盘点|从强化学习到端到端,自动驾驶领域最值得精读的 10 篇论文
- 2026-05-08 18:15:30

「自动驾驶的训练范式变了......」
近年来,自动驾驶技术正在经历一场深刻的范式变革。过去,我们习惯于将自动驾驶拆分为感知、预测、规划等多个独立模块,就像工厂流水线上的工人各司其职;而现在,端到端(End-to-End)架构如同一个拥有全局视角的“老司机”,直接从传感器输入映射到控制指令,大幅减少了模块间的信息折损。
与此同时,为了让这位“老司机”不仅能开,还能在复杂场景下开得更安全、更聪明,强化学习和多模态大模型(VLM/MLLM)正成为最强有力的训练引擎。
本文精心盘点了强化学习与端到端自动驾驶领域的 10 篇代表性论文。从奠定端到端基础的经典之作,到 2024-2025 年间引入世界模型、扩散生成与大语言模型的最新前沿,为你梳理出一条清晰的技术演进脉络。无论你是具身智能领域的初学者,还是深耕自动驾驶的资深算法工程师,这 10 篇论文都值得你加入必读清单。
说明: 这一领域优秀的工作远不止于此。受限于篇幅,本文仅选取了在技术路线上具有代表性、引用量较高或在近期引发广泛关注的 10 篇论文,力求覆盖不同技术方向。限于篇幅,其它同样出色的工作有些未能列入,绝非意味着它们价值不足。如果你有特别想看的论文,欢迎在评论区告诉我们!
早期的端到端模型往往像一个难以解释的“黑盒”。为了兼顾可解释性与端到端的性能优势,研究者们提出了统一的多任务框架和全矢量化表示,甚至开始尝试直接利用原始视频进行全局推理。
论文: Planning-oriented Autonomous Driving(CVPR 2023 Best Paper)
机构: 上海人工智能实验室、商汤科技等
推荐理由: 端到端自动驾驶的奠基之作,CVPR 2023 最佳论文,引用量超过 1500 次,是理解"以规划为核心"端到端范式的必读入门。
UniAD 是端到端自动驾驶领域的里程碑之作。过去的多任务学习往往止于感知层面,而 UniAD 首次将目标跟踪、地图在线生成、运动预测、占用预测以及最终的规划任务,统一到了一个以规划为导向(Planning-oriented)的 Transformer 框架中。模型中的各个模块通过统一的 Query 接口进行特征传递,不仅消除了级联误差,还能在发生规划失误时,清晰地追溯是哪个中间环节出了问题。
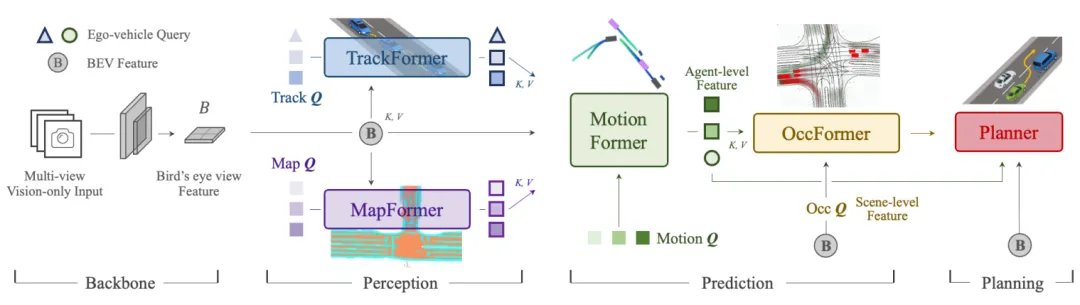
图1 | UniAD 整体框架:以规划为导向,将感知(目标跟踪、地图分割)、预测(运动预测、占用预测)与规划统一在一个端到端 Transformer 中。©【深蓝 AI】编译
论文: VAD: Vectorized Scene Representation for Efficient Autonomous Driving (ICCV 2023)
机构: 华中科技大学、地平线
推荐理由: 矢量化表示的开创性工作,ICCV 2023 发表,引用量超过 700 次,是工业界落地端到端方案时绕不开的参考基线。
传统的端到端模型高度依赖计算密集的鸟瞰图(BEV)光栅化特征,导致推理速度较慢。VAD 提出了一种全矢量化(Fully Vectorized)的场景表示方法。它摒弃了稠密的特征图,转而用矢量化的智能体查询(Agent Query)和地图查询(Map Query)来建模整个驾驶场景。这种极简的表示方式不仅大幅降低了计算开销,还通过引入矢量化运动约束显著提升了规划的安全性,非常适合工业界的车端部署。
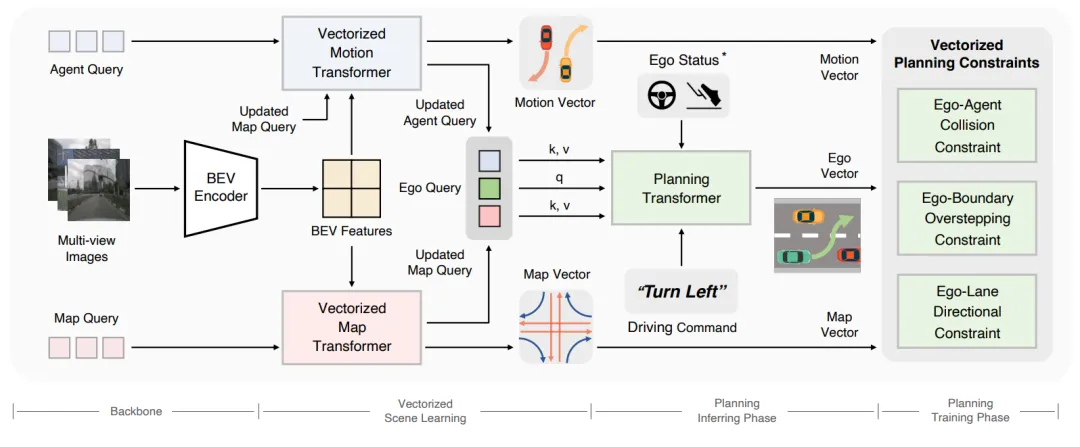
图2 | VAD 整体架构:将驾驶场景完全矢量化表示,通过智能体查询与地图查询交互完成规划,并引入三类矢量化规划约束保证安全性。©【深蓝 AI】编译
论文: End-to-End Multimodal Model for Autonomous Driving
机构: Waymo
推荐理由: 工业界最具代表性的"大模型接管驾驶"探索,来自 Waymo,展示了 MLLM 作为端到端驾驶核心的可行性,是理解大模型与自动驾驶融合趋势的重要窗口。
Waymo 提出的 EMMA 展示了端到端架构的另一种极致形态。它没有复杂的感知或预测子模块,而是直接将原始的摄像头视频和自然语言指令输入给多模态大模型(如 Gemini)。通过将驾驶任务转化为视觉问答(VQA)问题,EMMA 不仅能输出未来轨迹用于运动规划,还能同步输出 3D 目标检测和道路图估计结果。更重要的是,它具备了链式思维(CoT)推理能力,能用人类语言解释自己的驾驶决策。
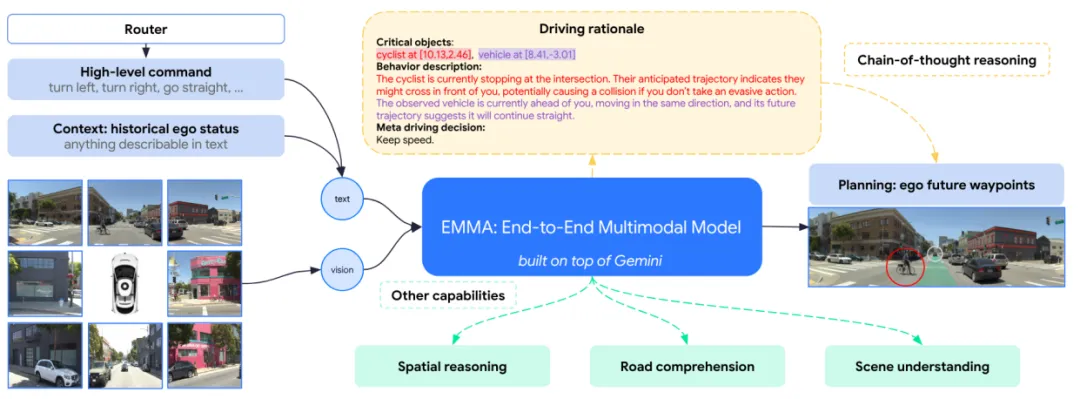
图3 | EMMA 系统概览:直接以原始摄像头视频为输入,通过多模态大模型生成驾驶决策与轨迹,无需中间表示,实现真正的端到端自动驾驶。©【深蓝 AI】编译
传统的模仿学习(Imitation Learning, IL)容易受到“协变量偏移”和长尾数据的困扰。为了让模型学会在未见过的场景中自我纠错,强化学习(RL)逐渐成为训练端到端规划器的核心利器。
论文: End-to-End Urban Driving by Imitating a Reinforcement Learning Coach (ICCV 2021)
机构: 苏黎世联邦理工学院 (ETH Zurich)
推荐理由: RL 师生范式的奠基工作,ICCV 2021 发表,引用量超过 500 次,是后续大量 CARLA 端到端方法的重要基线,读懂 Roach 才能读懂后续一系列 RL 驾驶工作。
在 CARLA 仿真器中直接训练基于视觉的 RL 智能体非常困难。Roach 提出了一种巧妙的“师生范式”:首先利用特权信息(如结构化的 BEV 语义掩码)训练一个强化学习专家(Coach);然后,通过知识蒸馏,让一个仅使用普通摄像头图像作为输入的模仿学习模型(Student)去学习专家的行为和特征表示。这种方法极大地提升了纯视觉端到端模型在复杂城市环境中的驾驶表现。
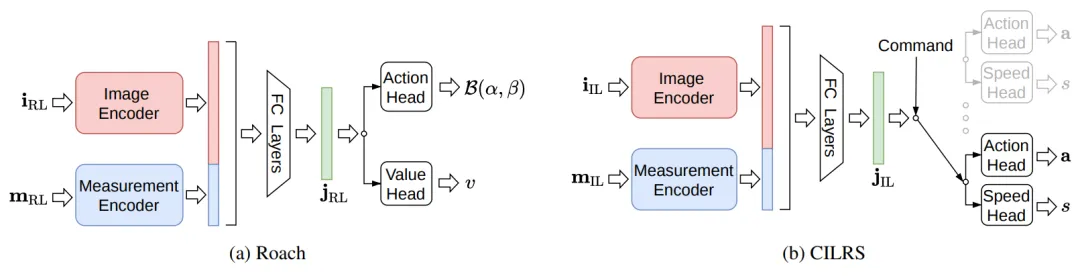
图4 | Roach 框架:左为强化学习专家(Roach),右为模仿学习学生(CILRS)。Roach 通过 BEV 特征训练 RL 策略,再将其知识蒸馏给仅使用摄像头输入的 IL 学生模型。©【深蓝 AI】编译
论文: Think2Drive: Efficient Reinforcement Learning by Thinking with Latent World Model for Autonomous Driving (ECCV 2024)
机构: 上海交通大学
推荐理由: 首个将模型基 RL 成功应用于 CARLA v2 复杂场景的工作,ECCV 2024 发表,将 RL 训练时间从数周压缩至 3 天,对想要在自动驾驶中落地 RL 的研究者极具参考价值。
在物理仿真器中进行 RL 训练耗时巨大。Think2Drive 首次将模型基强化学习(Model-based RL)成功应用于复杂的自动驾驶任务。它构建了一个紧凑的潜在世界模型(Latent World Model)来学习环境的转移规律。规划器不需要在缓慢的 CARLA 仿真器中不断试错,而是直接在世界模型“想象”出的潜在空间中进行高速推演和训练。这使得模型在短短 3 天内就能在单张 GPU 上完成训练,并攻克了 CARLA v2 中极具挑战性的长尾场景。
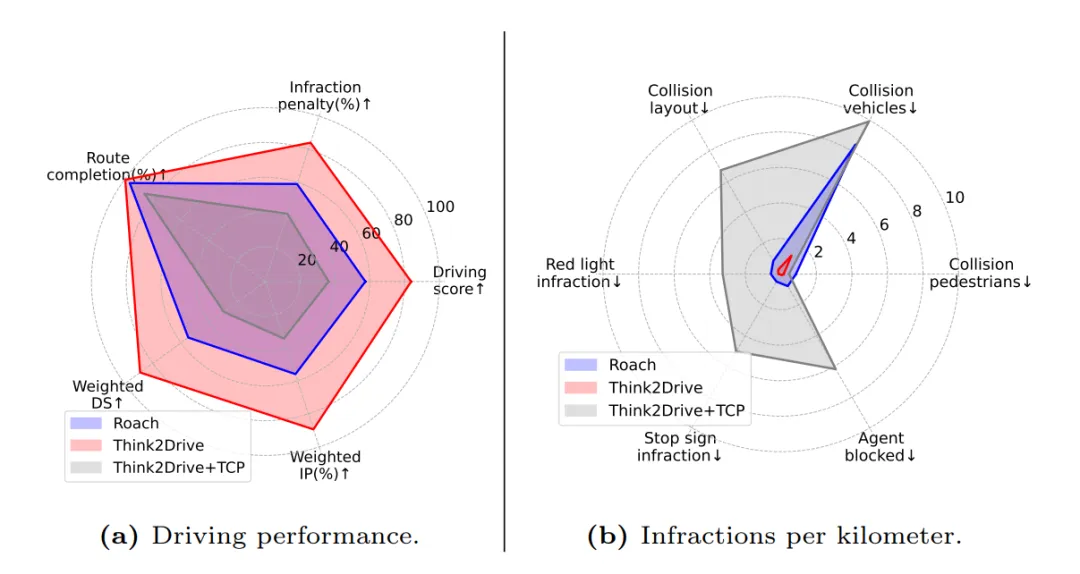
图5 | Think2Drive 在 CornerCaseRepo 基准上的驾驶表现:左图为综合驾驶得分雷达图,右图为每公里违规次数对比。Think2Drive(蓝色)在路线完成率、驾驶得分和违规控制上均显著优于无模型 RL 基线 Roach(红色)。©【深蓝 AI】编译
论文: RAD: Training an End-to-End Driving Policy via Large-Scale 3DGS-based Reinforcement Learning (NeurIPS 2025)
机构: 华中科技大学、地平线
推荐理由: 首个将 3DGS 光真实渲染与 RL 端到端训练结合的工作,NeurIPS 2025 发表,直接面向 Sim-to-Real 鸿沟这一核心挑战,代表了 RL 驾驶训练的最新方向。
尽管 RL 在 CARLA 中取得了成功,但仿真与现实之间的巨大鸿沟(Sim-to-Real Gap)依然存在。RAD 是首个在基于 3D 高斯溅射(3DGS)的光真实(Photorealistic)仿真环境中训练端到端自动驾驶智能体的工作。它采用三阶段训练范式:感知预训练、规划预训练,以及结合了模仿学习与强化学习的后训练(Reinforced Post-Training)。在高度逼真的渲染场景中,RAD 展现出了卓越的闭环驾驶能力,碰撞率大幅下降。
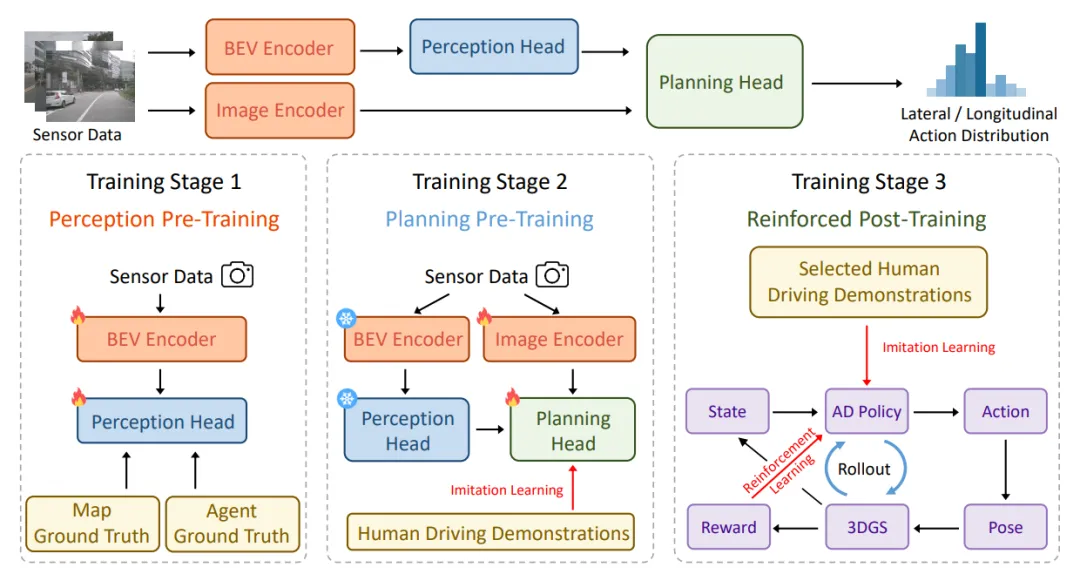
图6 | RAD 整体框架:采用三阶段训练范式,在感知与规划预训练后,通过 3DGS 光真实仿真环境进行强化学习后训练,实现 IL 与 RL 的协同优化。©【深蓝 AI】编译
当生成式 AI 遇到自动驾驶,扩散模型(Diffusion Models)开始被用于生成多样化的驾驶轨迹。结合强化学习的反馈机制,模型能够在多模态的未来预测中找到最优解。
论文: DiffusionDrive: Truncated Diffusion Model for End-to-End Autonomous Driving (CVPR 2025 Highlight)
机构: 华中科技大学、地平线
推荐理由: 扩散模型在端到端驾驶中的突破性应用,CVPR 2025 Highlight,在 nuScenes 上刷新了 SOTA,同时以 45 FPS 的实时速度证明了生成式规划的工程可行性。
传统的确定性模型在复杂路口容易出现"模式坍缩"(即只输出一种平均轨迹,导致碰撞)。DiffusionDrive 将扩散模型引入端到端规划,通过迭代去噪生成多样化的合理轨迹。为了解决扩散模型推理慢的致命弱点,作者提出了一种截断扩散策略(Truncated Diffusion):不再从纯随机噪声开始去噪,而是从基于先验知识的锚定高斯分布开始。这使得 DiffusionDrive 能够在保持多模态特性的同时,实现高达 45 FPS 的实时推理。
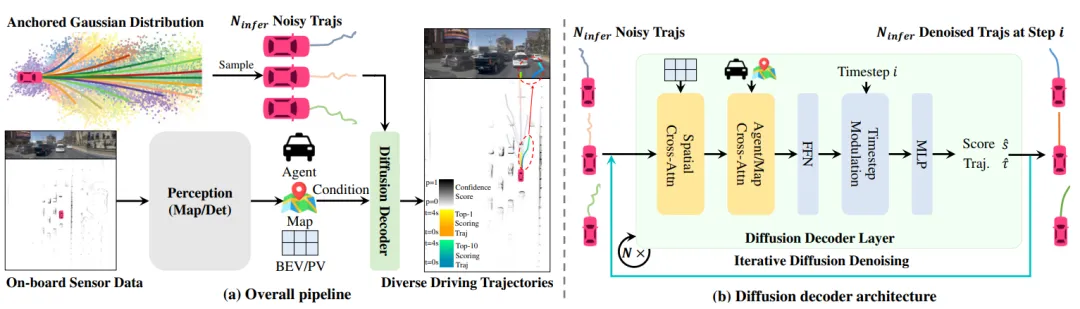
图7 | DiffusionDrive 整体架构:(a) 整体流水线将感知特征输入截断扩散解码器,生成多样化驾驶轨迹;(b) 扩散解码器通过锚定高斯分布截断去噪步骤,兼顾多模态性与实时性。©【深蓝 AI】编译
论文: Raw2Drive: Reinforcement Learning with Aligned World Models for End-to-End Autonomous Driving (NeurIPS 2025)
机构: 上海交通大学
推荐理由: 当前 CARLA Leaderboard v2 上唯一基于 RL 的端到端方法,NeurIPS 2025 发表,双流世界模型设计优雅,是研究"如何从原始视频做 RL 驾驶"的最新参考。
直接从高维的原始多视角视频中学习世界模型难度极大。Raw2Drive 提出了一种创新的双流架构:在训练阶段,利用结构化的特权输入(Privileged Input)训练一个特权世界模型,并以此为“导师”,通过 Rollout Guidance 和 Head Guidance 机制,引导基于原始传感器输入的世界模型进行学习。在推理时,系统完全抛弃特权信息,仅依赖摄像头视频即可实现高性能的端到端驾驶。
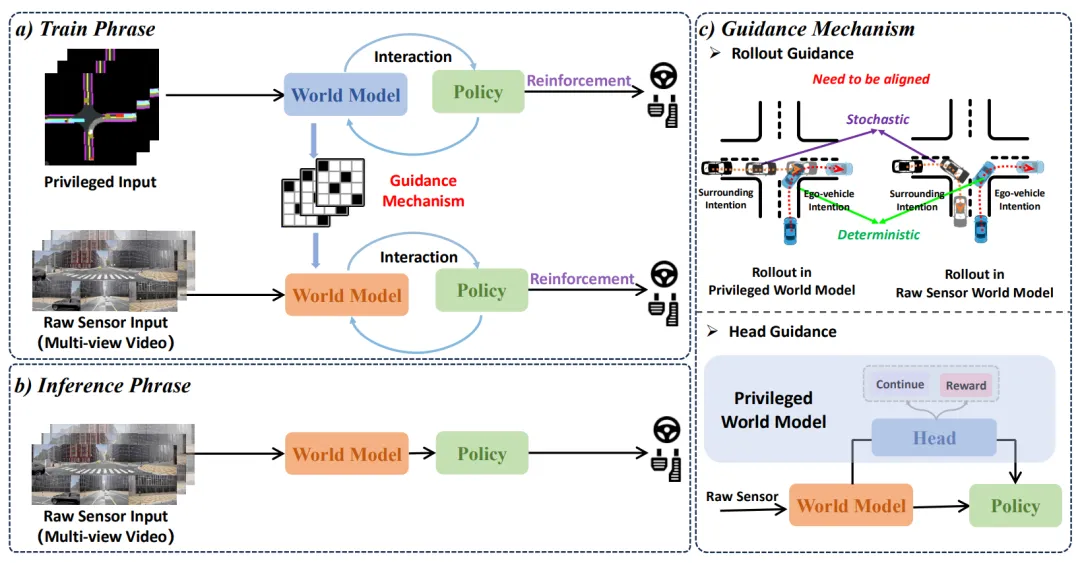
图8 | Raw2Drive 整体流程:训练时采用双流设计——特权流(结构化BEV输入)引导原始传感器流(多视角视频)的学习;推理时仅依赖原始传感器输入,实现真正的端到端强化学习。©【深蓝 AI】编译
视觉语言模型(VLM)强大的常识推理能力,正在填补传统端到端模型在应对罕见长尾场景(如施工引导、异形障碍物)时的逻辑空白。
论文: DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
机构: 清华大学 MARS Lab、理想汽车等
推荐理由: VLM 与自动驾驶融合的代表性工作,引用量超过 600 次,"快慢双系统"架构设计思路清晰,是理解大模型如何融入实时驾驶系统的绝佳入门读物。
DriveVLM 将大模型引入自动驾驶的规划核心。它模拟人类的认知过程,通过链式思维(CoT)依次进行场景描述、场景分析和层级规划。更有趣的是,为了弥补 VLM 在精确 3D 空间定位和高频实时计算上的不足,作者提出了 DriveVLM-Dual 混合架构:让 VLM 充当负责逻辑推理的“慢系统”,传统 3D 感知与规划模块充当负责瞬时反应的“快系统”,两者优势互补。
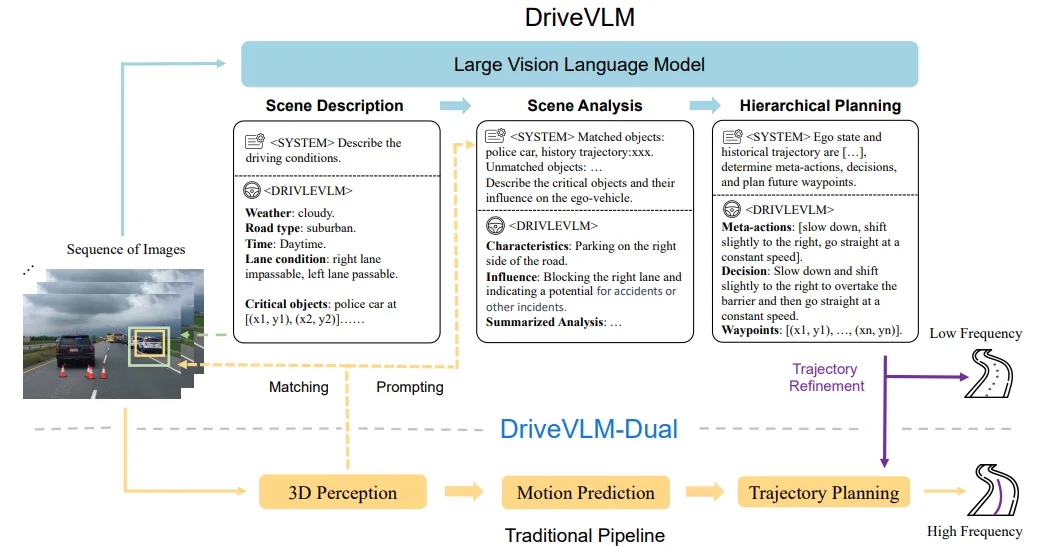
图9 | DriveVLM 系统框架:上方为 DriveVLM,通过链式思维(CoT)推理依次完成场景描述、场景分析与层级规划;下方为 DriveVLM-Dual,融合传统 3D 感知流水线以增强空间推理与实时性。©【深蓝 AI】编译
论文: DriveTransformer: Unified Transformer for Scalable End-to-End Autonomous Driving (ICLR 2025)
机构: 上海交通大学
推荐理由: ICLR 2025 发表,无 BEV 的并行端到端框架,在多个 benchmark 上达到 SOTA,架构设计极具前瞻性,代表了端到端系统走向大规模扩展的新方向。
现有的端到端框架大多依赖中间的 BEV 空间表示,不仅消耗内存,且各任务通常以串行方式执行。DriveTransformer 提出了一种无 BEV(BEV-free)的统一并行框架。所有任务(感知、预测、规划)的 Token 在 Transformer 层内同时进行自注意力交互,并直接通过交叉注意力从多视角图像中提取特征。这种流式并行的设计,结合稀疏表示,极大地提升了端到端系统的扩展性(Scalability)和运行效率。
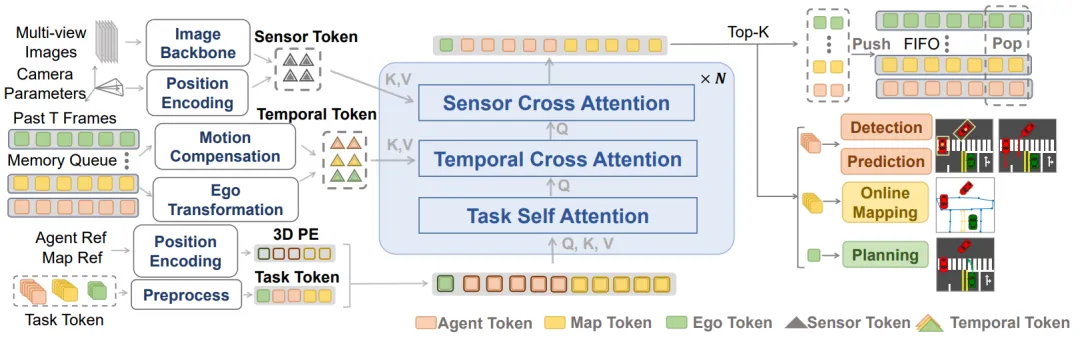
图10 | DriveTransformer 整体框架:所有任务的 Token(智能体、地图、自车)在每一层通过任务自注意力并行交互,通过传感器交叉注意力直接从原始图像提取信息,实现无 BEV 的高效端到端驾驶。©【深蓝 AI】编译
纵观这 10 篇文献,我们可以清晰地看到自动驾驶的演进轨迹:架构上,从多任务的显式级联(UniAD/VAD),走向彻底的无中间表示(EMMA/DriveTransformer);训练范式上,从被动的模仿学习,迈向基于世界模型和真实仿真的主动强化学习(Think2Drive/Raw2Drive/RAD);决策逻辑上,从单一的轨迹回归,进化为结合扩散模型的多模态生成(DiffusionDrive)和依赖 VLM 的常识推理(DriveVLM)。
在具身智能的大潮下,未来的自动驾驶汽车将越来越像一个具备完整“感知-认知-行动”闭环的智能机器人。强化学习赋予了它在未知中探索的勇气,而端到端与大模型则赋予了它全局的视野与人类般的智慧。
编辑|阿豹




· 计划周期:深蓝学院将以3个月为一个周期,建立工程师&学术研究者的「同好社群」
· 覆盖方向:自动驾驶、具身智能(人形、四足、轮式、机械臂)、视觉、无人机、大模型、医学人工智能……16个热门领域
扫码添加阿蓝
选择想要加入的交流群即可
(按照提交顺序邀请,请尽早选择)
👇

随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 定位五座中大型SUV 最大纯电续航751km 奥迪E7X将于5月8日预售
- 34万买黑武士SUV!林肯新车配三块超大屏,这配置让国产车看傻了?
- 斯柯达Epiq纯电杀入小型SUV战场!正面硬刚海豚与好猫, 还想抢ID.Polo的饭碗?
- 瑞虎7plus | A级SUV价值标杆,全面焕新家庭出行体验
- 在新能源狂卷的2026年,燃油SUV的二手性价比反而到了历史高点.
- 5.89万就能买SUV?这四款国产车空间大得离谱,一家五口坐进去都不挤!
- 杀疯了!丰田SUV从16万暴跌到9.98万,10气囊四轮独悬比国产还便宜!
- 他开着“自动驾驶”,在杭甬高速第一车道睡着了
- 重庆汽车员工分享,在自动驾驶带团队一年100多一点,得到了小公司算法负责人的职位150w做类似扫地机这类机器人,该去吗?
- 国标倒计时下的自动驾驶竞赛:华为遥遥领先,谁能追上?
