蔚来采用 HAMi、NVIDIA MIG 与时间分片相结合的混合 GPU 共享策略,全面提升 CI、仿真和推理工作负载的 GPU 利用率——实现利用率 4 倍提升、GPU 机时减少 30%。
蔚来运营大规模云基础设施,支撑自动驾驶工作负载,涵盖模型训练、仿真、CI/测试及在线推理。团队专注于 GPU 性能优化,并参与 GPU 与计算资源的规划决策。
挑战
蔚来的大规模云基础设施支撑多种自动驾驶工作负载,包括训练、仿真、CI/测试和在线推理。团队负责 GPU 性能优化与资源规划。工作负载类型的多样性导致了因"工作负载—资源不匹配"而长期存在的效率问题。
GPU 利用率低的工作负载
CI 与测试任务
CI 任务的大部分执行时间花在编译、文件拉取和预处理等 CPU 密集型操作上。GPU 仅间歇性使用。在整卡分配模式下,平均 GPU 利用率通常仅为 5%–10%。
仿真工作负载
仿真管线处理视频流、雷达数据和推理验证。单个任务计算需求相对较低,且对延迟不敏感,适合在共享 GPU 上并发执行。
在线推理与小模型推理
许多推理服务仅需 1/4 或 1/2 张 GPU。分配整卡既低效又昂贵。
- • GPU 集群规模有限,部分容量来自公有云,采用按量计费模式。
- • 低 GPU 利用率导致GPU 机时浪费,直接推高运营成本。
- • 分配效率低下还会延长高优先级训练任务的排队等待时间。
蔚来需要一种在不牺牲工作负载稳定性的前提下提升 GPU 利用率的方案,同时支持在同一 Kubernetes 环境中运行多种类型的工作负载。
解决方案
蔚来采用了混合 GPU 共享策略,根据工作负载特征选择不同的 GPU 分配机制,而非强制使用单一方案。
下图展示了将 HAMi 集成到 Kubernetes 后的 GPU 管理架构。
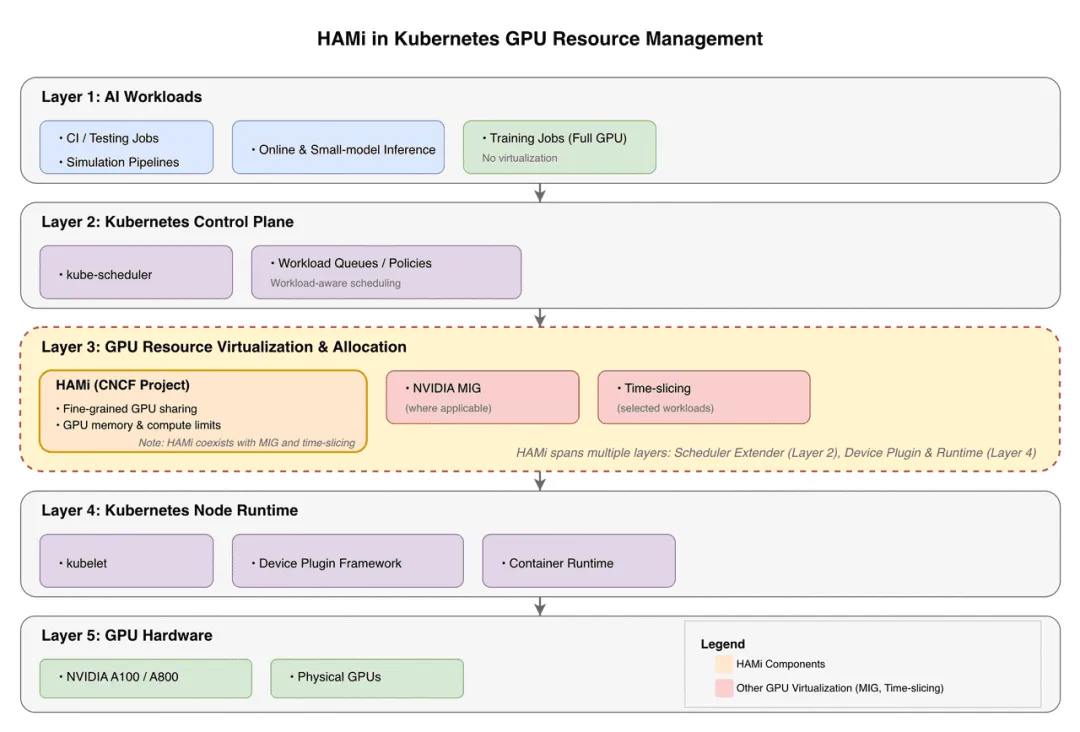 资源管理架构图
资源管理架构图HAMi 通过调度器扩展(第 2 层)和设备插件集成(第 4 层)为 Kubernetes 提供细粒度 GPU 共享能力,实现灵活的 GPU 资源分配,同时与 NVIDIA MIG 和时间分片策略共存。
评估的方案
NVIDIA MIG
提供强隔离,但仅支持预定义的分区大小,难以匹配更细粒度的需求(如 1/6 或 1/8 张 GPU)。
时间分片(Time-Slicing)
允许工作负载以极低开销自由竞争 GPU 资源。但缺乏对显存和计算用量的严格限制,不适合某些生产工作负载。
HAMi(CNCF Sandbox 项目)
支持对 GPU 显存和算力的精细控制,可根据实际工作负载需求按比例分配。相比整卡分配,该方法会引入一定开销。
生产策略
蔚来没有替换现有机制,而是将其组合使用:
- • HAMi: 用于 CI 任务及选定的推理和仿真工作负载
这种混合策略在保持正确性和运营安全的同时提升了 GPU 利用率。
实施情况
- • HAMi 部署在选定的 GPU 集群上,而非全部集群。
- • HAMi 主要覆盖适合 GPU 切片分配的工作负载。
部署规模:
- • 约 400–560 张 GPU(按每节点 8 卡计算)
资源分配设计
对于仿真工作负载,蔚来将 GPU 显存(VRAM) 视为主要约束:
- • 显存耗尽会立即导致 OOM 失败,无法延后处理。
团队还发现,切分粒度并非越细越好。对于某些仿真工作负载,分配约 1/6 张 GPU 时效率最优。更小的分片(如 1/8)会引入额外的调度和虚拟化开销,反而降低整体吞吐量。
成效
CI 工作负载:从浪费到复用
使用 HAMi 前:
CI 任务以 CPU 密集型为主,平均 GPU 利用率仅约 5%(5%–10%)。
使用 HAMi 后:
通过将 GPU 切分为 1/4 或更小分片,CI 管线中有效 GPU 利用率提升约 4 倍,达到 30%–50%。
仿真工作负载:更高吞吐、更少 GPU 机时
- • 细粒度 GPU 共享使总体 GPU 机时减少约 30%。
- • 原需 约 3 天 的端到端仿真任务缩短至 约 2 天。
这些改进提升了系统整体吞吐量,同时直接降低了 GPU 成本。
经验总结
GPU 分片并非"越细越好"。
每个工作负载都有最优分片大小。过度碎片化反而会降低效率。
版本升级需要进行性能验证。
新的 GPU 虚拟化组件可能引入性能回退。蔚来采用分阶段升级策略,在验证性能基准后才允许不同 HAMi 组件运行不同版本。
运营变更必须确保生产安全。
对于在线推理工作负载,设备插件升级遵循类似蓝绿部署的流程:先迁移流量,部署新 Pod,再逐步下线旧实例。
工具链兼容性至关重要。
某些编译器或库特性(如指针或地址分析)可能与 GPU 拦截机制冲突。需要在功能与稳定性之间谨慎权衡。
蔚来的 HAMi 部署实践证明,细粒度 GPU 共享可以显著提升自动驾驶工作负载的基础设施效率。通过将 HAMi 与 Kubernetes 以及 MIG、时间分片等现有 GPU 分配机制相结合,蔚来在保障稳定性的前提下提升了 GPU 利用率、减少了总体 GPU 机时并改善了工作负载吞吐量。
这种混合资源管理策略使蔚来能够在同一 Kubernetes 环境中更高效地支撑从 CI 管线到仿真和推理的多样化 AI 工作负载。



 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
