
龙哥推荐理由:
还记得龙哥之前解过的DiffE2E、TrajDiff吗?它们都是在轨迹空间玩多模态。今天这篇ADT论文,直接切入更底层的动作空间,用扩散模型同时预测多个油门、刹车、转向候选,再靠一个极简的NNM选择器选出最佳动作。文章把这个很久没人碰的“硬核”控制问题给解了,而且直接在Bench2Drive上干到SOTA,延迟还降到了离谱的19.2ms,比Hydra-NeXt快了将近28倍。对于关心端到端自动驾驶落地、尤其是低延迟直接控制的朋友,这篇绝对不容错过。
原论文信息如下:
论文标题:
Multimodal Action Diffusion for Robust End-to-End Autonomous Driving
发表日期:
2026年06月
发表单位:
Computer Vision Center (CVC) / Universitat Autònoma de Barcelona (UAB)
原文链接:
https://arxiv.org/pdf/2606.02105v1.pdf
大家好,欢迎来到龙哥的硬核AI解读时间。这年头,一提到自动驾驶的端到端方案,大家脑子里蹦出来的多半是规划一条漂漂亮亮的轨迹线,然后再交给一个复杂的底层控制器去“解码”执行。从占用网络到轨迹预测,大家都在这条“规划-控制”的流水线上精雕细琢,恨不得把未来10秒钟的车轮走向都算得清清楚楚。
但龙哥今天要跟大家聊的这篇论文,路子走得够野!它不仅在顶流 Bench2Drive 自动驾驶榜单上拿了第一,更让人惊喜的是,它直接绕开了“轨迹规划”这个中间商,在纯粹的动作空间里玩起了“多重预测,优中选优”的戏码。
简单说,以前的车是“我看到了路,我计划怎么走,然后我控制方向盘”,而 ADT 是“我看到了路,我同时想出好几个可行的开法(比如轻踩油门、微打方向、大力刹车),然后我瞬间挑出一个最合理的动作执行下去”。这种“天生就是多模态”的设计思路,不仅效果炸裂,而且速度惊人——比之前的最强方案 Hydra-NeXt 快了将近 28倍 !
1. 动作空间多模态:打破确定性控制的局限
咱们先来聊聊,为啥 ADT 要死磕“动作空间”这个东西。
大多数端到端的驾驶模型,本质上是在做一个“单点回归”的任务:你给我一张图,我告诉你一个方向盘角度和一个油门深度。这是一种非常确定的操作,但问题恰恰出在这个“确定”上。现实世界是充满不确定性的,前方路口你既可以减速避让,也可以轻微加速抢在别人前头通过——这两种驾驶策略都是合理的,甚至可以说是多模态的。而一个确定性的模型,只能被迫学会一个“平均”动作,但“平均动作”往往什么都不是。
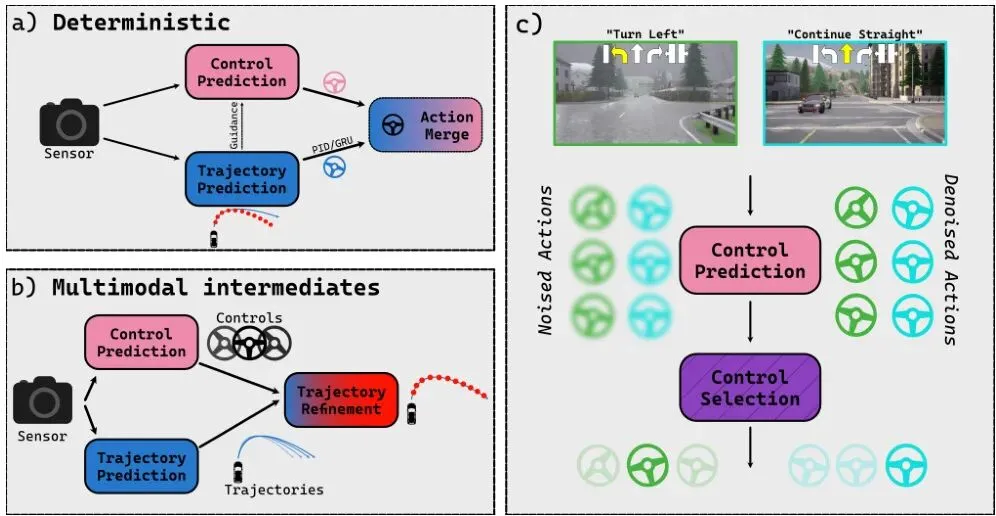 图1:驾驶中的不确定性示意。(a) 确定性控制:模型直接预测要施加给车辆的控制信号 [6, 41];(b) 轨迹空间多模态:生成多条轨迹再转变成控制信号,但多模态只在中间的轨迹表示中体现 [28, 29];(c) 动作空间多模态(本文方法):直接在动作空间中采样多个候选控制信号,然后从中选择执行。关键在于,候选信号的分布反映了指令本身的模糊性:一个“左转”指令对应很多种靠谱的转向方案,候选集就很大;而“直行”指令几何约束强,候选之间差别就很小。
而 ADT 的核心理念就是:告别单一确定,拥抱天生多模态。它认为,对动作空间进行多模态建模,不是一个可选项,而是提升驾驶性能和鲁棒性的关键路径。通过直接预测动作的概率分布,而不是一个确定值,车辆才能拥有老司机那种“见招拆招”的潜力。
图1:驾驶中的不确定性示意。(a) 确定性控制:模型直接预测要施加给车辆的控制信号 [6, 41];(b) 轨迹空间多模态:生成多条轨迹再转变成控制信号,但多模态只在中间的轨迹表示中体现 [28, 29];(c) 动作空间多模态(本文方法):直接在动作空间中采样多个候选控制信号,然后从中选择执行。关键在于,候选信号的分布反映了指令本身的模糊性:一个“左转”指令对应很多种靠谱的转向方案,候选集就很大;而“直行”指令几何约束强,候选之间差别就很小。
而 ADT 的核心理念就是:告别单一确定,拥抱天生多模态。它认为,对动作空间进行多模态建模,不是一个可选项,而是提升驾驶性能和鲁棒性的关键路径。通过直接预测动作的概率分布,而不是一个确定值,车辆才能拥有老司机那种“见招拆招”的潜力。
2. ADT架构:扩散transformer实现多模态动作生成
ADT,全称是 Action Diffusion Transformer(动作扩散Transformer)。这名字就告诉你了它的核心:用扩散模型来做动作预测。ADT 的架构不复杂,但逻辑非常巧妙,主要分三步走:视觉感知编码 → 跨模态融合压缩 → 扩散模型解码。
首先,ADT 通过一个视觉主干网络(比如ResNet-34,跟CIL++一样,[41])对前后两个摄像头拍摄的画面进行特征提取,再和车速、导航指令等信息融合,形成一串“观察标记”。
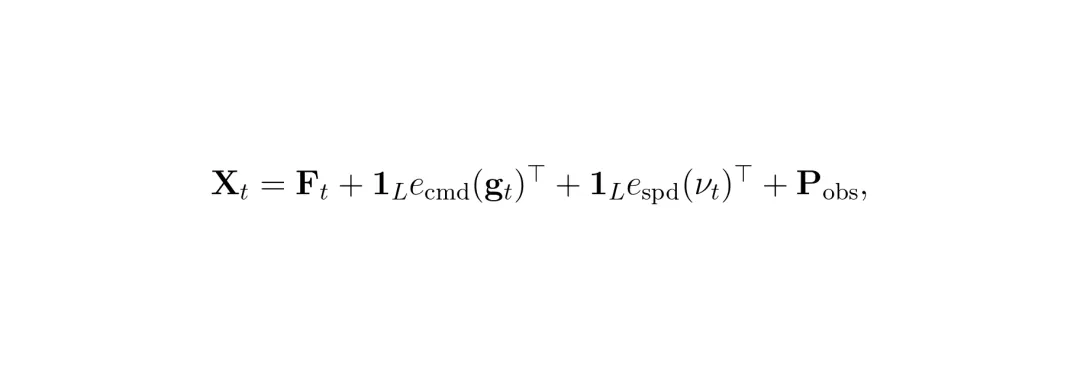 公式:观察标记的生成。该公式描述了如何将视觉特征(F_t)、导航指令(e_cmd)和车速(e_spd)通过加法融合,并加上位置编码(P_obs),生成输入到Transformer编码器中的标记(X_t)。
然后,一个 Transformer 编码器(公式:M_t = TxEnc_θ(X_t))把这些标记进行上下文理解。但ADT并没有把这一大堆编码标记直接丢给解码器,而是用了一个非常高效的压缩技巧——可学习的观察查询。通过一个多头注意力机制(MHA),把上千个编码标记压缩成一个或几个浓缩了场景信息的“观察条件标记”(见公式:Z_t = MHA_θ(Q_o, M_t, M_t))。这就像读了一整本书后,只提取出了一句话的精华。
核心的戏码在扩散解码器这里。它不再直接预测动作值(比如方向盘打多少度),而是同时“想出”好几个候选动作。ADT 是如何做的呢?模型学习的是一个去噪过程,它接收一个随机噪声(ξ)和观察条件标记(Z_t),通过一个Transformer解码器一步步地把它“净化”成一个可行的控制动作(油门、刹车、转向)。
公式:观察标记的生成。该公式描述了如何将视觉特征(F_t)、导航指令(e_cmd)和车速(e_spd)通过加法融合,并加上位置编码(P_obs),生成输入到Transformer编码器中的标记(X_t)。
然后,一个 Transformer 编码器(公式:M_t = TxEnc_θ(X_t))把这些标记进行上下文理解。但ADT并没有把这一大堆编码标记直接丢给解码器,而是用了一个非常高效的压缩技巧——可学习的观察查询。通过一个多头注意力机制(MHA),把上千个编码标记压缩成一个或几个浓缩了场景信息的“观察条件标记”(见公式:Z_t = MHA_θ(Q_o, M_t, M_t))。这就像读了一整本书后,只提取出了一句话的精华。
核心的戏码在扩散解码器这里。它不再直接预测动作值(比如方向盘打多少度),而是同时“想出”好几个候选动作。ADT 是如何做的呢?模型学习的是一个去噪过程,它接收一个随机噪声(ξ)和观察条件标记(Z_t),通过一个Transformer解码器一步步地把它“净化”成一个可行的控制动作(油门、刹车、转向)。
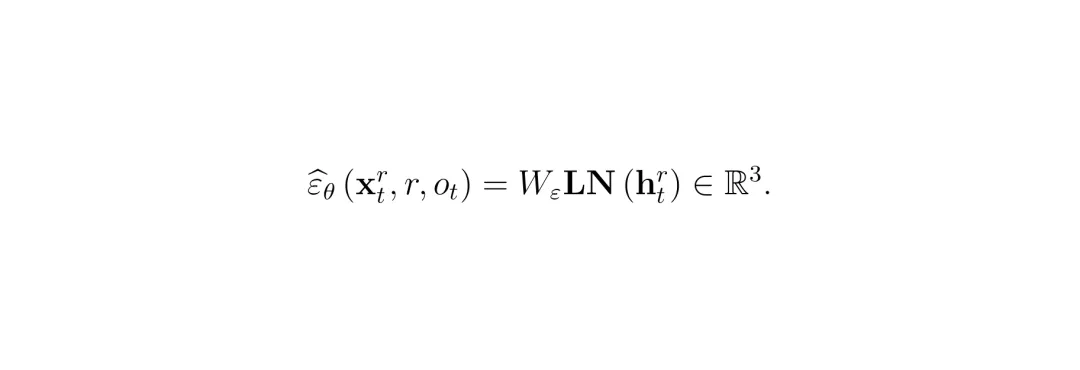 公式:噪声预测。模型的解码器并不是直接预测动作值,而是预测注入到当前动作中的高斯噪声(ε_hat)。图中W_ε和LN分别代表一个线性投影层和层归一化。
在训练时,给网络一个标准的MSE损失函数(L_diff),让它学会预测噪音。因为从不同的随机噪声开始去噪,最终会收敛到不同的、但同样合理的动作上,这让ADT天然就具备了生成多模态动作的能力。
公式:噪声预测。模型的解码器并不是直接预测动作值,而是预测注入到当前动作中的高斯噪声(ε_hat)。图中W_ε和LN分别代表一个线性投影层和层归一化。
在训练时,给网络一个标准的MSE损失函数(L_diff),让它学会预测噪音。因为从不同的随机噪声开始去噪,最终会收敛到不同的、但同样合理的动作上,这让ADT天然就具备了生成多模态动作的能力。
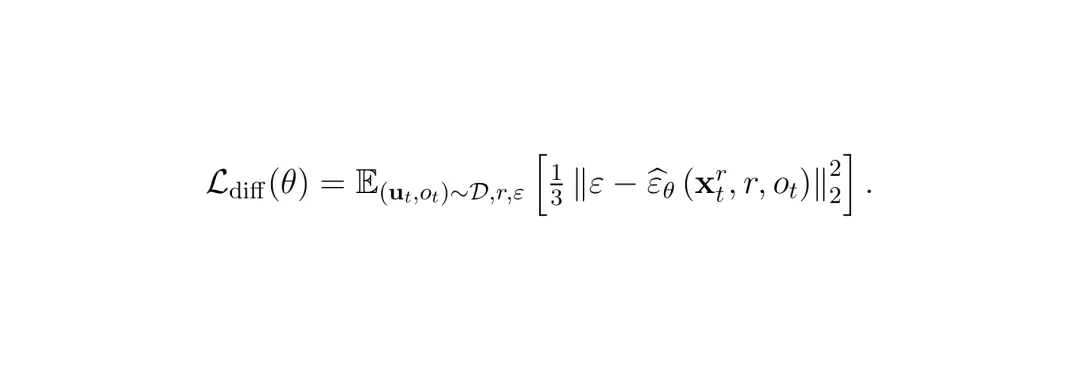 公式:扩散损失函数。这是ADT训练的核心目标函数,通过最小化真实噪声(ε)和预测噪声(ε_hat)之间的均方误差来训练网络。本质上,它学习的是如何从一个嘈杂的动作空间中还原出干净的动作。
公式:扩散损失函数。这是ADT训练的核心目标函数,通过最小化真实噪声(ε)和预测噪声(ε_hat)之间的均方误差来训练网络。本质上,它学习的是如何从一个嘈杂的动作空间中还原出干净的动作。3. NNM选择:从候选集合中选出最优动作
好,现在ADT一口气生成了K个(比如10个)候选动作,但车只能执行一个啊,到底听谁的?这就是 Nearest Neighbour Matching(NNM,最近邻匹配) 机制大显身手的地方。
NNM 的做法非常简洁、优雅。它的逻辑是:虽然动作是多模态的,但大多数情况下,最安全、最合理的那个动作,一定是大多数候选动作中最“同意”的那个,也就是“共识”最强的那个。NNM把每个候选动作与其他所有候选动作的距离(L1距离)加起来,得到一个“共识分数”。分数越低,说明它跟其他人的意见越一致。
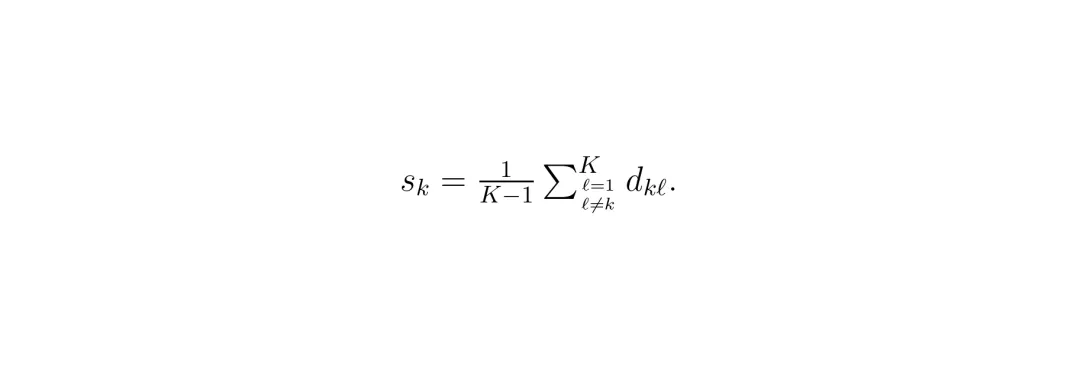 公式:NNM 共识分数。这个公式计算第k个候选动作的共识分数(s_k)。它等于该候选动作与其他所有候选动作的平均距离。距离越小,说明第k个候选动作越有代表性。
公式:NNM 共识分数。这个公式计算第k个候选动作的共识分数(s_k)。它等于该候选动作与其他所有候选动作的平均距离。距离越小,说明第k个候选动作越有代表性。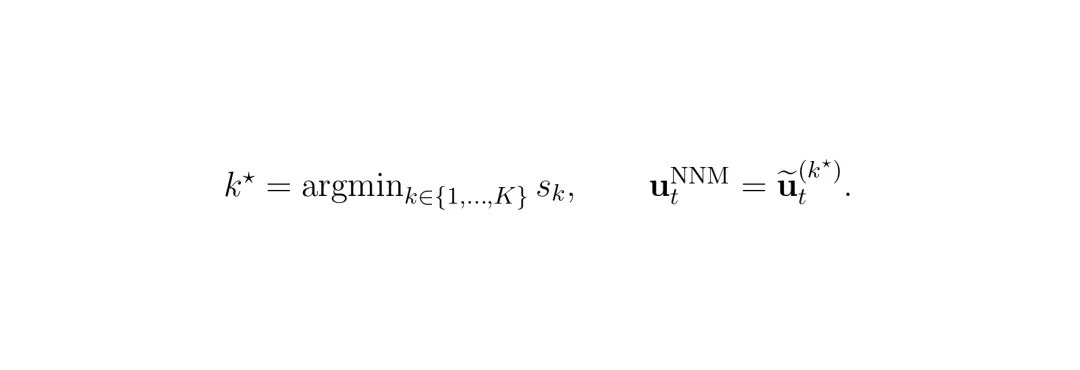 公式:NNM 最终选择。从K个候选动作中选出共识分数最小的那个作为最终执行的动作。
公式:NNM 最终选择。从K个候选动作中选出共识分数最小的那个作为最终执行的动作。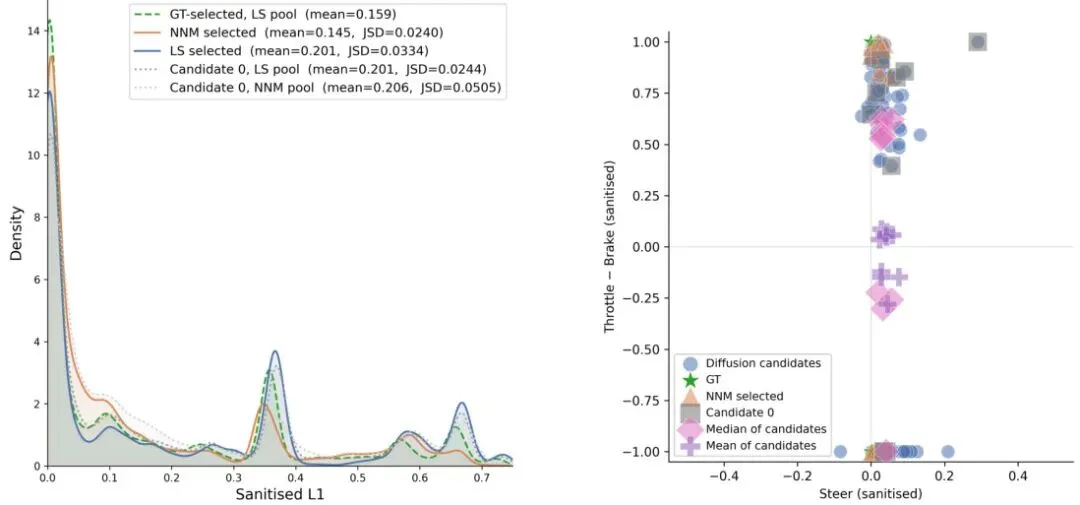 图3:离线候选选择对比。左图展示了不同选择规则的误差分布曲线,NNM(实线)的误差最低,且分布与真值最接近(JSD最低),说明其选择最稳定。右图展示了10个随机场景下,不同的K个候选动作(彩色点)在转向/速度轴上的分布。可以看到,如果取均值(星标)或中位值(方标),会掉入“无效动作”的陷阱,而NNM直接选出的候选动作(圆标)则非常合理。
论文中的实验结果也证明了NNM的有效性。下图表格(a)显示,在清洗后的动作空间(Sanitised)上,NNM选择出的动作(Selected)误差(0.145)远低于一个可学习的选择器(Learned,0.159),几乎达到了理论最优的Oracle水平。这充分说明,NNM这个无需训练、无需参数的简单策略,是发挥扩散模型多模态优势的关键一环。
图3:离线候选选择对比。左图展示了不同选择规则的误差分布曲线,NNM(实线)的误差最低,且分布与真值最接近(JSD最低),说明其选择最稳定。右图展示了10个随机场景下,不同的K个候选动作(彩色点)在转向/速度轴上的分布。可以看到,如果取均值(星标)或中位值(方标),会掉入“无效动作”的陷阱,而NNM直接选出的候选动作(圆标)则非常合理。
论文中的实验结果也证明了NNM的有效性。下图表格(a)显示,在清洗后的动作空间(Sanitised)上,NNM选择出的动作(Selected)误差(0.145)远低于一个可学习的选择器(Learned,0.159),几乎达到了理论最优的Oracle水平。这充分说明,NNM这个无需训练、无需参数的简单策略,是发挥扩散模型多模态优势的关键一环。
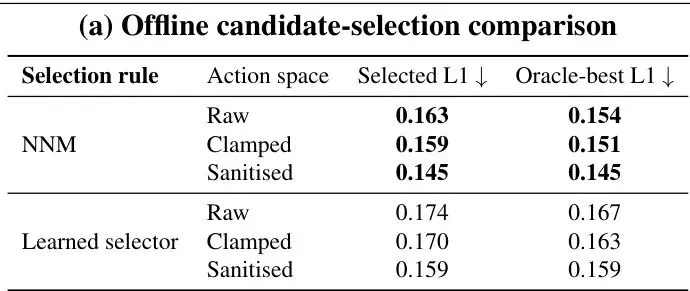 表格(a): 离线候选选择对比结果。NNM策略(Selected)在清洗后的动作空间上的平均L1误差(0.145)远低于可学习的候选选择器(Learned, 0.159),并且几乎和理论上的最佳选择(Oracle,0.135)持平。
表格(a): 离线候选选择对比结果。NNM策略(Selected)在清洗后的动作空间上的平均L1误差(0.145)远低于可学习的候选选择器(Learned, 0.159),并且几乎和理论上的最佳选择(Oracle,0.135)持平。4. 封闭环验证:ADT在Bench2Drive上全面领先
说一千道一万,自动驾驶最终还是要靠闭环(Closed-loop)评测说话。ADT在目前极具挑战性的 Bench2Drive 基准测试上的表现,堪称惊艳。
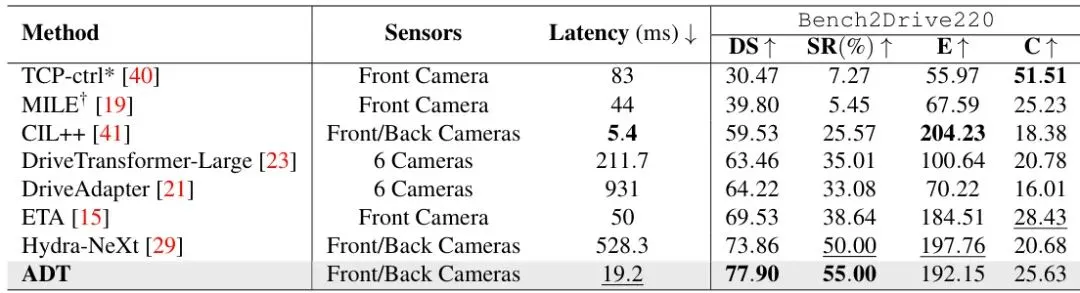 表2:Bench2Drive-220 闭环对比结果。在关键指标驾驶得分(DS)和成功率(SR)上,ADT均以绝对优势领先。更令人难以置信的是,在只用了前后两个摄像头、0个GPS的配置下,它的延迟(Latency)只有19.2毫秒,远低于像Hydra-NeXt这样的轨迹规划方案(528.3毫秒)。
从表2的数据来看,ADT挑战的还是天花板级别的对手。它能达到77.90的驾驶得分和55%的成功率,远超此前表现最好的轨迹规划模型。更重要的是,它不用GPS,不用高精地图,仅靠一个高效的扩散transformer,就实现了这种高性能和19.2ms的低延迟。
在多能力(Multi-ability)评分中,ADT同样表现抢眼。
表2:Bench2Drive-220 闭环对比结果。在关键指标驾驶得分(DS)和成功率(SR)上,ADT均以绝对优势领先。更令人难以置信的是,在只用了前后两个摄像头、0个GPS的配置下,它的延迟(Latency)只有19.2毫秒,远低于像Hydra-NeXt这样的轨迹规划方案(528.3毫秒)。
从表2的数据来看,ADT挑战的还是天花板级别的对手。它能达到77.90的驾驶得分和55%的成功率,远超此前表现最好的轨迹规划模型。更重要的是,它不用GPS,不用高精地图,仅靠一个高效的扩散transformer,就实现了这种高性能和19.2ms的低延迟。
在多能力(Multi-ability)评分中,ADT同样表现抢眼。
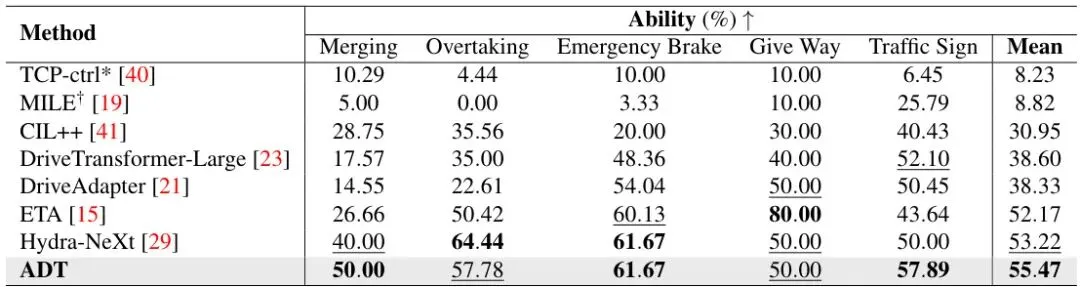 表3:Bench2Drive-220 多能力对比结果。ADT在五项子任务的平均得分(55.47%)上最高,尤其是在“汇入车流”(50.00%)和“遵守交通标志”(57.89%)场景下取得了最好成绩。这充分说明了其作为基础动作策略的泛化能力和鲁棒性。
表3:Bench2Drive-220 多能力对比结果。ADT在五项子任务的平均得分(55.47%)上最高,尤其是在“汇入车流”(50.00%)和“遵守交通标志”(57.89%)场景下取得了最好成绩。这充分说明了其作为基础动作策略的泛化能力和鲁棒性。 表1:从CIL++到ADT的模型迭代路线图。从最初的CIL++(双摄像头MLP,DS=59.53),到用Transformer解码器(DS=67.45),再到引入扩散模型(DS=70.14),最后由NNM选择(DS=77.90)。每一步改进,驾驶得分都在稳步提升,清晰地证明了“动作空间多模态”+“NNM”策略的有效性。
当然,ADT也并非完美无缺。论文提到,它获得的舒适度(Comfortness)分数不高。这主要是因为其为了追求更高的成功率和更快的驾驶效率,在启动和停止时会做出更果断、更急的加速或刹车动作。这就像一个赛车手,为了赢下比赛,会更敢于深踩油门,牺牲掉一些平顺性。
表1:从CIL++到ADT的模型迭代路线图。从最初的CIL++(双摄像头MLP,DS=59.53),到用Transformer解码器(DS=67.45),再到引入扩散模型(DS=70.14),最后由NNM选择(DS=77.90)。每一步改进,驾驶得分都在稳步提升,清晰地证明了“动作空间多模态”+“NNM”策略的有效性。
当然,ADT也并非完美无缺。论文提到,它获得的舒适度(Comfortness)分数不高。这主要是因为其为了追求更高的成功率和更快的驾驶效率,在启动和停止时会做出更果断、更急的加速或刹车动作。这就像一个赛车手,为了赢下比赛,会更敢于深踩油门,牺牲掉一些平顺性。

龙迷三问
这篇论文解决什么问题?ADT主要解决端到端自动驾驶中,现有的确定性控制模型无法适应驾驶场景的不确定性和多模态(多种可能)的问题。它证明了直接在动作空间(油门、刹车、转向)进行多模态预测,并利用一个轻量级的共识机制(NNM)进行选择,能够显著提升闭环驾驶任务的性能和鲁棒性。
ADT和Diffusion Policy有什么区别?Diffusion Policy[3]是在机器人领域提出的,它在动作空间通过扩散模型隐式地学习动作分布,但它并不显式地生成多个候选动作并从中选择。ADT的关键创新在于,它利用扩散模型,在推理阶段显式生成K个候选动作,并使用NNM机制从中“优中选优”,将多模态能力从“隐式”变成了“显式可操作”。
NNM选择机制为什么能work?NNM原理基于一个假设:在大多数情况下,正确的、安全的驾驶动作往往是所有生成的候选动作“共识度”最高的那个。通过计算每个候选动作与其他动作的距离总和作为“共识分数”,分数最低的候选动作代表了模型内部对这个场景最一致、最不模糊的解读。这避免了均值或中位数可能导致的“无效平均动作”,而保留了真实、可执行的驾驶策略。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~龙哥点评
论文创新性:★★★★✰
首次系统地证明了在多模态动作空间里做直接控制(而非轨迹规划)的有效性。虽然扩散模型和Transformer都是组合使用的成熟技术,但把它们用在纯动作控制上,并设计出NNM选择机制来利用多模态,这个思路对于端到端自动驾驶领域来说非常有启发性,是理念层面的创新。
实验合理度:★★★★★
实验设计非常扎实。在 Bench2Drive 这个复杂闭环基准上,对比了多个不同类型的SOTA方法,从纯控制到轨迹规划全有涵盖。而且论文内部的设计迭代(从CIL++到ADT的路线图)非常清晰地量化了每一步创新的价值,结论令人信服。
学术研究价值:★★★★★
非常强。它为“动作空间”这一长期以来被视为黑箱子的研究方向,提供了一套优雅且有效的理论框架和实践范本。它可能会引领很多研究者重新思考端到端自动驾驶的范武,从“先规划后控制”回归到更直接、更鲁棒的“直接多模态控制”。
稳定性:★★★✰✰
闭环测试的成功率很高,说明在大部分场景比较稳定。但论文也提到其舒适度较低,说明在加速、刹车的平稳性上还有提升空间,可能会让乘客感觉不太舒服。极端、未知场景下的稳定性还有待更多测试验证。
适应性以及泛化能力:★★★★✰
只在 CARLA 模拟器上进行了训练和测试,虽然后者场景很丰富,但模拟器与真实世界之间仍有很大差距。模型能否很好地泛化到不同天气、传感器配置或真实物理世界中,仍需进一步实验。不过它仅靠两个摄像头就能工作,架构的泛化潜力是很强的。
硬件需求及成本:★★★★★
这一点是ADT最大的亮点之一。它不依赖高精地图、GPS和 LiDAR。推理延迟只有19.2毫秒,这意味着它可以在功耗更低、算力更小的车载边缘设备上实现40Hz甚至50Hz的实时控制,部署成本极低,速度极快。
复现难度:★★★★✰
论文使用了标准的PyTorch和PyTorch Lightning框架,模型结构也由标准的Transformer组成,逻辑清晰。如果有论文和代码开源,复现难度属于中等偏下。主要的工作量可能集中在数据预处理和在 Bench2Drive 环境上进行训练调优上。
产品化成熟度:★★✰✰✰
目前还处于学术研究阶段。虽然性能突出,但距离真正的“可用”产品还有距离。最大的挑战在于从模拟环境到真实世界的迁移(Sim-to-Real)。此外,舒适度不足也是一个需要解决的产品痛点。不过,其低延迟、低成本、高成功率的特性,已经为下一代具身智能体的控制策略指明了方向。
可能的问题:最直接的问题是舒适度与效率的平衡问题。论文虽然分析了一些原因,但没有提出一个有效的软约束或训练策略来在追求速度的同时保证乘坐体验。此外,假设NNM选择的“共识”总是最优的,这在一些需要特立独行的极端情况(比如紧急避险)下可能会失效。
[3] Cheng Chi et al. Diffusion Policy: Visuomotor Policy Learning via Action Diffusion. RSS, 2023.[22] Q. Chen et al. Bench2Drive: Towards Multi-Ability Benchmarking for End-to-End Autonomous Driving. CVPR, 2024.[29] D. Porres et al. Hydra-NeXt: Control-based Multimodal Action Generation for End-to-End Autonomous Driving. IROS, 2025.[41] J. D. Rodríguez-Vidal et al. CIL++: Conditional Imitation Learning for End-to-End Autonomous Driving. ICRA, 2024.*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的"阅读原文",查看更多原论文细节哦!
🐉 本周星球独家(真实样本):
📰 资讯:人工智能:加速向未来_学信网 | chsi.com.cn | 时间未知
💼 招聘:OpenAI机器人岗位硬件招聘:全栈硬件、运营、系统及机器学习…
📚 论文:驾驶分数暴跌90%,CMU指出端到端模型遇危机!
星球过去 7 天共更新 247 条干货,这只是冰山一角:
👇 扫码加入「龙哥读论文」知识星球,每天打开像刷视频一样轻松


加入龙哥读论文粉丝群,
扫描下方二维码或者添加龙哥助手微信号加群:kangjinlonghelper。
一定要备注:研究方向+地点+学校/公司+昵称(如 自动驾驶+巴塞罗那+UAB+龙哥),根据格式备注,可更快被通过且邀请进群。
『龙哥读论文』微信群目前包含:图像处理、大模型及智能体、自动驾驶及机器人、AI医疗及AI金融5个群。本文作者龙行智械就在自动驾驶群等你来聊多模态控制!


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
