世界模型在自动驾驶中的应用:初探综述
标题:World Models for Autonomous Driving: An Initial Survey
作者:Yanchen Guan,Haicheng Liao,Zhenning Li,Jia Hu,Runze Yuan,Guohui Zhang,Chengzhong Xu
发表期刊:IEEE Transactions on Intelligent Vehicles
发表年份:2024年
关键词:World model,Autonomous driving,Foundational model,Model-based reinforcement learning
在快速发展的自动驾驶领域,准确预测未来事件并评估其影响的能力对于安全性和效率至关重要,它关键地助力了决策过程。世界模型已成为一种变革性方法,使自动驾驶系统能够综合和解读海量传感器数据,从而预测潜在未来情景并弥补信息差距。本文对世界模型在自动驾驶中的当前状态和未来展望进行了初步回顾,涵盖其理论基础、实际应用以及旨在克服现有局限的持续研究工作。通过强调世界模型在推动自动驾驶技术发展中的重要作用,本综述旨在作为研究界的基础参考,促进对这一新兴领域的快速理解和持续创新与探索。
开发能够无缝应对真实世界复杂场景的自动驾驶系统仍是当代技术的前沿挑战。这一挑战不仅是技术性的,也是哲学性的,它探索了区分人类智能与人工构建的认知和感知的本质。其关键在于赋予机器以人类轻松运用的直觉推理和常识。当前机器学习系统尽管能力强大,但往往在人类轻松解决的模式识别任务中失败,凸显了我们在追求真正自主系统方面的显著差距。另一方面,人类决策深深植根于感官知觉,受限于对这些知觉的记忆和直接观察。除了感知,人类还具备预测自身行为结果、设想潜在未来和预测感官输入变化的能力——这些能力支撑着我们与世界的互动。在机器中复制这些能力的努力不仅是工程挑战,更是弥合人类与机器智能之间认知鸿沟的一步。
为弥补这一差距,世界模型应运而生,为系统提供了通过模拟人类感知和决策过程来预测和适应动态环境的能力。世界模型的旅程从1970年代控制理论中的概念框架到当前人工智能研究中的突出地位,反映了技术演进和跨学科融合的显著轨迹。Ha和Schmidhuber于2018年正式提出世界模型,捕捉了AI研究社区赋予机器类似人类意识认知处理水平的共同愿望。通过利用混合密度网络和循环神经网络的强大能力,这项工作展示了无监督学习提取和解释环境数据中时空模式的道路。这一突破的重要性怎么强调都不为过——它证明了自主系统可以实现对其操作环境的细致理解,以前所未有的准确性预测未来情景。
在自动驾驶领域,世界模型的引入标志着向数据驱动智能的关键转变,预测和模拟未来情景的能力成为安全性和效率的基石。尤其是在BEV标注等专门任务中的数据稀缺挑战,突显了世界模型等创新解决方案的实践必要性。通过从历史数据生成预测情景,这些模型不仅规避了数据收集和标注带来的限制,还增强了自主系统在能够反映甚至超越真实世界复杂性的模拟环境中的训练。这种方法预示着一个新时代的到来,自动驾驶车辆具备了反映某种直觉形式的预测能力,使其能够以前所未有的精细化水平导航和响应环境。本文深入探讨了世界模型的复杂图景,探索了它们的基本原理、方法学进展以及在自动驾驶领域的实际应用,并展望了未来的研究轨迹和更广泛的含义。
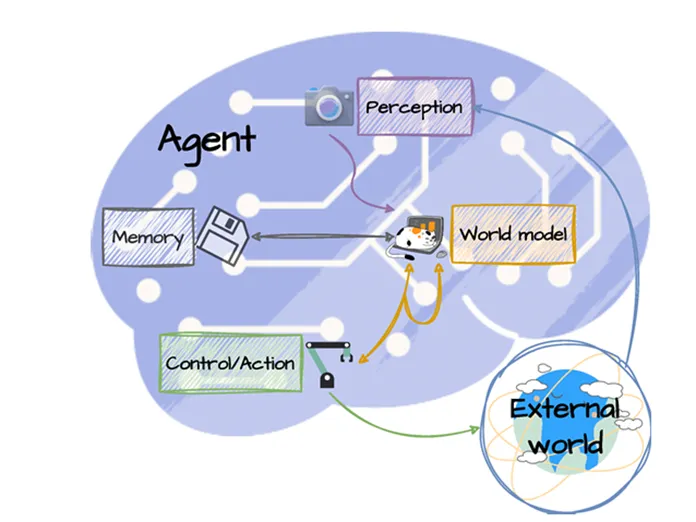
世界模型的架构旨在模拟人脑的连贯思维和决策过程。一个智能体的世界模型框架如图所示,它集成了几个关键组件:感知模块、记忆模块、控制/动作模块和世界模型模块。感知模块作为系统的感官输入,采用先进的传感器和编码器(如变分自编码器、掩码自编码器、离散自编码器等)将环境输入处理并压缩为更易于管理的格式。记忆模块类似于人脑的海马体,负责记录和管理过去、现在及预测的世界状态及其相关的成本或奖励,支持短期和长期记忆功能,通过回放近期经验来增强学习和适应能力。控制/动作模块直接负责通过动作与环境交互,评估当前状态和世界模型的预测,确定旨在实现特定目标(如最小化成本或最大化奖励)的最优动作序列。世界模型模块作为架构的核心,执行两个主要功能:估计当前世界状态中任何缺失的信息,以及预测环境的未来状态。这种双重能力使得系统能够生成其周围环境的全面预测模型,考虑不确定性和动态变化。
在高维感官输入场景中,世界模型利用潜在动态模型在潜在状态空间内抽象表示观测信息,使得能够进行紧凑的前向预测。这些潜在状态比高维数据的直接预测更节省空间,支持大量并行预测。例如,汽车在十字路口方向的不确定性是现实世界动力学内在不可预测性的典型情景,潜在变量成为表示这些不确定结果的强大工具,为世界模型设定了基于当前状态设想一系列未来可能性的舞台。这一努力的关键在于调和预测的确定性方面与现实世界现象的内在不确定性之间的平衡。
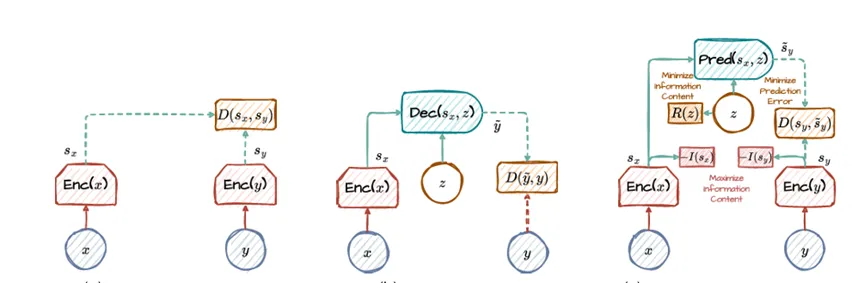
在世界模型研究中,最常采用的核心结构是循环状态空间模型(RSSM)和联合嵌入预测架构(JEPA)。RSSM是Dreamer系列世界模型中的关键模型,旨在仅在潜在空间内进行前向预测。如图3(原文Fig. 3)所示,RSSM的创新在于将状态策略性地分解为随机和确定性组件,有效利用了确定性元素的预测稳定性和随机元素的适应潜力。这种混合结构确保了鲁棒的学习和预测能力,适应现实世界动态的不可预测性,同时保持信息连续性。通过将RNN的优势与状态空间模型的灵活性相结合,RSSM建立了世界模型的全面框架。给定观测和动作序列:
,RSSM通过以下生成过程建模观测和状态转换:
近似后验定义为:
JEPA标志着预测建模的范式转变,聚焦于表示空间而非直接、详细的预测。如图所示,通过将输入x和目标y通过双编码器抽象为表示(sx和sy),并利用潜在变量z进行预测,JEPA在效率和准确性上实现了显著飞跃。JEPA的核心是能量函数,捕获模型内的预测误差,能量函数的数学表示如下:
平方L2范数测量目标表示与预测表示之间的欧氏距离,突出模型的预测误差;正则化项惩罚模型复杂性以防过拟合。优化过程旨在通过找到θ,Φ和z来最小化Ew,表示为带有数据分布约束的复杂拉格朗日优化问题。训练JEPA涉及更高阶优化方法,考虑二阶导数以确保复杂环境中的收敛。针对z的高维性质和可能的多峰分布,JEPA可能采用对难处理后验的变分近似,产生变分下界用于最大化ELBO以近似真实后验分布。
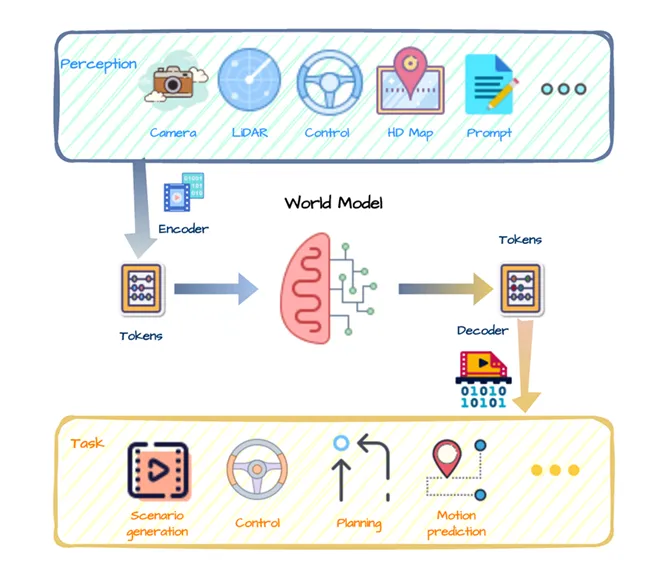
本节深入探讨世界模型在自动驾驶领域的变革性应用,强调它们对环境理解、动态预测和物理原理阐释的关键贡献。尽管兴趣日益增长,世界模型在自动驾驶中的集成主要围绕场景生成、规划与控制机制展开,这些领域充满探索和创新的空间,如图所示。
5.1场景生成
自动驾驶中的数据获取面临重大障碍,包括数据收集和标注的高成本、法律约束和安全性考虑。世界模型通过自监督学习范式,提供了从大量未标注数据中提取有价值见解的有前景解决方案,从而成本有效地增强模型性能。世界模型在驾驶场景生成中的应用尤为值得关注,因为它促进了多样化且真实的驾驶环境的创建,大大丰富了训练数据集,使自主系统具备应对罕见且复杂驾驶场景的鲁棒性。
GAIA-1是一种新颖的自主生成AI模型,能够使用视频、文本和动作输入创建真实的驾驶视频。通过在Wayve的英国城市大规模真实世界驾驶数据上训练,GAIA-1学习并理解驾驶场景中的一些真实世界规则和关键概念,包括不同类型的车辆、行人、建筑和基础设施。它能够基于几秒钟的视频输入预测和生成后续驾驶场景。值得注意的是,生成的未来驾驶场景与提示视频并非紧密关联,而是基于GAIA-1对世界规则的理解。GAIA-1以自回归Transformer网络为核心,根据输入图像、文本和动作令牌预测即将到来的图像令牌,然后将这些预测解码回像素空间。GAIA-1可以预测多种潜在的未来,并根据提示生成多样化的视频或特定驾驶场景,甚至包括超出其训练集的动作和场景。这展示了其理解并推断训练集中不存在的驾驶概念的能力,也证明了其反事实推理的能力。在现实世界中,由于风险性,这类驾驶行为很难获取数据。驾驶场景生成允许进行模拟测试,丰富数据组成,增强系统在复杂场景中的能力,并更好地评估现有驾驶模型。
DriveDreamer是另一个基于世界模型的驾驶视频生成框架。它利用扩散模型生成符合交通规则和物理约束的高质量驾驶视频,并允许通过文本描述或布局进行条件化控制。Adriver-I结合多模态大语言模型和视频扩散模型,构建了一个通用世界模型,能够从图像-文本对中学习并生成连贯的驾驶场景。这些模型在nuScenes数据集上使用FID和FVD作为评估视频质量的指标,其中Adriver-I在视频质量上优于DriveDreamer和Drive-WM。
5.2规划与控制
在世界模型的驱动下,自动驾驶的规划与控制是另一个显著进展。传统基于RL的自动驾驶方法通常需要大量交互来学习策略,而世界模型通过学习环境的潜在动态来加速规划过程。MILE是一种基于模型的模仿学习方法,用于城市驾驶中的联合策略学习。通过在CARLA模拟器中以结构化潜空间进行规划,MILE显著优于最先进的模型,将驾驶评分从46提高到61。SEM2在RSSM基础上引入语义掩码世界模型,以增强端到端自动驾驶的采样效率和鲁棒性。通过引入签名滤波器提取关键任务特征,并使用语义掩码重建这些特征,SEM2在CARLA中的性能相对于DreamerV2大幅提升。
考虑到大多数自动驾驶车辆通常配备多个摄像头,多视角建模也是世界模型的关键方面。Drive-WM是首个为增强端到端自动驾驶规划安全性而设计的多视角世界模型。通过多视角和时间建模,Drive-WM联合生成多个视角的帧,然后从相邻视角预测中间视角,显著提高了多视角之间的一致性。Drive-WM在nuScenes数据集上通过采样预测候选轨迹并使用基于图像的奖励函数选择最佳轨迹。值得注意的是,与GAIA-1一致,Drive-WM在非可行驶区域中的导航能力展示了世界模型在处理域外案例方面的理解和潜力。UniWorld采用创新方法,利用多帧点云融合作为生成4D占用标签的真实标签,通过利用未标注的图像-激光雷达对进行世界模型预训练,显著增强了对环境动态的理解。在nuScenes数据集上,UniWorld在运动预测和语义场景完成等任务中展现出比单目预训练方法更显著的IoU改进。TrafficBots通过条件变分自编码器为每个智能体学习不同的个性,从而在BEV视角下促进动作预测,展示了闭循环策略在动作预测中的潜力。
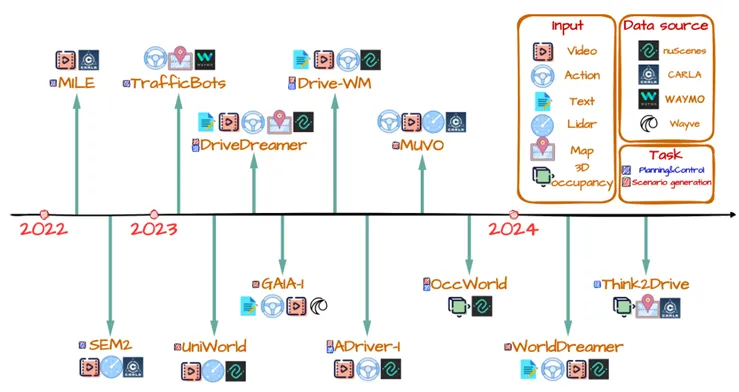
图中展示了自动驾驶领域现有世界模型的时间线概览,包括输入、任务和训练数据集。由于在自动驾驶领域应用世界模型仍是一个新兴课题,不同世界模型的操作任务和输入输出机制差异很大。在场景生成领域,不仅包括预测场景视频的生成,还包括场景信息补全和3D占用预测等细分领域。在控制领域,涉及基于传感器输入的自动驾驶、基于提示词的车辆控制等。此外,它还可以与场景生成集成,输出与控制信息对应的预测场景,从而为提高自动驾驶系统的可解释性提供了一条途径。由于任务、验证数据集和性能衡量标准的差异,比较不同世界模型的性能面临诸多挑战。对于使用nuScenes数据集进行场景视频生成的世界模型,采用FID和FVD作为评估视频质量的指标,较低分数表示更高的相似度和更好的模型性能。根据比较结果,Adriver-I的视频质量优于DriveWM和DriveDreamer。对于其他世界模型,尽管由于任务和性能指标的多样性而无法进行直接横向比较,但它们在其任务中相对于传统方法已取得了最先进的结果。
世界模型在自动驾驶领域的发展呈现出一个创新前沿,有潜力重新定义车辆移动性。然而,这一充满希望的图景并非没有挑战。解决这些障碍并探索未来视角需要深入探讨技术复杂性和更广泛的社会影响。
在技术和计算挑战方面,长期可扩展记忆集成、仿真到真实世界的泛化以及理论和硬件突破是关键问题。当前模型面临梯度消失和灾难性遗忘等问题,严重限制了其长期记忆能力。Transformer架构尽管通过自注意力机制促进了历史数据的访问,但在处理长序列时仍遭遇可扩展性和速度障碍。S4WM在高达500步的序列上展示了优于传统架构的高质量生成性能,但在1000步以上的性能下降凸显了人工与生物记忆系统能力之间的现有差距。仿真与现实之间的差异是自动驾驶技术演进的关键瓶颈,需要对模拟技术进行精炼以更准确地捕捉现实世界环境的细微差别和不可预测性。世界模型目前在生成任务上比纯预测任务表现更好,部分原因是这些模型仍未能完美模仿现实世界的演化,包括确定性和随机性之间的平衡。此外,经过传感器和编码器处理后进入潜在空间的信息相比现实世界失去了大量细节,这为模型的预测能力造成了瓶颈。
在伦理和安全挑战方面,决策问责制、隐私和数据完整性以及责任与标准是核心关切。确保车辆自主决策框架内的问责制是一项至关重要的伦理问题,需要开发具有无与伦比透明度水平的系统。将可解释人工智能原则直接整合到世界模型开发中至关重要。数据隐私和安全问题也因自动驾驶技术依赖大规模数据集而凸显。需要建立严格的数据治理政策,采用先进的网络安全措施,并与用户透明沟通数据使用方式。随着世界模型在自动驾驶系统中支持或接管驾驶任务,人类责任并未减少或消除,而是在参与其创建、部署和使用的个人和组织网络中重新分配。政策制定者应与研究人员、制造商和部署者合作,为事故责任建立明确公平的法律规则。
未来视角包括弥合人类直觉与人工智能精度之间的差距——发展世界模型以促进自动驾驶车辆内的认知协同驾驶框架。通过利用先进的世界模型,车辆可以获得前所未有的环境意识和预测能力,镜像人类认知过程,如预期、直觉以及在复杂社会技术环境中导航的能力。另一个愿景涉及世界模型将自动驾驶车辆转变为生态工程主体的作用,通过适应性的、响应性的行为与城市生态系统协调,为环境可持续性做出贡献。全球调查显示,超过60%的受访者认为随着城市系统自动化的发展,交通系统产生的污染和车辆碰撞的可能性将减少,超过70%的人预期交通噪音将改善。世界模型是实现车辆和交通系统更高自动化程度的关键发展方向,展示了它们在推进城市基础设施走向更安全、更可持续未来方面的重要性。


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
