









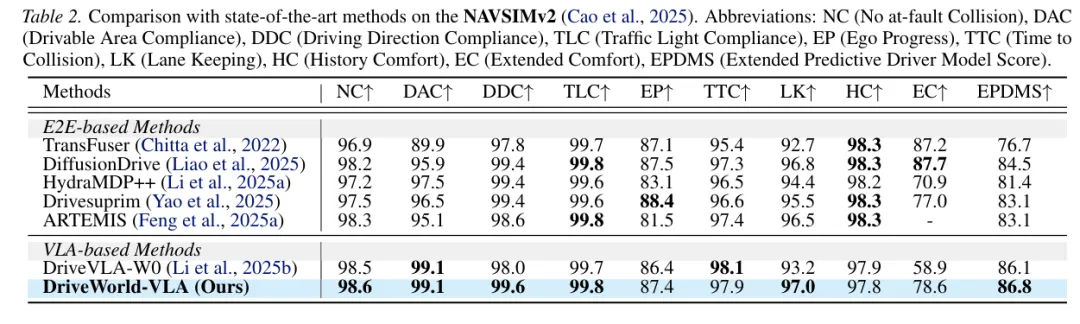
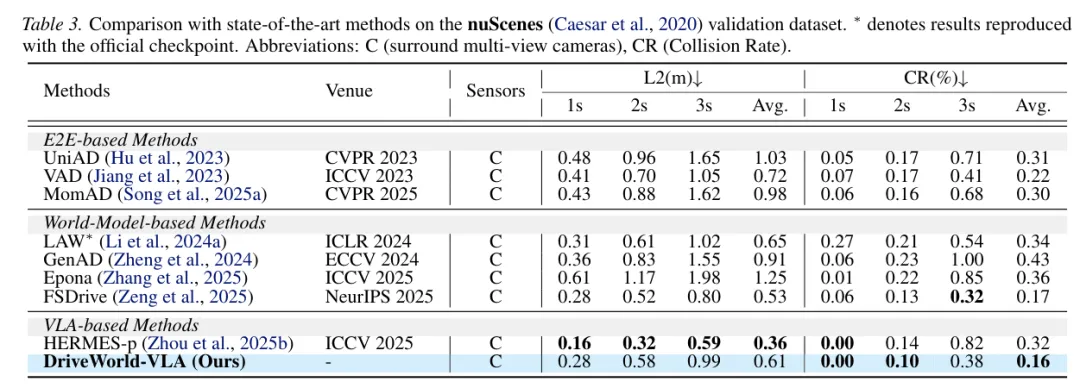
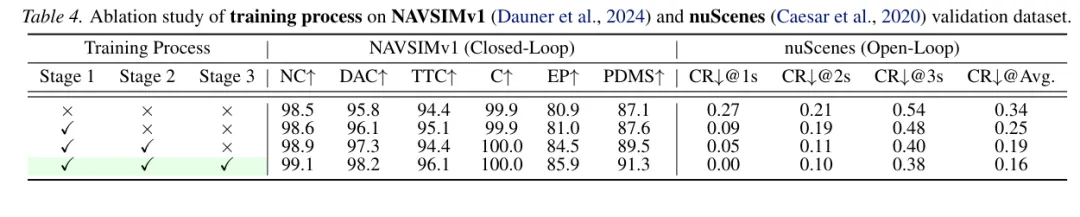
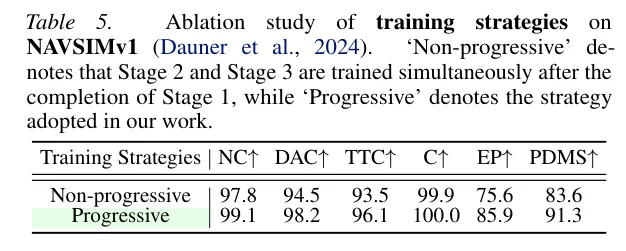


随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 跳过L3直接到L4,自动驾驶L3真的没必要吗?
- 20-30 万增程 SUV 大乱斗!智己 LS6 增程版硬刚理想 L6 / 问界 M7 / 哈弗猛龙 PLUS,谁是全域全能王?
- 2026年这5款家用SUV很香,但别只盯着“性价比”
- 2026款丰田汉兰达发布:家用SUV更会过日子了,但这几个点别急着上头
- 奇瑞一“大号SUV”来了,长得像路虎卫士+混动引擎,走平价路线!!!
- 司机招聘 丨 自动驾驶路线采集岗位,月薪6-7k*17薪+五险一金,上五休二,工作轻松,非网约车!
- 一分钟133台!这台国产增程SUV杀疯了,让BBA老车主排队下单?
- 2026年想买家用SUV,这3款思路完全不同,别光看谁名气大
- 清华大学(车辆国重)—小米汽车自动驾驶安全与智能联合研究中心成立仪式暨第一次管委会会议举行
- 2026年5款设计逆天的豪华SUV,谁真香,谁只是看着很贵
