基于认知表示对齐的知识驱动型自动驾驶泛化决策框架
标题: A knowledge-driven, generalizable decision-making framework for autonomous driving via cognitive representation alignment
作者: Hongliang Lu、Junjie Yang、Meixin Zhu、Chao Lu、Xianda Chen、Xinhu Zheng和Hai Yang
发表期刊: ransportation Research Part C: Emerging Technologies
发表日期: 2025年
该文主要面向自动驾驶决策问题,提出了一种知识驱动且具有泛化能力的自动驾驶决策框架,称为Cognitive Representation Alignment,简称CRA
本文围绕自动驾驶决策中的知识迁移问题展开研究。作者认为,若想使自动驾驶系统像人类驾驶员一样具备较强的泛化能力,就需要回答知识迁移中的三个核心问题:迁移什么知识、如何迁移知识、迁移哪一种知识。针对这三个问题,文章提出了认知表示对齐框架CRA。其中,预测地图predictive map被作为一种符合人类认知机制的知识驱动基础,用于回答“迁移什么”和“如何迁移”;而图表示与最短路径图核SPGK被用于衡量实时交通场景与预设典型场景之间的相似性,从而回答“迁移哪一种知识”。
在具体实现中,作者首先预先构建若干典型驾驶场景,并从这些场景中提取知识,形成一个知识库。当自动驾驶车辆处于实时交通场景中时,系统会将实时场景与知识库中的典型场景进行相似性匹配,然后根据相似性权重融合不同知识,生成与当前场景相匹配的对齐后继矩阵,进一步计算决策信念,最后辅助轨迹选择和驾驶决策。实验部分基于Common Road真实交通场景仿真平台,选取500个测试场景进行验证。结果表明,该框架可以提高自动驾驶车辆的安全性、通行能力、舒适性和泛化能力。
自动驾驶系统通常包含感知、预测、决策、规划和控制等模块,其中决策模块的核心作用是根据当前交通环境生成合理的行为策略。已有自动驾驶决策方法大致可以分为两类:一类是基于规则的方法,即通过人工设定规则、逻辑判断或模糊规则来决定车辆行为;另一类是基于学习的方法,如强化学习方法,通过大量训练经验获得行为策略。然而,作者指出,无论是规则驱动还是学习驱动,都面临一个共同问题:现实交通场景数量几乎无限,有限的规则或有限的训练经验不可能覆盖所有情况,因此直接依赖规则堆叠或数据堆叠难以保证自动驾驶系统在未知场景中的可靠性。
为了解决这一问题,本文引入了知识驱动的思想。与单纯依赖数据经验不同,知识驱动方法强调从已有场景中提取可复用的共性知识,并在新场景中进行迁移和重用。作者认为,人类驾驶员并不需要经历所有交通情境才能做出合理决策,而是能够基于已有经验和认知结构对新场景进行理解和判断。因此,自动驾驶决策系统也应当具备类似的知识迁移能力。
文中进一步指出,知识迁移的关键并不只是“有知识”,而是要明确三个问题:第一,什么可以作为知识被迁移;第二,知识如何作用于新场景;第三,在多个已有知识中,当前场景应该选择或融合哪一种知识。针对这三个问题,本文提出CRA框架,通过预测地图描述可迁移知识,通过图表示和最短路径图核计算场景相似性,并通过表示对齐实现知识融合。
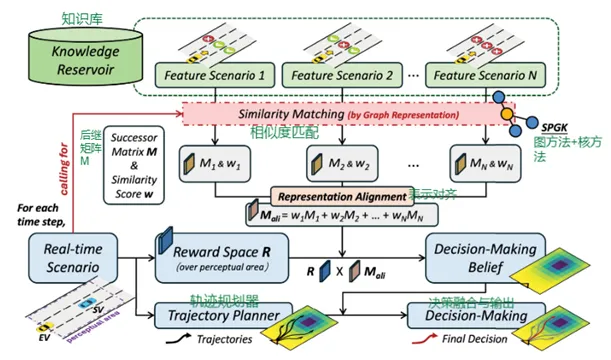
本文方法的核心是CRA,即认知表示对齐。如上图所示为CRA的完整框架图,图的其中上半部分是基于图表示的相似性匹配,下半部分是基于预测地图的知识迁移和决策信念生成。该图展示了整体流程为先构建知识库,再对实时场景进行图表示,然后利用SPGK计算实时场景与知识库中典型场景的相似性,接着根据相似性权重融合不同后继矩阵,最终生成决策信念并指导车辆选择最优轨迹。
1.场景图表示
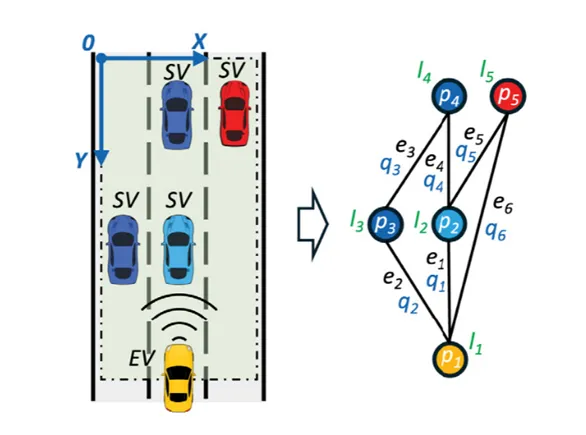
为了对交通场景进行可计算描述,作者使用图结构表示驾驶环境。上图展示了图表示的构建过程:自车EV和周围社会车辆SV被看作图中的节点,车辆之间的直接或间接交互关系被看作边。自车周围的感知区域被设定为一个局部坐标空间,车辆位置作为节点属性,车辆之间距离的倒数作为边属性,用来反映车辆间交互强度。
节点集合可以表示为:
其中,p1通常表示自车节点,其他节点表示周围社会车辆。每个节点的属性由车辆位置坐标表示:
边的属性用于描述两个车辆之间的交互强弱,定义为两节点之间欧氏距离的倒数:
该公式表明,两车距离越近,qij越大,说明交互关系越强;两车距离越远,交互关系越弱。这样,复杂交通场景就可以转化为图结构G,便于后续进行相似性计算。
2.预测地图与后续矩阵
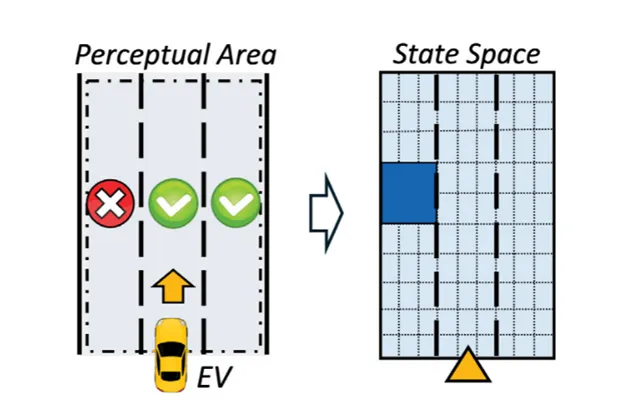
本文将预测地图作为知识驱动决策的基础。预测地图的核心思想是:智能体并不只关注当前状态的即时奖励,还会根据状态转移关系预测未来可能访问的状态。因此,文中将交通场景离散化为状态空间,每个状态表示感知区域中的一个格点,状态可达性用于描述该位置是否可以通行。上图展示了一个典型特征场景的状态空间构建过程,其中浅蓝区域表示可达状态,深蓝区域表示不可达状态。
状态可表示为:
其中,xs和xy分别代表状态在纵向和横向方向上的位置。为了描述不同状态之间的未来访问关系,作者引入后继矩阵M,其形式为:
其中,M(sa,sb)表示从状态出发,未来访问状态的折扣访问频率。该矩阵可以理解为从某一交通场景中提取出来的“可迁移知识”。
后继矩阵的理论定义为:
其中,γ为折扣因子,Ω是指示函数,当未来时刻的状态等于时取1,否则取0。该公式说明,后继矩阵记录的是从当前状态出发后未来可能访问其他状态的程度。
在已知状态转移矩阵T的情况下,后继矩阵可以通过几何级数形式计算:
这一公式是本文方法中的关键公式之一。它说明,只要知道状态之间的转移关系,就可以计算出该场景下的后继矩阵,并将其作为知识存入知识库。
3.知识库构建
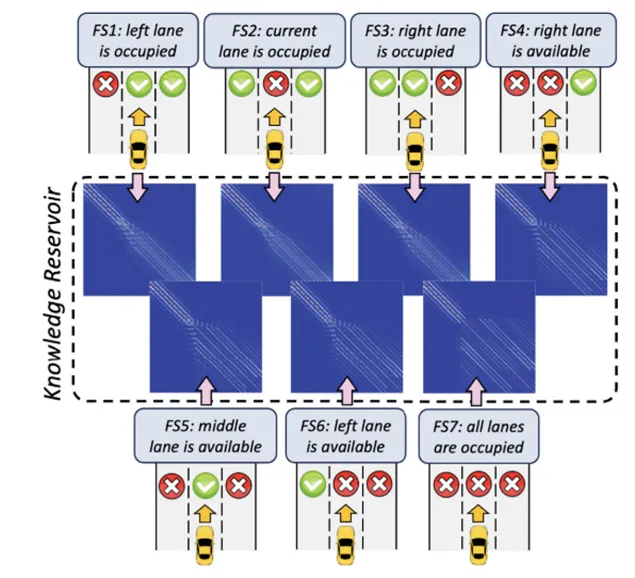
本文构建了7种典型驾驶场景作为知识库,分别对应不同车道可用性情况,例如左车道被占用、当前车道被占用、右车道被占用、右车道可用、中间车道可用、左车道可用以及所有车道均被占用。上图展示了这7种特征场景及其对应生成的知识,即不同的后继矩阵热力图。不同热力图形态反映了不同场景下状态转移关系的差异。
这部分的意义在于,作者不是让车辆每次都从零开始理解交通环境,而是提前把典型场景中的结构性知识存储起来。当实时场景出现时,系统只需要判断当前场景与哪些典型场景更相似,再调用相应知识进行决策。
4.表示对齐与相似性计算
为了判断当前实时场景应该迁移哪一种知识,作者使用最短路径图核SPGK计算实时场景图与知识库中特征场景图之间的相似性。其基本过程是先计算图中节点之间的最短路径,再将这些路径信息向量化,形成特征向量,然后计算两个图特征向量之间的相似性。如下图所示文献中给出了基于贪心思想的最短路径计算伪代码。
两个图特征向量的相似性由高斯函数计算:
其中,w表示相似性得分,γ为高斯函数参数。两个场景越相似,特征向量差异越小,得到的w值越大。
当实时场景Gt与7个特征场景的相似性分数分别为
时,系统根据相似性权重融合7个后继矩阵,得到对齐后的后继矩阵:
该公式是本文CRA框架的核心。它说明当前场景并不是简单调用某一个固定知识,而是根据相似性对多个知识进行加权融合,从而生成更适合实时场景的知识表示。
5.决策信念生成
在获得对齐后继矩阵后,系统还需要构建当前实时场景的奖励空间。文中将感知区域离散为21×9的状态空间,若某位置被社会车辆占据,则奖励值为-1;若该位置可通行,则奖励值为0。随后,利用后继矩阵与奖励空间计算决策信念:
其中,V(s)表示当前状态s的决策信念值。该值可以理解为车辆对不同位置或轨迹安全性、可通行性的综合判断。最后,系统采用贪心策略,从候选轨迹中选择累计信念值最大的轨迹作为最终决策结果。
本文实验主要分为三个部分:第一,验证对齐后继矩阵是否能够有效近似理论后继矩阵;第二,将CRA与其他先进自动驾驶决策方法进行对比;第三,比较WithAlignment与WithoutAlignment,验证表示对齐对决策性能的影响。实验平台选用CommonRoad,该平台包含大量由真实交通日志驱动的仿真场景。作者共选取500个测试场景,涵盖T字路口、交叉路口、高速公路和汇入场景四类。
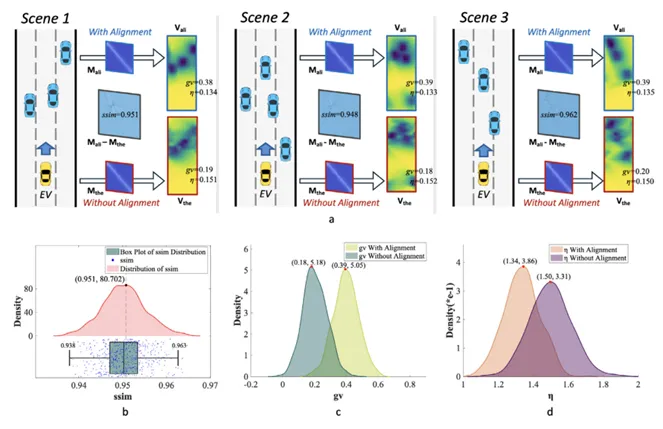
1.对齐知识有效性验证
在第一组实验中,作者使用400个静态交通场景验证对齐后继矩阵的有效性。评价指标包括结构相似性指数ssim、梯度方差gv和噪声指标η。其中,ssim用于衡量与理论后继矩阵的结构相似性;gv用于衡量决策信念中障碍物区域与自由区域的区分清晰度;η用于衡量决策信念中的噪声大小。上图展示了三组场景中的后继矩阵生成过程以及400个场景上的统计结果。实验结果显示,值集中在0.951左右,说明对齐后继矩阵与理论后继矩阵具有较高相似性;同时,WithAlignment的gv值更高、值更低,说明表示对齐能够增强障碍物与可通行区域的区分,并降低随机噪声。
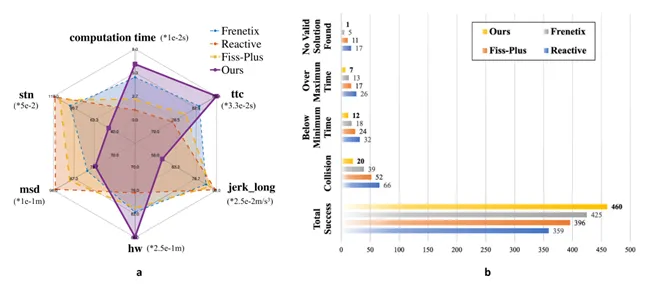
2.与其他方法对比实验
第二组实验将CRA与Common Road中的三种先进方法进行比较,包括Reactive、Fiss-Plus和Frenetix。上图展示了CRA在计算时间、碰撞时间TTC、纵向冲击jerk、车头间距headway、最小停车距离MSD和最大转向威胁数STN等指标上的对比结果。结果表明,CRA在ttc、jerklong、hw、msd和stn等指标上表现最好,说明该方法在安全性和舒适性方面具有优势。与Frenetix和Fiss-Plus相比,CRA在ttc、hw、msd上约有10%的提升;在jerklong和stn上提升更明显。不过,CRA由于需要进行知识匹配和表示对齐,计算时间从Frenetix的约48ms增加到约63ms,这说明方法在性能提升的同时也带来了一定计算开销。
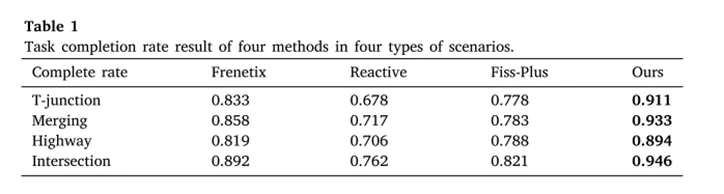
上表给出了四类场景中的任务完成率。从表中可以看出,CRA在四类场景中的任务完成率均最高,分别达到91.1%、93.3%、89.4%和94.6%。其中,高速场景中的完成率相对较低,作者认为这是因为高速场景中社会车辆数量更多,交互更复杂,但即便如此,CRA仍然优于其他三种方法,说明其具备较强的场景泛化能力。
3.表示对齐模块有效性验证
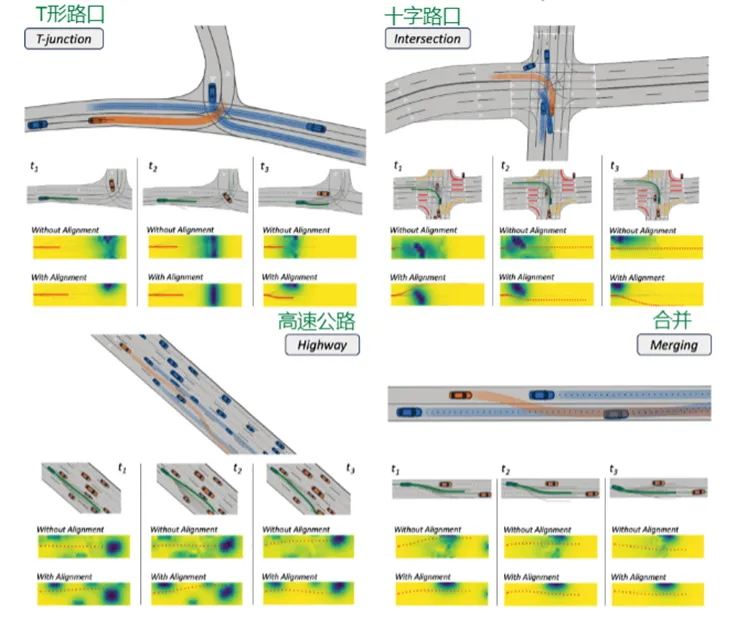
第三组实验重点比较With Alignment与Without Alignment,即验证CRA中表示对齐模块是否真的发挥作用。上图展示了T字路口、交叉路口、高速和汇入四类典型场景下,不同时刻的决策信念和决策结果。结果显示,没有表示对齐时,决策信念中容易出现碎片化噪声,原因是实时场景与被调用知识之间存在不匹配;而加入表示对齐后,系统能够得到更加清晰、连续和可靠的决策信念,尤其在交通密集或交互较强的场景中优势更加明显。
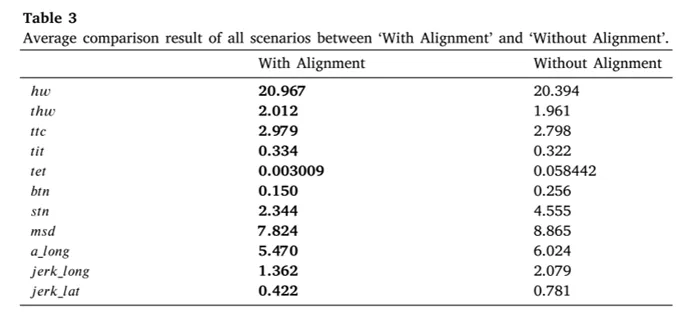
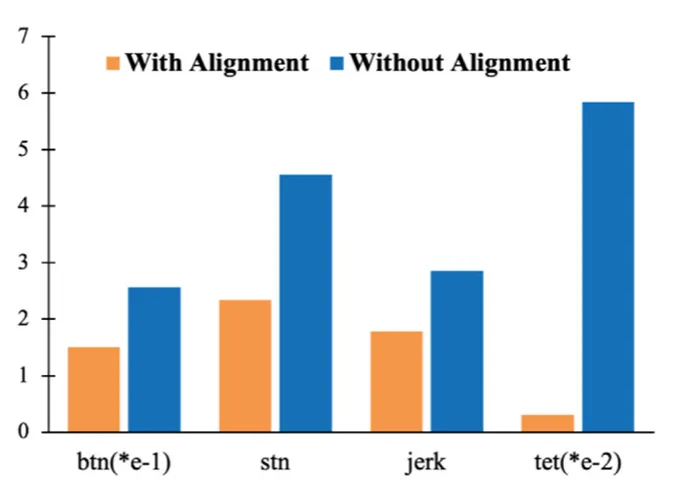
上表给出了500个场景下With Alignment与Without Alignment的平均对比结果。可以看出,加入表示对齐后,车辆在安全性、舒适性和通行能力方面整体表现更好。尤其是指标tet从0.058442降至0.003009,说明危险暴露时间大幅减少。上图进一步突出展示了btn、stn、jerk和tet等受CRA影响最明显的指标,其中危险条件减少约94.9%,表明表示对齐对提升自动驾驶决策安全性具有重要作用。
本文提出了一种知识驱动的自动驾驶决策框架CRA,其核心思想是通过认知表示对齐实现可泛化的知识迁移。在该框架中,预测地图作为知识驱动基础,后继矩阵作为可迁移知识,图表示和SPGK用于实时场景与知识库中特征场景之间的相似性匹配。实验结果表明,CRA能够有效提升自动驾驶车辆在多类交通场景中的决策性能,尤其体现在任务完成率、安全性、通行能力和驾驶舒适性等方面。
作者也指出了该方法的不足和未来改进方向。首先,CRA需要额外进行知识匹配和表示对齐,因此计算时间相比部分方法有所增加,未来需要进一步提升算法效率。其次,本文知识库中的特征场景数量固定为7类,未来可以构建更加灵活、可扩展的知识库,以覆盖更加复杂和安全关键的驾驶场景。此外,本文使用图表示描述车辆交互关系,未来也可以探索更多场景相似性度量方法,并将更多因素纳入价值函数,以进一步优化轨迹选择和复杂场景下的决策表现。
本文提出的CRA框架与传统基于规则或数据驱动的自动驾驶决策方法不同,该文从知识迁移的角度出发,尝试让自动驾驶系统像人类驾驶员一样利用已有经验理解新场景。文章将预测地图作为知识表达方式,并通过后继矩阵描述不同交通场景下的状态转移关系,使“知识”这一概念具有了较清晰的数学形式。同时,作者利用图表示和最短路径图核计算实时场景与典型场景之间的相似性,再根据相似性对不同知识进行加权融合,从而避免了简单套用固定场景知识带来的不匹配问题。整体来看,该方法不仅提升了自动驾驶决策的安全性和稳定性,也为复杂交通场景下的决策泛化问题提供了一种新的思路。
不过,本文方法仍然存在一定的改进空间。首先,文中构建的知识库主要由 7种基于车道可用性的典型场景组成,虽然能够覆盖部分常见驾驶情况,但对于更加复杂的真实道路环境,例如行人突然横穿、非机动车混行、施工路段或极端交通冲突场景,其知识表达能力可能还不够充分。其次,图表示主要关注车辆之间的位置关系和距离特征,而实际驾驶决策还会受到速度、加速度、驾驶意图、道路曲率、交通规则等因素影响,后续研究可以进一步丰富节点和边的属性。此外,CRA在提高决策性能的同时增加了一定计算开销,因此如果要应用于实车系统,还需要进一步优化算法实时性。总体而言,该文在知识驱动自动驾驶决策方面具有较好的启发意义,适合作为自动驾驶决策规划、场景理解和知识迁移相关研究的重要参考。




 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
