尽管自动驾驶系统在结构化道路上的表现日益成熟,但将视觉-语言-行动模型(Driving VLA)部署到真实开放道路时,一个关键挑战浮现:模型的自然语言决策与最终轨迹规划往往不一致——模型可能生成“加速直行”的语言描述,却输出近乎静止的轨迹。这种 语言-行动鸿沟(Language-Action Gap)严重制约了VLA的实用性。来自上海期智研究院、清华大学和同济大学的研究团队没有追求更复杂的语言交互,而是回归根本:如果让中间语言变得可验证,会发生什么?他们的答案是 DriveMA——一个建立在可验证“元动作”之上的 Driving VLA 框架。
当模型"说一套做一套"
Driving VLA 的核心理念很吸引人:把自然语言引入感知到行动的管线中,用语义知识来提升下游规划的质量。
理想情况下,语言不只是描述场景的"字幕组",更应该是暴露高层驾驶意图、引导低层轨迹生成的"决策层"。
但现实是,许多 Driving VLA 在语言侧做出了合理的决策——"前方绿灯,应当加速直行"——生成的轨迹却是另一回事。模型预测了加速,轨迹却几乎静止。
研究团队在论文中展示了一个触目惊心的案例:仅经过监督微调的模型,在绿灯路口预测出 `accelerate, straight` 的元动作,但生成的 5 秒未来轨迹位移几乎为零。语言和行动之间,隔着一道没有桥梁的鸿沟。
此前的工作尝试过多种方式来弥合这道鸿沟。
DriveVLM试图让自动驾驶与大视觉语言模型真正汇合,把场景理解、推理和规划放进统一的视觉语言框架中;DriveAgent-R1进一步引入主动感知与混合思考机制,让模型不只是被动回答问题,而是学会围绕驾驶任务组织推理过程;也有工作尝试通过人类反馈强化学习学习更加个性化的驾驶风格,让轨迹规划更贴近人类偏好。
与此同时,SimLingo通过多任务训练和 Action Dreaming 来对齐语言与行动,LinkVLA将语言和行动 token 统一到共享空间并引入双向映射目标,Drive-R1则主要通过大规模驾驶 VQA 做领域对齐。
这些探索共同说明了一件事:语言确实能为自动驾驶规划提供高层语义支撑。但问题也随之暴露出来——许多方法仍然依赖隐式对齐,让模型通过辅助任务或额外数据自己去"悟"出语言和行动的对应关系。
DriveMA 的切入点因此显得格外直接:真正的突破口或许不在于设计更复杂的语言接口,而在于让语言接口变得可验证。
元动作:简单到被低估的中间接口
DriveMA 的核心设计非常简洁。
它引入了一种名为 元动作(Meta-Action)的中间语言接口。一个元动作由两部分组成:纵向动作——从 stop、decelerate、keep、accelerate 中四选一——和横向动作——描述粗粒度的机动意图,比如直行、转弯、变道或微调偏移。
听起来很简单,甚至有些过于简单了。
但关键在于,元动作是可验证的。一条生成的未来轨迹,可以通过基于规则的投影被映射回动作空间,然后检查它是否与模型自己做出的高层决策一致。这种可验证性,让语言决策与轨迹规划之间的对齐从"凭感觉"变成了"可度量"。
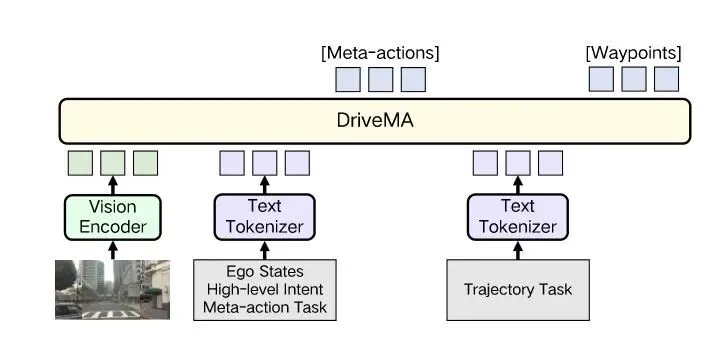
DriveMA 的整体流程可以概括为两步:给定驾驶输入,模型先预测一个紧凑的高层元动作,然后基于这个元动作和原始输入生成未来的路点轨迹。x → m → τ,一个清晰的"决策-执行"链条。
框架建立在通用视觉-语言模型 Qwen3.5 之上。视觉观测由视觉编码器处理,而非视觉输入和输出——包括轨迹坐标——都通过原生的文本分词器表示,不引入额外的模态适配层。
从轨迹中"长"出标注
元动作听上去像是需要大量人工标注的东西,但 DriveMA 走了一条更聪明的路。
研究团队设计了一套轨迹驱动的自动标注流水线。给定一条专家未来轨迹,系统将它划分为不重叠的时间块,然后对每个块标注离散的元动作。
纵向标注完全由轨迹几何特征决定。系统在训练集上对速度曲线特征进行聚类,自动发现数据集特定的运动边界,然后固化为确定性规则:极低速度和位移对应 stop,速度曲线斜率为负对应 decelerate,接近零对应 keep,为正对应 accelerate。
横向标注则采用"轨迹优先"的策略。航向角变化和横向位移首先用于识别近直线轨迹,微调偏移(shift slightly)由横向位移的方向和幅度直接判定。对于转弯、变道等需要视觉上下文才能区分的细粒度情况,系统先用轨迹规则生成候选标签集,再用受约束的视觉解析器从候选中选择最终标签。
重要的是,这套标注流水线不需要人工参与,同时又保留了轨迹可验证的核心属性。训练用细粒度标签,验证用粗粒度空间——这种设计既保证了监督信号的语义丰富性,又让一致性奖励的计算保持可靠。
先懂决策,再学控车
在进入强化学习之前,DriveMA 经历了两阶段的监督微调。
第一阶段是动作中心预训练(Action-Centric Pretraining,ACP)。这一阶段包含两类监督信号:元动作预测任务——模型从驾驶输入直接预测专家元动作,不生成轨迹——以及从公开数据集中筛选出的 24 万条驾驶相关 VQA 样本,覆盖驾驶意图、动作决策和风险感知行为。
第二阶段是元动作条件规划 SFT。模型学习完整的多轮生成序列:x → m* → τ*,即基于专家元动作来生成轨迹。
这两阶段的分离设计让模型先"理解驾驶决策",再"学会具体控车",避免了两种学习目标的相互干扰,也让后续的 RL 阶段有了一个更强的起点。
把奖励精准投递到每一个轮次
监督微调引入了元动作接口,但它并不能保证模型生成的轨迹一定忠实于自己的高层决策。
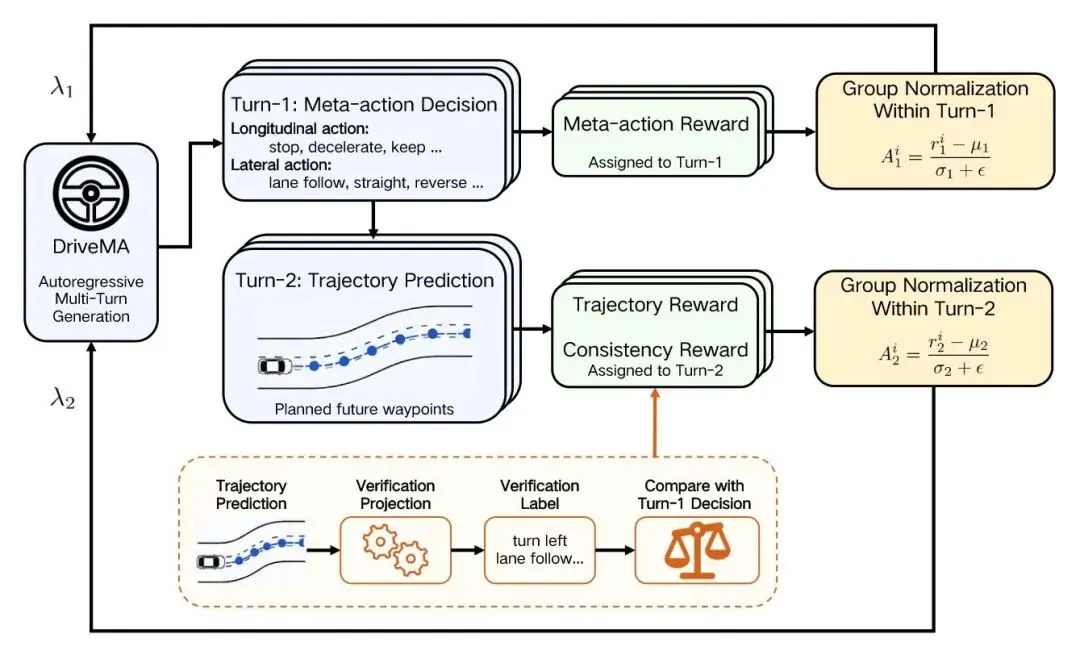
这里正是 DriveMA 最具技术洞察力的部分:Turn-Level Credit Assignment RL。
标准 GRPO 的做法是将一个序列级别的奖励分配给所有生成的 token。但 DriveMA 的生成是两轮的——第一轮是元动作决策,第二轮是轨迹预测——两个轮次优化的是不同的目标。把同一个奖励撒给所有 token,就像给前锋和守门员发一样的奖金,显然不合理。
DriveMA 的解法很直接:每个轮次拿自己的奖励,做自己的归一化。
第一轮(元动作轮)获得 R_meta——衡量预测元动作与专家元动作的一致性。第二轮(轨迹轮)获得两份奖励的加权和:R_traj 衡量轨迹质量(在 WOD-E2E 上用 RFS,在 NAVSIM 上用 PDMS),R_cons 衡量语言-行动一致性。
一致性奖励的计算正是元动作可验证性的直接体现:将生成的轨迹投影到验证空间,将预测的元动作也投影到同一空间,然后比较两者是否一致。如果模型说了"右转",但轨迹几乎直行,就会收到低一致性奖励。
奖励在各自轮次内按组归一化后用于优势函数计算,来自不同轮次的奖励不会互相干扰。这让每个 token 收到的梯度信号都精确地对应它应该优化的目标。
SOTA 表现与消融实验的启示
在 WOD-E2E(Waymo 开放数据集端到端驾驶基准)上,DriveMA 全面刷新了记录。
DriveMA-2B 以 8.060 的 RFS Overall 分数登顶,在官方最具挑战性的 Spotlight 子集上也拿到了最高的 7.251 分,ADE@5s 降至 2.616。4B 版本进一步将纪录推至 8.079。在 NAVSIM 上,DriveMA 也取得了与 SOTA 端到端规划器相当的闭环规划性能,在 VLA 方法中保持领先。
消融实验讲述了一个清晰的故事。
直接做轨迹 SFT 的基线 RFS 是 7.741。引入元动作引导后,RFS 提升至 7.804——有用,但增益有限。加上动作中心预训练后,RFS 跃升至 7.893,Spotlight 子集提升尤其明显,说明驾驶领域决策知识的注入帮助模型更好地泛化到长尾场景。
最关键的跃迁来自 Turn-Level Credit Assignment RL。在相同的奖励信号下,它比标准 GRPO 的提升更显著:从 7.978 到 8.060。特别是在加入一致性奖励后,语言-行动一致性从 88.50% 飙升至 98.80%。这意味着模型几乎总是能做到"说到做到"。
数据效率的惊喜
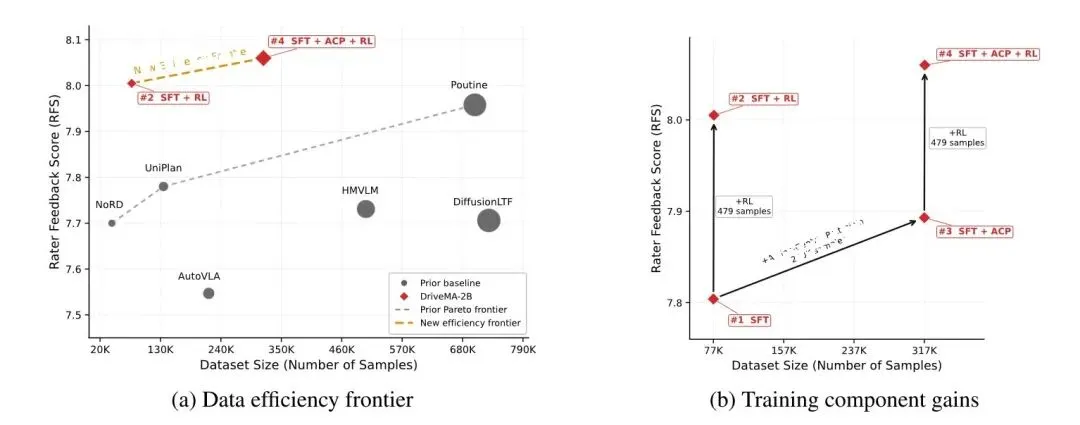
DriveMA 在数据效率上的表现同样令人印象深刻。
仅用 7.7 万个规划样本、479 个偏好样本和 24 万个动作中心预训练样本,DriveMA-2B 就达到了 8.005 RFS。相比之下,此前许多 VLA 方法使用了数倍乃至十倍以上的训练数据。
479 个 RL 样本就能将直接 SFT 从 7.804 提升到 8.005 RFS。可验证的元动作让每一条偏好反馈都能被稳定、高效地转化为规划能力的提升,而不是被淹没在序列级别的粗糙信号里。
元动作越细越好吗?
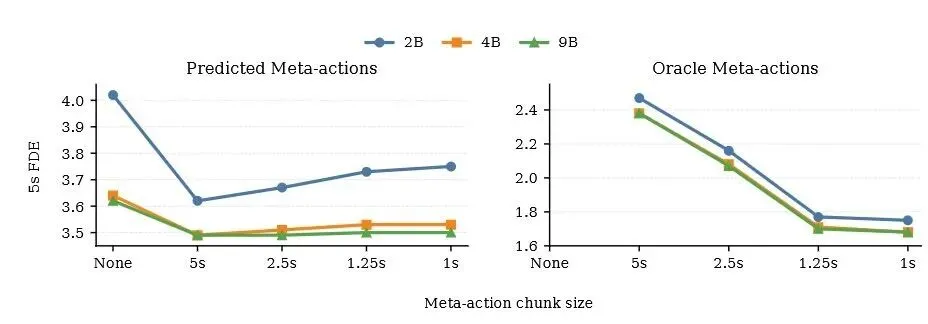
一个自然的疑问是:如果把元动作的时间粒度切得更细——比如从 5 秒一步变成 1 秒一步——会不会更好?
答案是:看谁在用。
当使用专家标注的"神谕"元动作时,更细粒度的动作确实能提供更丰富的中间引导,5 秒 FDE 持续下降。但当模型自己预测元动作时,性能在 5 秒单步粒度上就已经饱和了。
原因在于,更细的切分让纵向动作模式从 4 种爆炸到 221 种。决策空间越大,预测难度就越高。在 RL 对齐介入之前,瓶颈不在于元动作接口的"表达能力",而在于它的"可预测性"。
总结
DriveMA 的核心贡献不在于发明了一种新的动作词汇表,而在于充分挖掘了可验证性的价值。
元动作本身很朴素——四选一的纵向动作加粗粒度的横向意图。但当这种朴素接口配上轨迹驱动的自动标注、动作中心的领域预训练、以及精准到轮次的信用分配 RL 时,它展现出了惊人的潜力。
一个新的 SOTA、极致的样本效率、近乎完美的语言-行动一致性——这些结果来自同一个简单的元动作接口。
这也指向一个更普适的启示:未来的 Driving VLA,不必只盯着设计更丰富的语言接口。让中间语言状态变得可验证、可优化,或许才是弥合语言-行动鸿沟的真正关键。
研究团队承诺将开源代码、数据和模型。在更丰富的可验证接口出现之前,DriveMA 已经用实力证明了一件事:
简单,远未触及它的上限。