预测它们下一步去哪,又要分清哪里是路、哪里是障碍物,还得估计距离……这可不是简单的“看图说话”。
今天要聊的这篇论文,就带来了一个名叫 LRHPerception 的系统。它就像一个视觉“全能战士”,只用单个摄像头的视频流,就能实时搞定目标跟踪、轨迹预测、道路分割和深度估计这四大任务,并且在单块RTX 3090显卡上跑出了 29 FPS 的速度,号称比最快的多摄像头建图方案还快 55%。单目感知新范式:LRHPerception如何实现实时多任务处理?
在自动驾驶领域,让车“看懂”周围环境主要有两大流派。
1. “端到端”黑盒流:给神经网络喂原始图像,直接输出方向盘转角、油门刹车指令。优点是速度快,但缺点也很明显——像个“黑盒子”,出了事你很难知道它为啥做出那个决策,安全感不足。
2. “多传感器融合建图”流:用多个摄像头甚至激光雷达,构建出车辆周围的鸟瞰图或3D占据栅格地图。这种方法信息丰富、可解释性强,但计算量巨大,很难在普通车载硬件上实时运行。
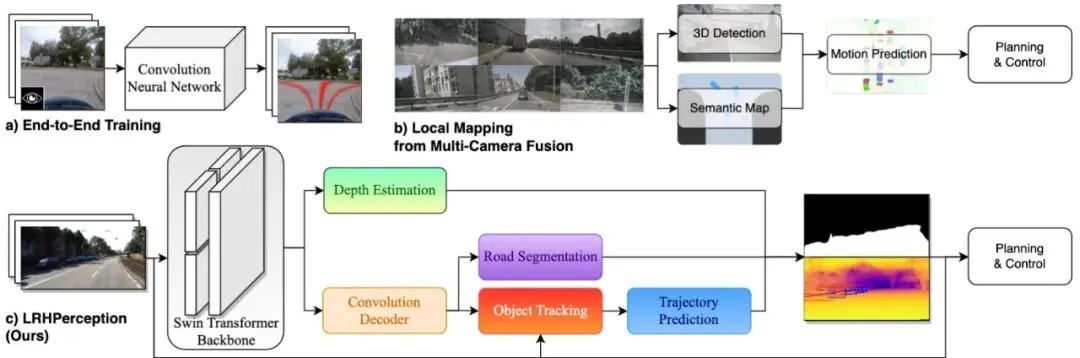
图1:创新与架构蓝图 a) 端到端解决方案的范式 b) 用于局部地图的摄像头融合解决方案的范式 c) 我们的LRHPerception包的范式,从单目摄像头中提取精华,实现成本与信息的权衡。
LRHPerception 想走第三条路:既要像多传感器方案那样信息丰富、可解释,又要像端到端方案那样快速、低成本。
通道1:原始RGB图像 – 输入是什么,我原样给你一份。通道2:道路分割图 – 用不同颜色标出哪里是车可以行驶的路面。通道3:像素级深度估计图 – 图上每个像素点都对应一个估计的距离值,离得越近越亮,越远越暗。叠加信息:目标检测框与轨迹预测 – 在图像上画出检测到的车辆、行人等物体的框,并用线条预测它们未来的运动轨迹。
你可以把它理解为一个为下游规划控制模块准备的、信息全面的“标准化感知接口”。有了这些信息,决策系统就能更清晰、更安全地规划路径。
核心创新点剖析:共享Backbone与模块集成如何大幅提效?
LRHPerception 能达到实时性能的秘诀,不在于用了什么惊世骇俗的新模型,而在于一个非常巧妙的 “中央厨房+分餐制”设计。
中央厨房(共享Backbone):输入一张RGB图片,系统首先用一个强大的特征提取器(Backbone)进行加工。论文选择了 Swin Transformer,它在图像理解任务上表现出色。这个 Backbone 就像中央厨房,一次性把食材(图片)处理成不同粗细程度的“食材半成品”(特征图),记作 Φ₄, Φ₈, Φ₁₆, Φ₃₂(数字越小,特征图分辨率越高,细节越多)。
这些“半成品”被分发给四个专门的“厨师”(功能模块):目标跟踪与轨迹预测模块:主要接收 Φ₈, Φ₁₆, Φ₃₂ 这些细节稍少但语义信息丰富的特征,通过一个卷积解码器来生成检测框,并进行跟踪和轨迹预测。道路分割模块:同样接收来自卷积解码器的 Φ₈ 特征,专注地分辨路面。深度估计模块:接收所有层次的特征(Φ₄ 到 Φ₃₂),因为深度估计既需要细节(物体边缘),也需要全局上下文(场景结构)。
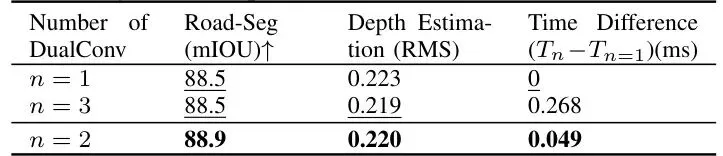
这个设计的精妙之处在于避免了重复劳动。传统方法如果要把这四个任务独立实现,每个任务都需要自己的Backbone来提取特征,相当于建了四个中央厨房,计算量暴增。而LRHPerception只用一个中央厨房,服务所有厨师,计算成本直接从“4份”降到了“1份多一点”,这是其实现实时性能的基石。模块深度解读:C-BYTE跟踪、轻量分割与深度估计有何玄机?
除了架构设计,每个功能模块内部也有自己的“小巧思”,在保证精度的前提下进一步压榨性能。
目标跟踪,简单说就是在连续视频帧中找到同一个物体。经典方法ByteTrack已经很强,但它默认摄像头是静止的。在自动驾驶中,车自己在动,摄像头也在动,这会干扰跟踪。
C-BYTE (Camera-Calibrated BYTE) 的核心创新是加入了摄像头运动矫正。
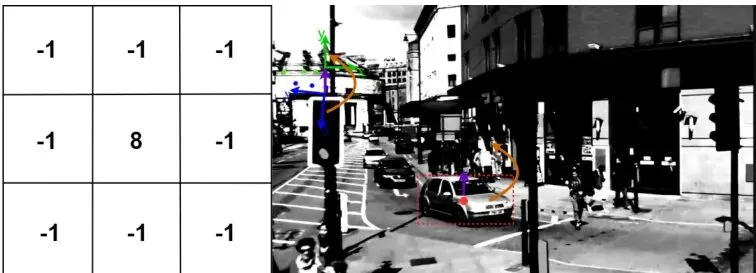
1. 提取“路标”:在上一帧图像中,用拉普拉斯算子找到一些明显的角点或边缘点(比如窗户角、车牌边缘),作为“路标”。
2. 计算“路标”移动:用 LK光流法 (Lucas-Kanade Optical Flow) 估计这些“路标”从上一帧到当前帧移动了多少。光流可以理解为图像中每个像素点的运动速度和方向。
3. 估算整体运动模型:根据大量“路标”的移动,用RANSAC算法拟合出一个仿射变换矩阵。这个矩阵描述了整幅图像因为摄像头运动而产生的平移、旋转等整体变化。
4. 矫正预测框:跟踪算法本身(如卡尔曼滤波)会预测物体下一帧的位置。C-BYTE用上一步算出的仿射变换矩阵去矫正这个预测位置,消除摄像头自身运动带来的偏差,然后再和当前帧实际检测到的框进行匹配。
图3:卷积核与变换可视化。右侧,蓝色和绿色点分别代表上一帧和当前帧的关键点。紫色和橙色箭头表示位移和旋转变换。红色虚线框是卡尔曼滤波器预测的物体位置。
这就好比你在行驶的火车上看窗外,一棵树在后退。ByteTrack可能以为树自己在跑,而C-BYTE能意识到:“哦,是我在动”,从而更准确地判断树的位置。
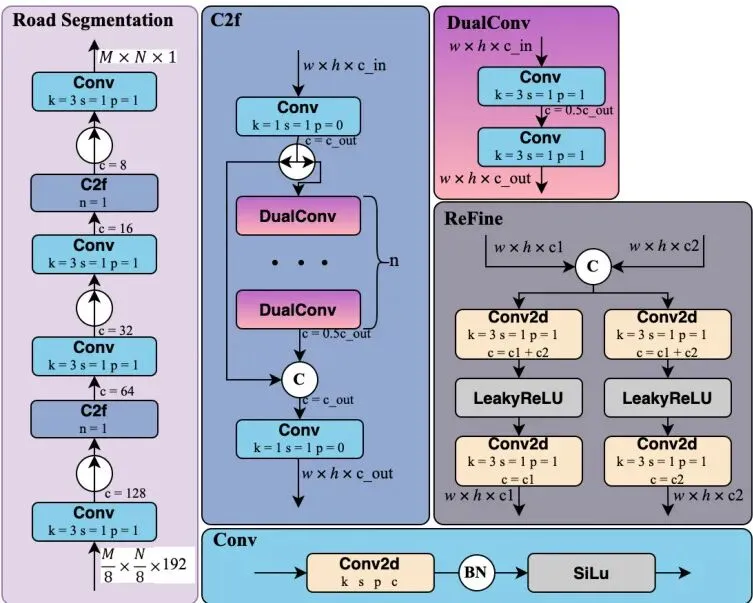
道路分割模块非常“专一”。它不搞复杂的全景分割(识别图中所有物体类别),只专注于一件事:分辨可行驶路面。任务简单了,模型就可以设计得非常轻量。它直接利用共享特征中的Φ₈,经过一个简化的U-Net解码器,快速输出分割图。这种“术业有专攻”的思路,是提升效率的关键。
图4:详细模型结构: 道路分割块的设计,以及其他组件。
深度估计模块则采用了“先粗后精”的两阶段策略。先用深层特征(Φ₁₆, Φ₃₂)快速生成一个粗糙的、低分辨率的深度图,把握大局。然后再结合更浅层、细节更丰富的特征(Φ₄, Φ₈ 等),对这个粗糙深度图进行上采样和 refinement(精修),最终得到高分辨率、精细的深度图。这比一上来就处理所有细节要高效得多。
实验效果一览:速度与精度是否真的兼得?
纸上谈兵没用,是骡子是马拉出来溜溜。论文在多个标准数据集上进行了测试,并与当前最优方法(SOTA)对比。所有实验均在单张RTX 3090 GPU上进行。
整体性能:LRHPerception 打包处理所有任务的最终速度是 29 FPS,达到了实时水平。作为对比,论文中提到的最快的多摄像头局部建图方法速度低于10 FPS。
图5:结果可视化。四张图像描绘了LRHPerception的输出,过去的轨迹用蓝色描绘,未来的轨迹预测用红色描绘。上面一对图像展示了两个成功案例,而下面一对展示了一个失败案例。
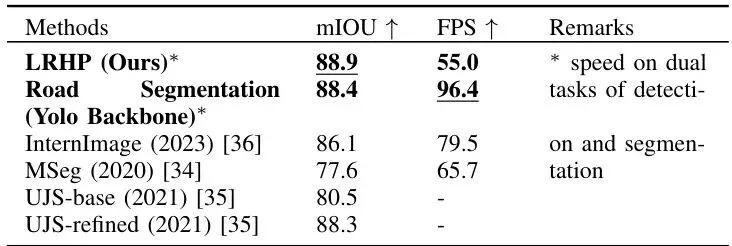
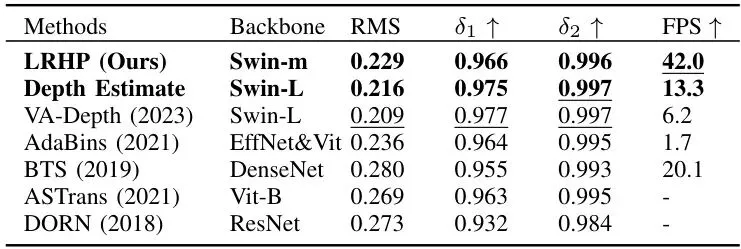
分模块看,结果同样令人印象深刻(表格中加粗的为本文方法,带下划线的为对比方法中的最优值):
表I:目标跟踪。我们的模型在MOT数据集上,在所有效能和效率指标上都表现出相对于SOTA的显著改进。
C-BYTE跟踪:在MOTA(多目标跟踪准确度)、IDF1(身份识别F1分数)等关键指标上均超越了原版ByteTrack和其他SOTA方法,且处理时间(31.0ms)仅比最快的对比方法慢几毫秒,可谓用极小的延迟代价换来了精度提升。
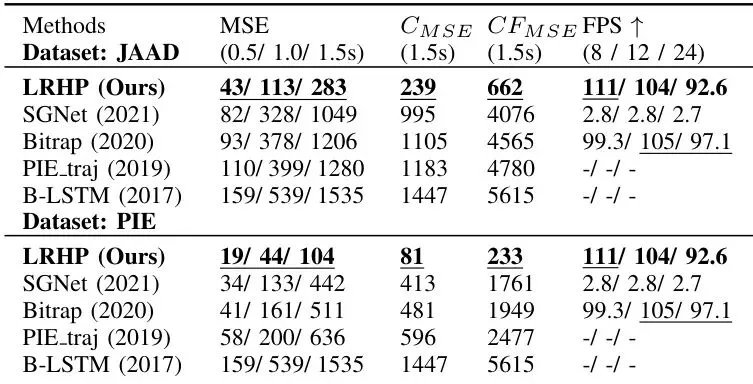
表II:轨迹预测。我们的模型在效能和效率的所有方面都表现出相对于SOTA方法的显著增强,随着预测时间的延长,这一点尤其明显。
轨迹预测:在JAAD和PIE数据集上,其预测误差(MSE)远低于其他方法,尤其是预测时间越长(如1.5秒后),优势越明显。同时,它的推理速度(FPS)也远超SGNet等模型。
道路分割与深度估计:同样在精度(mIOU, RMS误差)上达到或逼近SOTA水平的同时,在速度上具有明显优势。特别是深度估计,用中等规模的Swin-m骨干网就能达到42 FPS,而精度与使用更大骨干网的VA-Depth等模型相当。
实验结果分析:从结果来看,LRHPerception 确实实现了其设计初衷——在信息丰富度、可解释性和实时效率之间找到了一个出色的平衡点。每个模块的创新都取得了预期效果:C-BYTE的相机运动补偿提升了跟踪鲁棒性;轻量化的专一设计让分割和深度估计更快;而共享Backbone的集成架构是整体速度飞跃的根本原因。这证明,在工程实践中,精巧的系统级设计往往比一味堆砌模型复杂度更能带来质的提升。未来展望:单目感知的潜力与挑战何在?
LRHPerception 展示了单目感知系统在低成本、高实时性自动驾驶场景(如园区物流车、低速接驳车、辅助驾驶)的巨大潜力。它提供了一条清晰的技术路径:通过系统级优化,最大化单一廉价传感器的价值。
单目深度估计的固有局限性:没有立体视觉或先验信息,单目深度估计在绝对距离精度、对陌生场景的泛化能力上依然不如激光雷达或多目立体视觉。这在高速等安全性要求极高的场景中是致命弱点。极端天气与光照:摄像头在夜间、雨雪雾、强光逆光等条件下的性能会急剧下降,而多传感器融合系统可以通过雷达等进行互补。系统冗余与安全性:对于L4级以上自动驾驶,传感器冗余是必须的。纯单目方案目前难以满足最高等级的安全要求。
因此,LRHPerception 更像是一个优秀的“启发性方案”。它的设计哲学——共享计算、模块化集成、在特定任务上做减法——可以被广泛应用。未来,我们或许会看到“LRHPerception+”的出现:例如,将其作为主感知系统,在必要时与一个低成本毫米波雷达进行松耦合,以极低的成本获得接近多传感器系统的鲁棒性。或者,将其核心集成思想移植到以Transformer为核心的新一代视觉大模型(VLM)中,实现更通用、更强大的多任务感知。
龙迷三问
这篇论文的LRHPerception具体是做什么的?它是一个面向自动驾驶的实时视觉感知软件包。输入是一个普通单目摄像头的视频,输出是一个包含五类信息的“感知包”:1)原图;2)道路区域分割图;3)每个像素的深度估计图;4)画面中车辆、行人等目标的位置框;5)对这些目标未来移动轨迹的预测。它把四个核心感知任务打包在一起高效处理。
LRH这个名字是什么意思?是 Low-cost (低成本), Real-time (实时), High Information richness (高信息丰富度) 的缩写。这三点正是这个系统追求的核心目标。
能简单介绍一下文中提到的几个基本感知任务吗?
- 目标检测与跟踪:找到图像里有什么物体(车、人),并在连续帧中确定是同一个物体。
- 轨迹预测:根据物体过去的运动轨迹,预测它未来几秒钟可能会怎么走。
- 语义分割:把图像的每个像素都分类,比如天空、道路、车辆。本文专注于道路分割,只分“可行驶路面”和“其他”。
- 深度估计:从2D图像推断出每个像素点距离摄像头的3D距离,这是单目视觉中最具挑战的任务之一。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~龙哥点评
论文创新性分数:★★★★☆
四星。创新点不在于发明了新模型,而在于巧妙的系统集成与工程优化。将四个独立任务通过共享Backbone和特征复用高效打包,并针对每个任务做了轻量化改进(如C-BYTE的相机矫正、专注道路的分割),这种“组合拳”式的创新在实践中价值很高。实验合理度:★★★★☆
实验设计比较扎实,在多个权威数据集上与对应任务的SOTA进行了对比,既有模块单独对比,也有整体效能展示。速度和精度指标都有呈现。不足是缺少在更复杂、更长尾的真实道路视频上的端到端闭环测试。学术研究价值:★★★☆☆
三星半。这篇论文更偏向于工程实现和系统验证,为“如何构建高效的单目多任务感知系统”提供了一个优秀的范本和具体的性能基线,对后续的工程研究和应用开发有明确的借鉴意义。但在核心算法理论上的突破有限。稳定性:★★★☆☆
基于论文描述和实验,在训练数据覆盖的场景下应具备较好的稳定性。但其性能上限受限于单目视觉本身,在极端光照、天气、严重遮挡或完全陌生的结构化场景下,深度估计和分割的稳定性会面临挑战。适应性以及泛化能力:★★★☆☆
模块化的设计有利于针对新场景进行微调。但单目深度估计和基于视觉的跟踪本身泛化能力就有限,迁移到与训练数据分布差异过大的新环境(如从城市到乡村,从白天到黑夜)时,需要重新收集数据并进行适配。硬件需求及成本:★★★★☆
四星。单张RTX 3090 GPU实现29 FPS,这个硬件要求在研发和特定商用场景(如特定园区、物流车)中是完全可以接受的,体现了其“低成本”的设计目标。但对于大规模前装量产的低功耗车规级芯片,仍需进一步的模型压缩和优化。复现难度:★★★☆☆
论文中提到了代码可用,但未给出具体链接。其方法描述较为详细,模块清晰,但涉及多个子任务和数据集的多任务训练,工程实现和调优有一定复杂度。若代码开源,复现难度会大大降低。产品化成熟度:★★★☆☆
三星半。非常适合作为特定场景(低速、封闭/半封闭园区、辅助驾驶功能)的感知解决方案原型。但要达到车规级前装量产的安全和可靠性标准,还需要大量的鲁棒性测试、冗余备份设计以及与底盘控制的闭环验证。可能的问题:论文作为技术报告非常出色,但若以顶会论文标准看,在核心算法创新深度上稍显不足,且缺乏对失败案例和系统边界(如何种条件下会失效)的更深入分析。整体偏向于一个优秀的工程项目总结。
[1] Zhang, H., Zuo, A., Li, Z., Wu, C., Geng, T., & Duan, Z. (2026). Single-Eye View: Monocular Real-time Perception Package for Autonomous Driving. arXiv preprint arXiv:2603.21061.*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的"阅读原文",查看更多原论文细节哦!

想和更多自动驾驶、机器人领域的小伙伴一起探讨像LRHPerception这样的高效感知方案吗?欢迎加入龙哥读论文粉丝群,
扫描下方二维码或者添加龙哥助手微信号加群:kangjinlonghelper。
一定要备注:研究方向+地点+学校/公司+昵称(如 自动驾驶+北京+清华+龙哥),根据格式备注,可更快被通过且邀请进群。