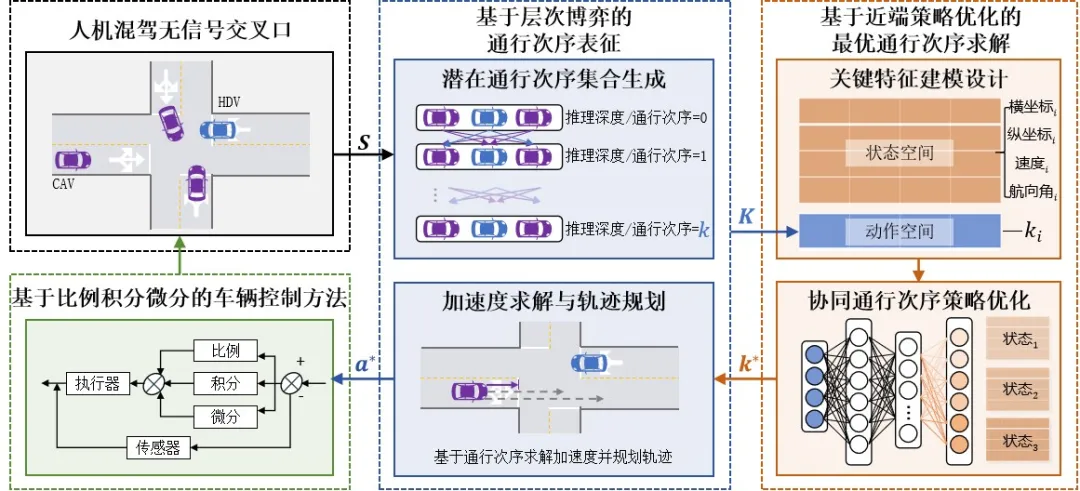
本文提出了“层次博弈表征-近端策略优化”框架,其核心思想是通过两个关键模块的配合,实现既考虑人类异质性、又能实时求解的协同决策。
1.用“层次博弈”理解人类驾驶员
研究没有假设人类驾驶员是完全理性的,而是引入了层次博弈模型,将驾驶员的推理深度与通行次序直接关联:
①定义推理深度k:k=0的驾驶员仅将其他车辆视为匀速行驶,快速做出非策略性决策;k>0的驾驶员则会基于对他人推理深度的预判进行决策;
②通过多轮迭代推演,建立“推理深度-行为策略-通行次序”的递进关系,全面表征所有潜在通行次序组合,精准捕捉人类驾驶员的异质特征;
③利用动态时间规整(DTW)技术,通过对比规划轨迹与真实轨迹的相似度,实时估计人类驾驶车辆的推理深度,为协同决策提供可靠依据。
图1 HGPPO协同决策算法框架
2.用“强化学习”快速搜索最优解
虽然层次博弈梳理了可能性,但参与车辆增多时,通行次序组合会指数级增长,难以实时计算。为此,研究采用了近端策略优化算法,大幅提升决策实时性:
①状态空间涵盖交叉口内所有车辆的位置、速度、航向角等核心信息,动作空间直接定义为通行次序(离散为0-3级),简化决策维度;
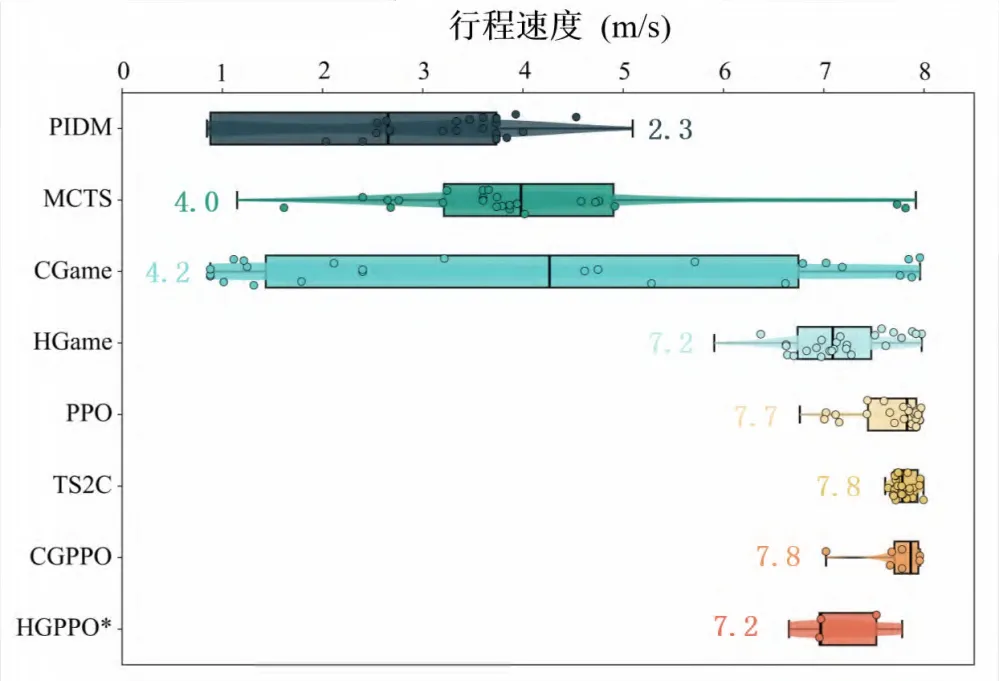
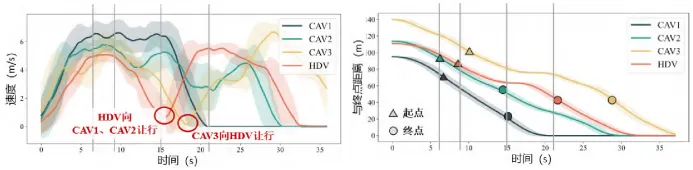
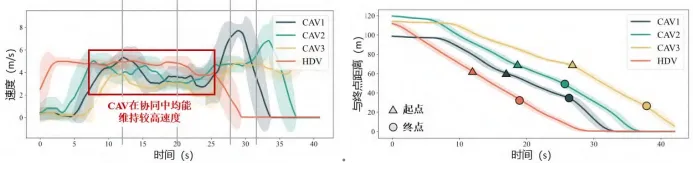
②设计多目标奖励函数,综合考量通行效率(鼓励合理高速行驶)、安全性(碰撞惩罚)与任务完成度(到达终点奖励),平衡系统目标;
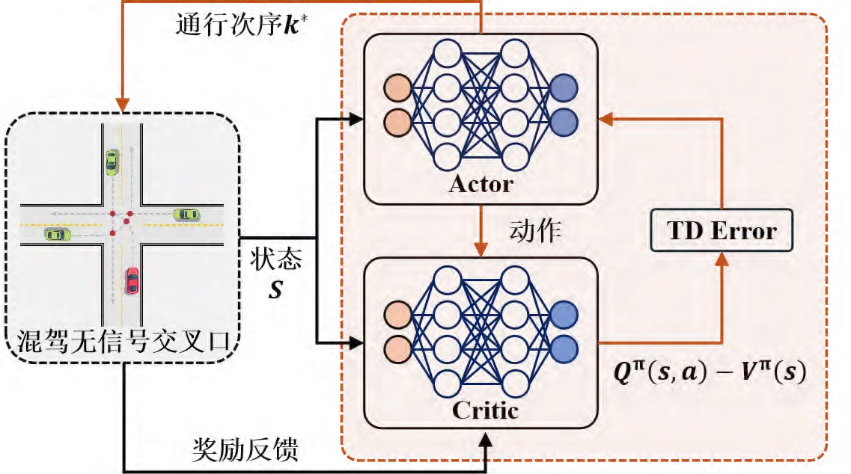
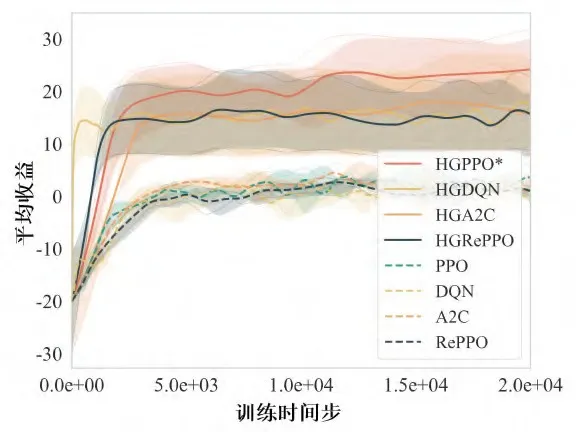
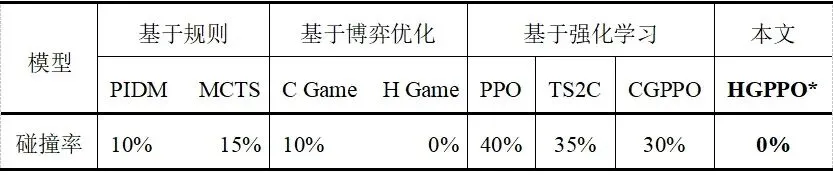
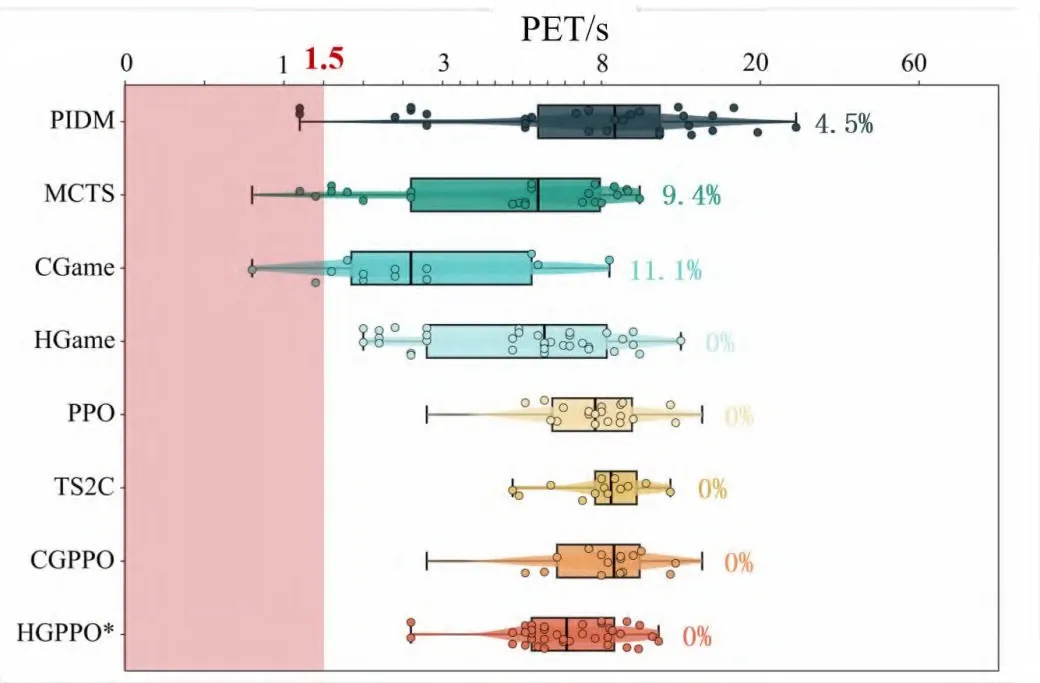
③借助Actor-Critic架构与裁剪机制,在保证策略稳定更新的同时,实现最优通行次序的高效搜索,单步求解时间仅0.14s,满足实际部署的实时性要求。
图2 Actor-Critic架构图











 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
