
Trans小编导读
大型多模态模型在自动驾驶中的应用面临场景理解弱、长尾泛化差和部署效率低等挑战。清华大学团队提出了一套面向部署的统一优化框架,系统性地融合了动态提示优化、混合数据构建和轻量化模型适配策略。该研究为打通大模型能力与自动驾驶端侧部署之间的路径提供了系统性解决方案,显著提升了在复杂与资源受限场景下的感知性能。

基本信息
标题:A dynamic prompting and scenario generation method for autonomous driving perception via large-model optimization「一种基于大模型优化的自动驾驶感知动态提示与场景生成方法」作者:Song Zhang, Hongyi Lin, Mengjie Wang, Bangyang Wei, Yang Liu, Xiaobo Qu期刊:Transportation Research Part C: Emerging Technologies链接:10.1016/j.trc.2026.105672
研究亮点
- 提出了一种动态迭代的提示优化策略,通过模型反馈持续改进提示模板,从而在不修改模型权重的情况下提升其在特定任务上的表现。
- 设计了一个可扩展的混合数据集构建流程,将自采集的真实世界数据与通过T2I生成和程序化渲染技术产生的合成数据相结合,有效缓解了自动驾驶长尾场景的数据稀缺问题。
- 构建了一个面向部署的统一模型优化框架,该框架系统性地集成了知识蒸馏、参数高效微调(LoRA)和激活感知量化(AWQ),实现了大模型在资源受限的车载平台上的高效、高性能部署。
论文摘要
大型多模态模型的出现为高度自动化驾驶提供了新的可能性。然而,它们在复杂驾驶场景中的实际部署仍受限于场景理解能力弱、对长尾情况泛化性差以及缺乏系统性集成管道以进行实际操作等问题。本文并非引入一个独立的全新算法,而是提出了一个统一的、面向部署的框架,用于将多模态大型模型集成到自动驾驶感知系统中。我们的方法强调在提示、混合数据构建和轻量级模型适应性方面的系统级耦合,形成一个结构化的开发工作流程,将大模型能力转化为可部署的性能。我们采用迭代动态提示策略,通过验证反馈优化模式受限的提示模板,而无需修改模型权重。为了缓解长尾数据稀缺问题,我们构建了一个混合数据集,结合了自收集的驾驶日志与通过文本到图像和程序渲染管道生成的可控合成场景,并辅以自动化标注工作流程以实现可扩展的监督。为了高效部署,我们集成了知识蒸馏、参数高效微调(LoRA)和激活感知量化(AWQ),从而在边缘计算约束下实现资源高效推理,同时保持强大的感知性能。实验结果表明,所提出的框架提高了代表性驾驶感知任务的准确性,包括锥桶检测、交通灯识别和限速推荐。总的来说,这项工作建立了从大型多模态模型能力到长尾和资源受限环境下实际自动驾驶部署的操作路径。
1. 研究动机
尽管自动驾驶技术发展迅速,但车辆感知系统在应对多样化、不可预测的真实世界环境时,其泛化能力依然不足。特别是对于罕见但至关重要的长尾场景(如异常道路事件、特殊天气),现有系统常常表现出鲁棒性欠佳的问题。传统的监督学习方法依赖于固定的、预定义的数据类别,难以实现开放世界下的深度场景理解。
近年来,大型视觉语言模型(VLMs)为增强场景理解与适应性带来了新的可能。然而,将这些强大的模型直接应用于自动驾驶感知任务面临三大核心挑战:
- 提示依赖性:模型性能高度依赖于精心设计的提示(Prompt),在多变的任务和场景中缺乏适应性。
- 数据稀缺性:针对长尾场景的高质量数据收集与标注成本高昂,难以形成完备的数据集。
- 部署效率低:大模型计算量大、延迟高,难以在资源受限的车载边缘设备上高效部署。
为应对上述挑战,本文并未提出一个全新的独立算法,而是构建了一个面向部署的统一优化框架。该框架旨在系统性地整合动态提示、混合数据生成和轻量化模型适配等环节,将大模型强大的通用能力转化为可在真实世界中高效部署的感知性能,从而弥合前沿模型潜力与实际应用需求之间的鸿沟。
2. 研究方法
本文提出的方法遵循一个集成了动态提示构建、混合数据集生成和高效大模型适配的统一优化流程。该流程旨在系统地增强多模态模型的感知能力,同时确保其轻量化部署,满足自动驾驶的实际应用需求。
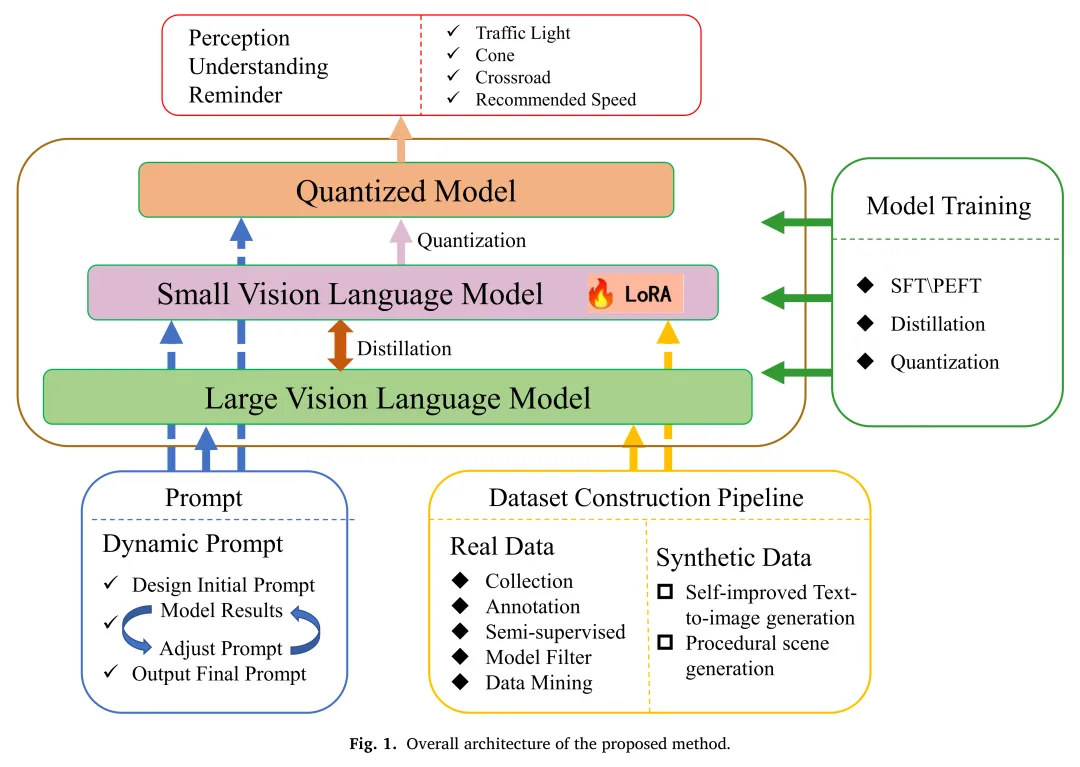
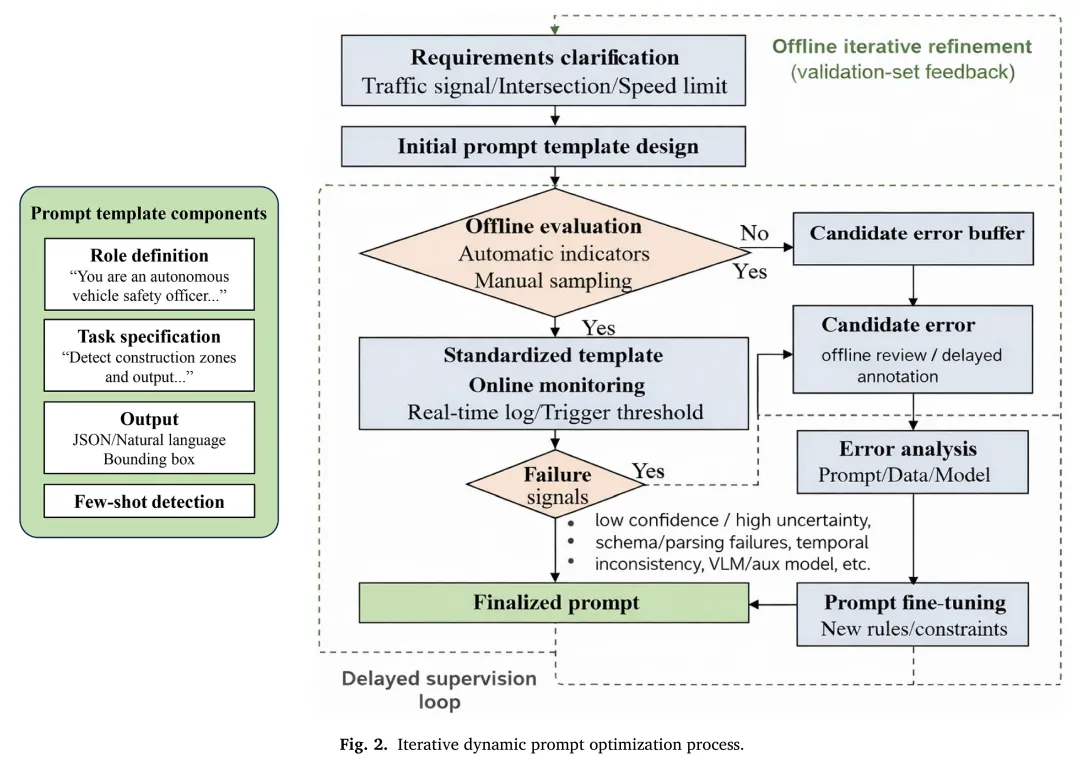
动态提示优化
提示设计在引导模型理解特定任务方面起着关键作用。本文提出一种动态提示优化策略,通过一个多轮迭代过程,根据模型在验证集上的反馈来系统性地优化提示模板,从而将通用模型转化为任务专家。该过程完全基于规则进行,不涉及模型权重的梯度更新,因此独立于模型训练。具体而言,团队首先设计初始提示模板,然后收集模型在验证数据上的失败案例,并根据错误类型(如低光照下的目标漏检、输出解析失败等)对提示进行针对性修改。整个优化过程通常在3-5次迭代内收敛,有效提升了模型输出的准确性和可靠性。
混合数据集构建
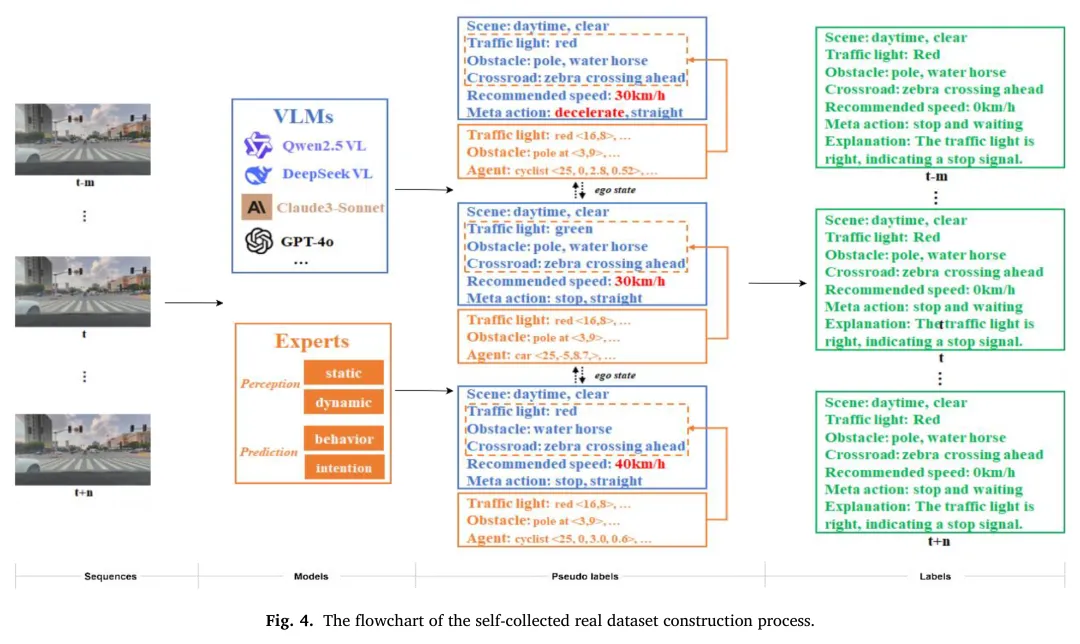
为了克服真实世界数据采集的局限性并解决长尾场景数据稀缺的问题,本文设计了一种混合数据集构建策略,结合了真实驾驶数据与大规模场景生成。
首先,对于 自采集的真实数据 ,框架采用“大模型辅助-专家模型交叉验证-人工审核”的流程进行挖掘与标注。利用VLM(Qwen2.5-VL)生成结构化的初始标签,并由领域专家模型进行二次验证。当两者存在分歧或模型不确定性高时,样本将被提交给人类审核员进行最终裁定,确保了标注的高效性与准确性。
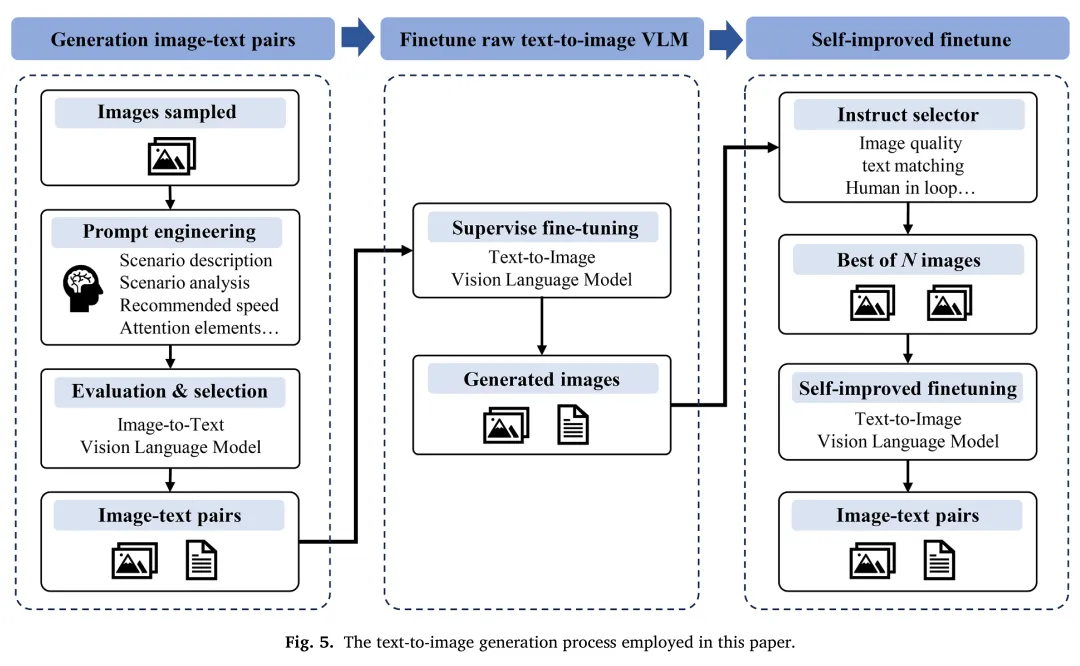
其次,为了补充真实数据的覆盖范围,框架采用了两种 合成数据生成 方法:
- 文本到图像(T2I)生成:通过一个自优化的训练流程,利用包含丰富场景描述的图文对微调T2I模型。该模型能够生成多样化的驾驶场景,特别是一些难以在现实中采集的极端天气或罕见事件,从而丰富了数据的多样性。
- 程序化3D场景渲染:利用Blender等工具,结合SUMO、CARLA等模拟器,生成结构化、任务明确的驾驶场景。这种方法可以精确控制场景中的各类元素(如道路布局、障碍物位置、光照条件),为特定任务(如交叉路口红绿灯识别)提供高质量、高保真的训练样本。
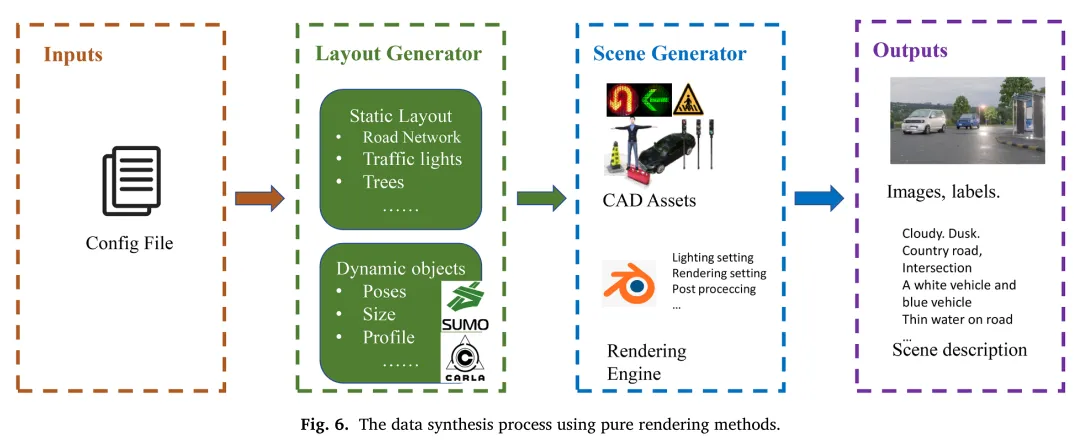


轻量化模型适配
为满足车载环境资源受限的要求,本文设计了一个包含知识蒸馏、参数高效微调和量化三个阶段的混合优化策略,以实现模型的轻量化部署。
- 知识蒸馏:首先,将大型教师模型(Qwen2.5-VL-72B-Instruct)的知识迁移到一个轻量级的学生模型(Qwen2.5-VL-7B-Instruct)中。该过程采用结合了软标签损失和硬标签损失的混合损失函数。软标签损失通过计算KL散度 ,促使学生模型学习教师模型的输出分布,从而继承其强大的推理能力。
- LoRA微调:在知识蒸馏后,采用低秩自适应(LoRA)技术对学生模型进行特定驾驶任务的微调。LoRA通过在Transformer层中注入可训练的低秩矩阵,在冻结大部分预训练参数的同时,高效地使模型适应新任务,大幅降低了训练成本。
- 部署导向量化:最后,应用激活感知权重化(AWQ)技术对模型进行量化。该方法根据激活值的分布来调整权重,将高精度参数转换为4位低精度表示,显著减少了模型的计算复杂度和内存占用,同时最大限度地保留了模型性能,使其适用于边缘设备部署。
3. 核心结论
本文通过在自建混合数据集上进行的大量实验,验证了所提出的统一优化框架的有效性。研究的核心结论主要体现在以下几个方面。
首先,该框架显著提升了自动驾驶感知任务的整体性能。实验结果表明,相较于开源的基线模型,经过本文完整优化流程(包括动态提示、知识蒸馏、LoRA微调及量化)训练后的模型,在锥桶检测、交通灯识别和推荐时速等多个任务上的平均准确率从0.542大幅提升至0.894。这证明了本文所提出的系统性优化方法能够成功地将大模型的能力转化为轻量化、高性能的端侧应用。
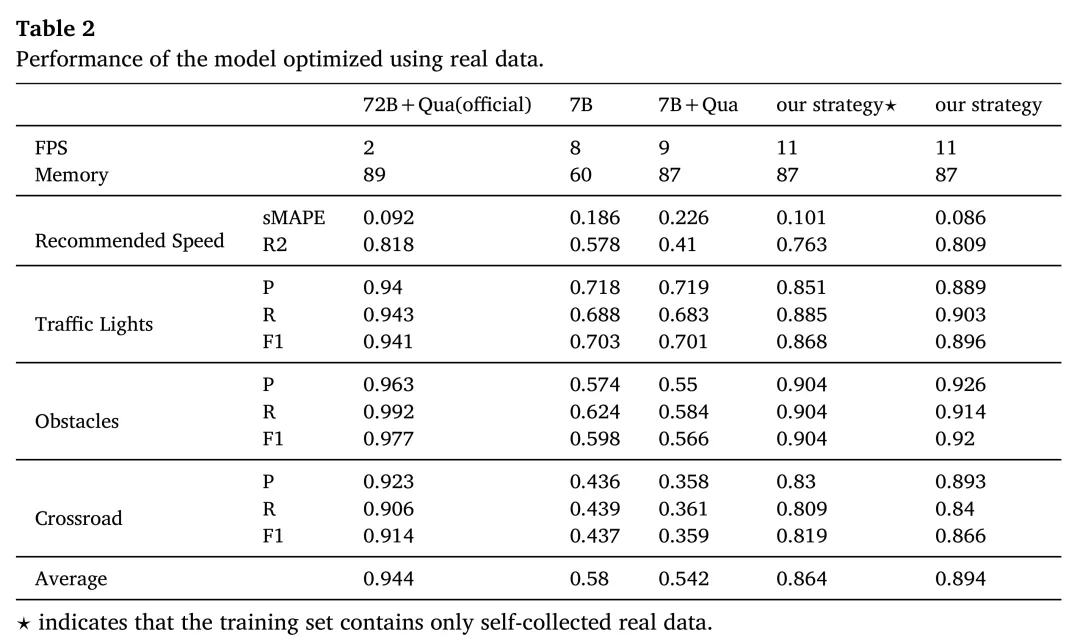
其次,动态提示优化是提升模型任务适应性的关键环节。消融实验显示,仅通过动态提示优化策略,基线7B模型的平均准确率就提升了约10%(从0.484提升至0.580)。尤其对于需要深度场景理解的任务,如推荐时速(R2分数提升超过16%)和施工区域检测(F1分数提升0.222),优化后的提示能够引导模型更准确地关注关键信息,从而显著改善性能。

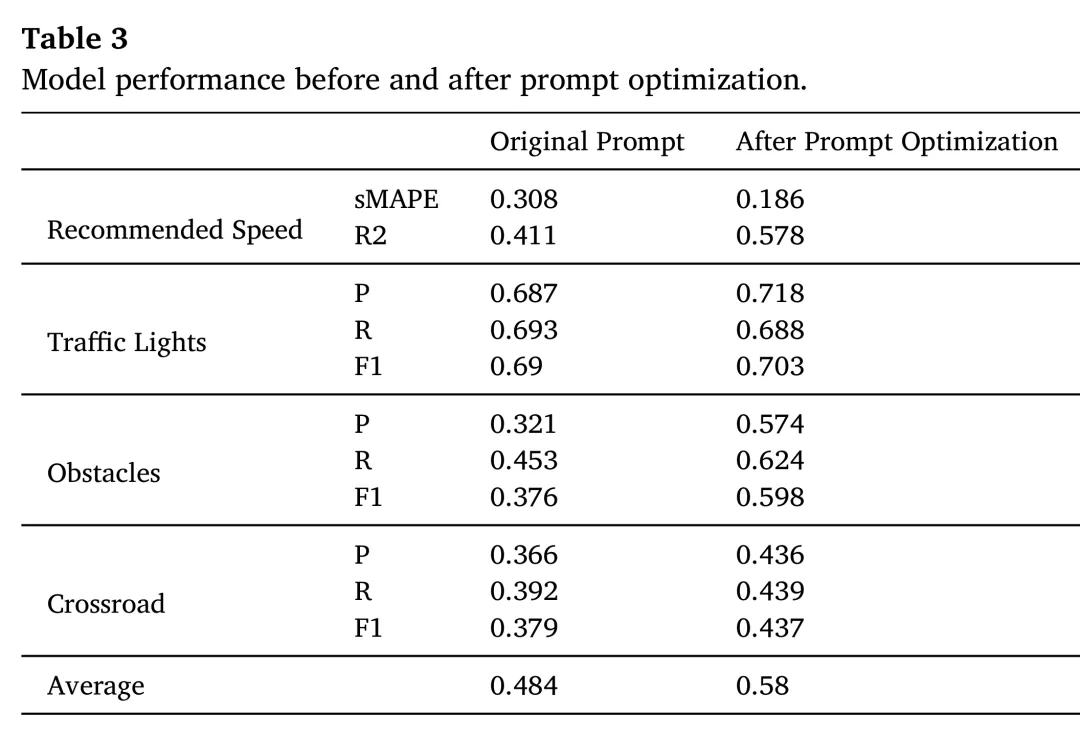
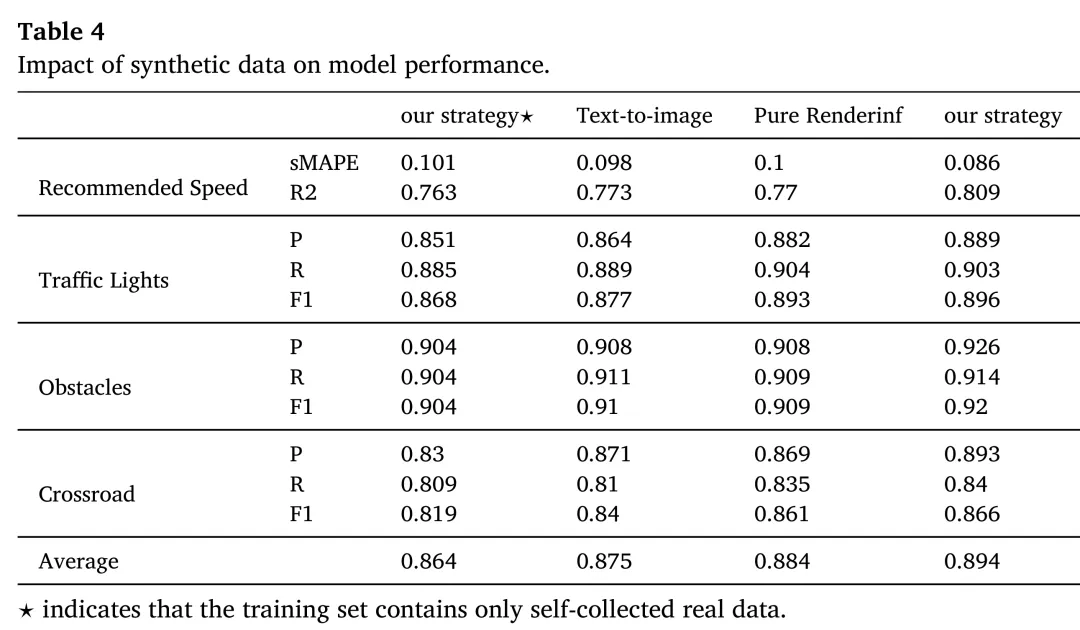
最后,合成数据对于增强模型在长尾场景下的泛化能力至关重要。在真实数据的基础上,进一步引入合成数据进行微调,模型的最终平均准确率提升了3.2%。其中,可控性更强的程序化渲染数据在提升复杂交叉口和交通灯识别等任务上表现尤为突出,相较于仅使用T2I数据,F1分数分别提升了1.64%和2.14%。这表明,结合真实与合成数据的混合策略是解决长尾分布问题的有效途径。

4. 研究展望
未来的研究应进一步探索以数据为中心的优化策略。随着多模态大模型的持续发展,其性能的提升将越来越依赖于训练数据的质量、多样性和结构,而不仅仅是模型规模。因此,可扩展的场景生成、高效的数据利用以及对长尾场景的系统性覆盖,是推动自动驾驶系统走向可靠、大规模商业化应用的关键路径。
< Fin >


