自动驾驶模型已经能够完成目标检测、场景理解与轨迹规划。然而,在复杂驾驶场景中,系统真正需要解决的并不只是“看见什么”,还包括“当前任务中哪些对象更值得优先处理”。
2026 年,npj Artificial Intelligence 发表文章 Human and algorithmic visual attention in driving tasks。该研究从人类眼动出发,比较驾驶员视觉注意与算法注意之间的差异,并进一步检验人类注意力能否提升自动驾驶模型在安全关键任务中的表现。
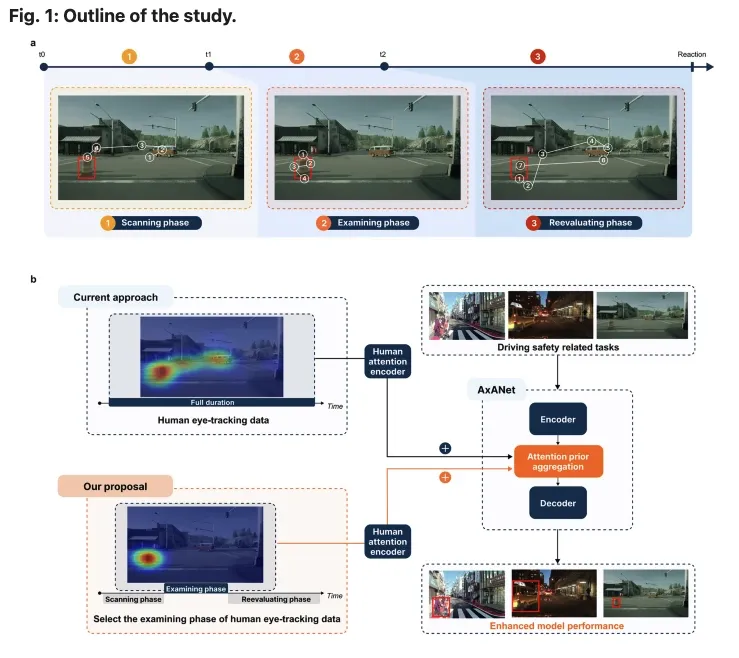
研究整体框架:作者将人类驾驶注意力划分为 scanning、examining 和 reevaluating 三个阶段,并比较不同阶段的人类注意力对自动驾驶模型的作用。来源:Zheng et al., 2026, npj Artificial Intelligence.
原文链接:
https://www.nature.com/articles/s44387-026-00079-1
文章将驾驶员的注视过程划分为三个阶段。
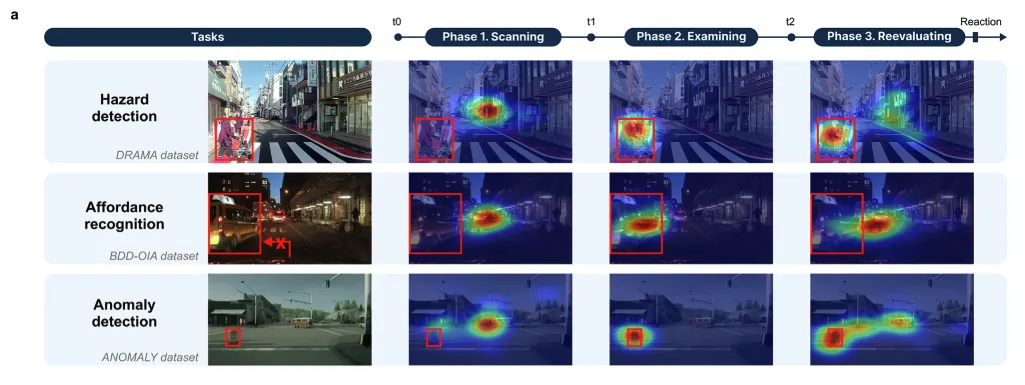
第一是 scanning phase,即初始搜索阶段。驾驶员在场景呈现后快速扫视环境,寻找潜在关键区域。
第二是 examining phase,即关键目标检查阶段。驾驶员已经定位到任务相关对象,并对其进行语义判断,例如该对象是否构成危险、是否影响变道或是否属于异常物体。
第三是 reevaluating phase,即再评估阶段。驾驶员在离开关键目标后继续观察其他区域,以修正或确认前一阶段的判断。
这一划分体现了文章的重要前提:眼动数据并非均质信号。不同阶段的注视行为对应不同认知过程,其对模型训练和性能提升的作用也不同。
人类驾驶注意力的三阶段:从场景出现到首次注视 AOI 为 scanning phase;从首次进入 AOI 到首次离开 AOI 为 examining phase;之后到作答为 reevaluating phase。
许多自动驾驶模型采用 attention 机制,尤其是基于 Transformer 的视觉模型。算法可以根据任务目标为图像区域分配权重,从形式上生成“注意力分布”。
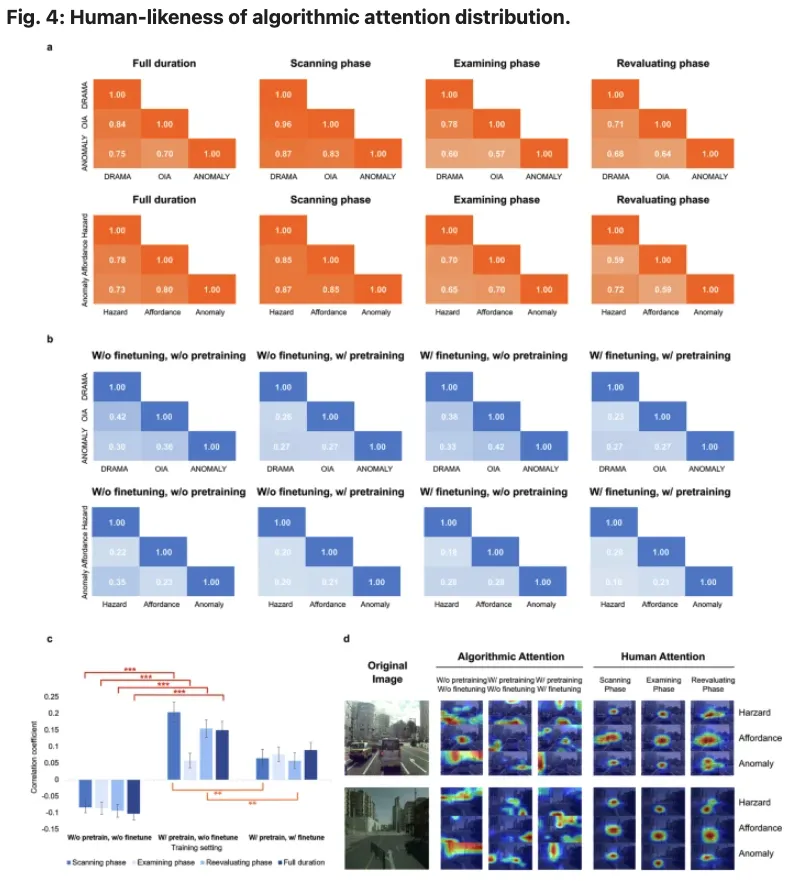
文章的实验表明,算法注意力与人类驾驶员注意力之间的一致性有限。模型可以学习到部分空间规律,例如道路中哪些区域更可能出现车辆、行人或潜在风险;但它较难自然形成类似人类 examining phase 的注意力模式。
这说明,模型的 attention 并不能直接等同于人类的任务相关视觉注意。算法能够识别对象,但在判断对象的任务重要性、风险含义和行为相关性方面仍存在不足。
研究进一步将不同阶段的人类注意力引入模型,并比较其对任务性能的影响。
结果显示,scanning phase 对模型的帮助有限,甚至可能降低性能。这一阶段包含大量搜索性注视,信息噪声较高。相比之下,examining phase 带来的提升更稳定,也优于直接使用完整注视轨迹。
这一结果提示,眼动数据的价值不在于覆盖范围,而在于是否包含任务相关语义。驾驶员对关键目标的持续注视,往往意味着该对象正在参与风险判断、通行性判断或异常判断。因此,examining phase 更接近一种人类语义注意力先验。
该研究并未要求自动驾驶系统在推理阶段持续采集真实眼动数据。
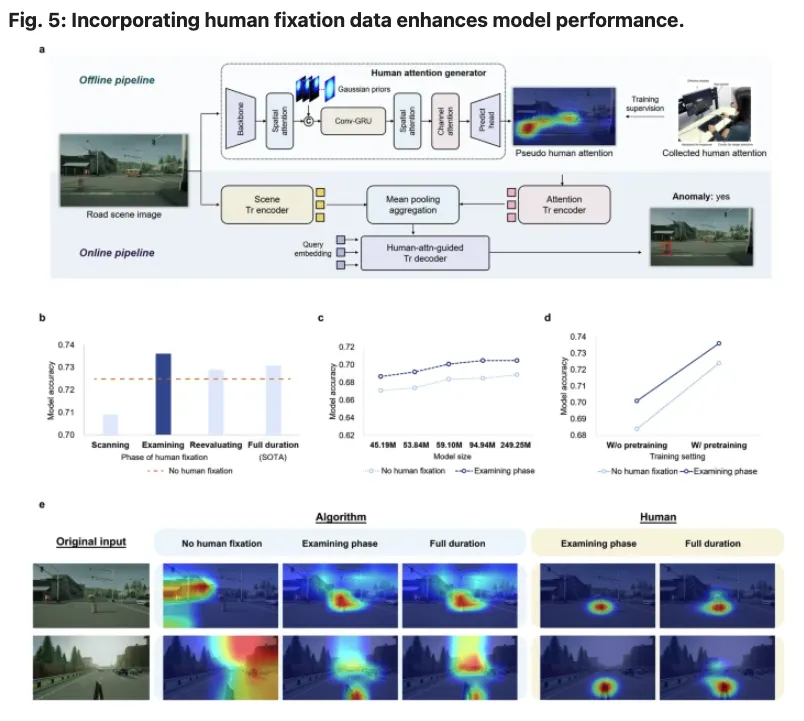
作者首先利用真实眼动数据训练 human attention generator,使其能够根据驾驶图像生成 pseudo human attention map。随后,主模型将这一伪人类注意力图作为辅助输入,用于检测、识别和规划等任务。
这种方法降低了实际应用门槛。真实眼动数据主要用于学习人类视觉注意规律,部署阶段则由模型生成注意力先验,从而避免对实时眼动仪的依赖。
a. AxANet 的算法架构。b .预训练 AxANet 与不同阶段的人类注视数据结合时的性能。c .非预训练 AxANet 在不同模型规模下,分别与人类注视数据(包括未结合注视数据和检查阶段)结合时的性能。d .预训练和未预训练 AxANet 与人类注视数据(包括未结合注视数据和检查阶段)结合时的性能。e . AxANet 与人类注视数据(包括未结合注视数据和检查阶段)结合时的注意力分布示例,以及原始输入上相应的人类注意力分布。
这篇文章的核心启发在于:驾驶员眼动可以被视为一种任务相关的语义注意信号。它记录了驾驶员在复杂交通场景中如何筛选关键对象,并将视觉关注转化为风险判断、通行判断和行为决策。
这一点对自动驾驶研究具有直接意义。现有模型已经能够识别车辆、行人和道路结构,但在判断“当前任务中哪个对象最关键”方面仍存在不足。人类注视行为可以为模型提供补充线索。例如,在汇入或变道场景中,驾驶员对主线后车、目标间隙、本车道前车的注视,分别可能对应让行判断、间隙评估和等待决策。
因此,眼动数据的研究重点应从热力图描述转向语义建模。后续研究需要建立“注视区域—任务语义—驾驶决策”之间的对应关系,使眼动数据能够服务于意图识别、风险解释和人机协同控制。
对于以人为中心的智能驾驶研究,这篇文章提供了一条清晰路径:利用人类视觉注意揭示驾驶员的场景理解过程,并将其转化为可训练、可解释、可迁移的模型先验。