想象你正驾驶汽车抵达一个没有红绿灯的四向停车路口。
你减速、观察,发现右侧也有一辆车正在接近。谁先到?谁该让行?这个判断依赖的不是眼前的一瞬间,而是过去几秒钟里对那辆车位置变化的持续追踪。
如果你只记得最近一秒的画面,那你根本无法判断到达顺序。你可能会在应该等待的时候贸然驶出,也可能在拥有路权时犹豫不决。
这就是自动驾驶面临的核心挑战之一:决策往往依赖长时上下文中的关键信息,而非仅靠当前观测。
端到端的视觉-动作模型直接把摄像头画面映射为车辆轨迹,省去了感知-预测-规划的模块化流水线,在标准场景下已经相当成熟。但当历史上下文扩展到 5 秒甚至更久时,视觉 token 数量会迅速膨胀,轻松突破实时推理的计算预算。
怎么办?
一个直观思路是压缩。但现有压缩方法大多采用基于规则的启发式策略,比如"保留最近帧、丢弃较远帧"的时间衰减策略。这种做法完全脱离了规划目标,无法区分哪些历史信息对决策真正重要。
来自 NVIDIA Research 和香港大学的研究团队给出了一个更聪明的答案。
他们发现,问题的核心不在于"能不能压缩",而在于"压缩时该保留什么"。规则永远无法穷举所有长尾场景下的信息需求,但驾驶意图可以。
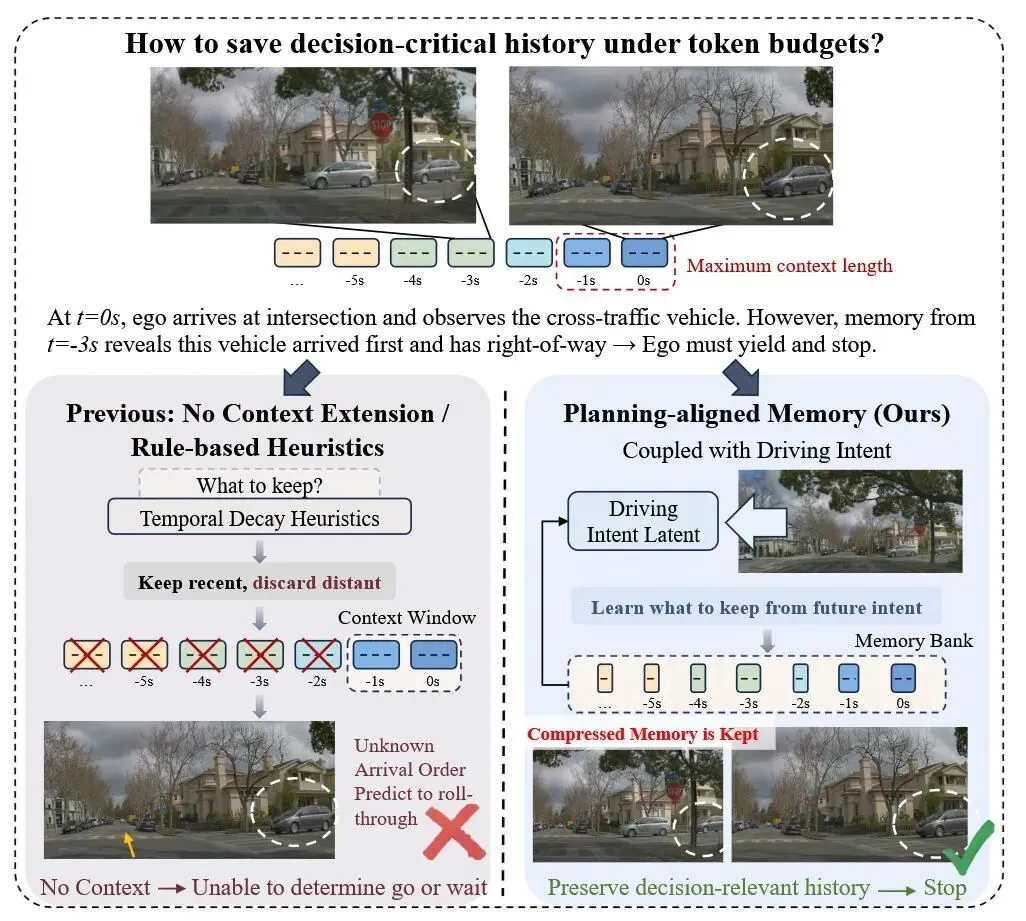
当时间衰减策略丢掉关键历史
先来看一个典型场景:四向停车路口。
在上图展示的四向停车路口场景中,一辆横向来车在 t=-3 秒时已经抵达路口,而自车在 t=0 秒才到达。根据规则,那辆车拥有优先路权,自车应该停车让行。
但如果你使用基于时间衰减的压缩策略,只保留最近 2 秒的观测,那么 t=-3 秒的关键信息就会被彻底丢弃。模型根本不知道有车先到了,它看到的只是一个"空路口",于是错误地决定继续行驶。
研究团队把这类场景称为高信号动态场景。它们的特点是:正确行为取决于离散决策的正确性——该停就停、该走就走——而不是轨迹的平滑度。在这类场景中,历史上下文中的某些关键帧往往比最近几帧更加重要。
传统指标如最小平均位移误差在这些场景下是错位的。一个"滚动停车"可能拿到很好的位移误差分数,但构成严重的安全违规。为此,研究团队设计了专门的行为指标:停车成功率、起步成功率、滚动通过率、停车位置误差和停车时长误差,直接评估决策层面的正确性。
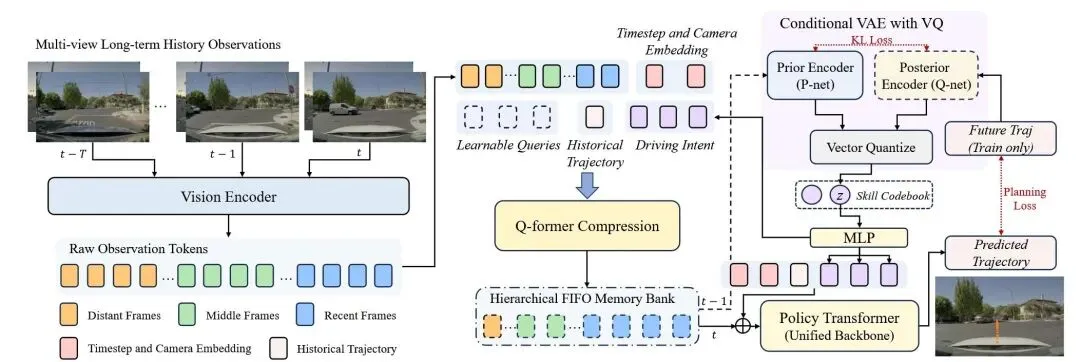
COMPACT-VA:让压缩对齐驾驶意图
研究团队提出的方案叫做 COMPACT-VA,全称是 Compression via Planning-Aligned Context Tokens for Vision-Action models。名字虽长,但核心理念非常清晰:用未来的驾驶意图来指导历史信息的压缩。
整体架构如上图所示,可以分成三个关键设计来理解。
第一层:分层记忆缓冲。历史观测不是被一视同仁地压缩,而是按时间远近分成三层。最近 4 帧保持完整 token 精度不压缩,中间 5 帧适度压缩,最远 11 帧大幅压缩。这种设计遵循了一个朴素的直觉:越近的观测通常越重要,但即使是最远的帧也保留了最低限度的信息密度,不会完全丢弃。
第二层:Q-former 可学习压缩。每一层的压缩不是简单的池化或采样,而是通过 Q-former 模块完成的。可学习的查询 token 与原始观测 token 一起通过自注意力机制,主动选择需要保留的视觉特征。压缩过程还以历史轨迹作为条件输入,让模型知道"自车过去是怎么动的",从而更聪明地判断哪些观测对象值得关注。
第三层:规划对齐的变分耦合。这是整个框架的灵魂。研究团队引入了一个条件变分自编码器框架,在训练时让一个后验编码器从未来轨迹中提取"驾驶意图隐变量",同时训练一个先验编码器从压缩后的历史观测中预测这个隐变量。通过 KL 散度损失,先验编码器必须学会从压缩记忆中推断出与未来行为一致的意图。
这意味着什么?
如果 Q-former 在压缩时丢掉了对决策至关重要的历史信息——比如那辆先到路口但被时间衰减策略忽略的车——那么先验编码器就无法准确预测后验编码器从未来轨迹中提取的驾驶意图。KL 散度会变高,轨迹预测也会变差。压缩质量和规划性能被绑定在一起,形成一个闭环的优化信号。
训练完成后,推理时只使用先验编码器。模型压缩历史观测、预测驾驶意图隐变量、通过向量量化映射到离散技能码本,然后将技能嵌入作为特殊 token 与压缩记忆拼接,送入策略主干网络进行自回归轨迹生成。整个过程不需要访问未来信息,却能从历史语境中读出"接下来该做什么"。
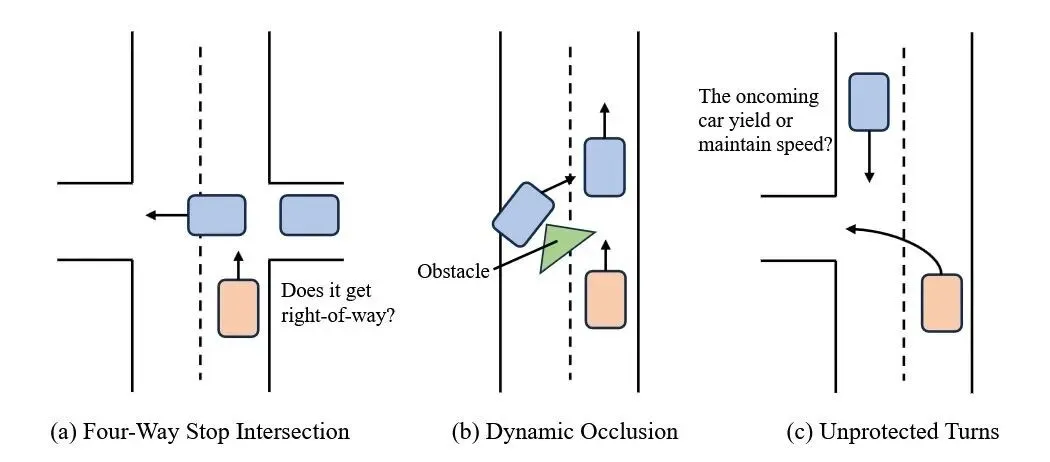
三类场景组成的决策考验
研究团队识别出三类对长时记忆依赖最深的场景,如上图所示。
四向停车路口要求模型追踪多辆车的到达顺序,正确协商路权。自车需要记住 5 到 10 秒前其他车辆的位置,判断自己在"到达队列"中的排位,然后决定是停车等待还是立即通过。
动态遮挡场景中,原本可见的交通参与者可能被其他物体遮挡或驶出视野。模型必须保持对它们状态的记忆,而不是仅凭当前可见对象做出判断。如果把一个被遮挡的路口误判为"净空",后果可能是灾难性的。
无保护转弯则需要在没有专用信号灯的情况下穿越对向车流。对向来车可能在几秒前开始减速让行,也可能保持速度直行。模型需要追踪对向车辆的轨迹变化,在有安全间隙时果断转弯,在来车不让行时耐心等待。
这三类场景覆盖了驾驶决策中最容易出错的环节。根据相关研究,间隙接受错误、路权判断失误和停车行为异常,合计贡献了约 40% 的路口事故。
实验结果:决策正确率的全面跃升
在所有实验中使用 5 秒共 20 帧的历史观测,原始 6400 个视觉 token 被压缩到 1424 个,与标准基线模型的 token 预算基本持平。
在这个公平的预算约束下,COMPACT-VA 取得了显著优势。
起步成功率从标准 Alpamayo 的 63.8% 跃升到 68.3%,绝对提升 4.5 个百分点。起步成功率衡量的是模型在获得路权后能否及时起步通行,它最直接地考验模型是否保持了足够的长期记忆来评估交叉车流和路权归属。
停车成功率也达到了 89.2%,比基线高出 2.4 个百分点。更关键的是,具有安全隐患的滚动通过率从 9.0% 降到 7.0%,相对下降 22%。这意味着 COMPACT-VA 不仅在"做对的事"上表现更好,在"不做错的事"上也更加可靠。
停车位置误差从 1.21 米缩小到 1.10 米,停车时长误差从 0.50 秒降到 0.48 秒。这些精细指标的改善说明压缩不仅保留了"要不要停"的信息,还保留了"停在哪里、停多久"的细节。
最有意思的对比来自"无规划对齐的压缩"变体。同样是 Q-former 压缩加上分层缓冲和轨迹条件,但去掉了变分耦合模块之后,起步成功率只有 65.6%。COMPACT-VA 加上规划对齐后额外提升了 2.7 个百分点。这 2.7 个百分点的增量,纯粹来自"让压缩服务于规划"这一设计选择。
反过来看,如果在 5 秒窗口内不做任何压缩、直接把 6400 个 token 喂给模型,起步成功率反而只有 61.9%,甚至不如只输入 1 秒数据的标准模型。这说明不加筛选的"信息轰炸"让注意力机制迷失在海量 token 中,二次方的注意力计算成本也阻碍了有效的时间推理。压缩不仅是效率需求,也是性能需求。
研究团队还在 910 个场景上进行了闭环仿真测试。COMPACT-VA 在碰撞率、平均事故间隔距离等关键安全指标上与 2 秒短上下文基线持平,同时实现了 3.3 倍的推理加速和 2.7 倍的显存缩减。在计算效率和驾驶能力之间,它找到了一个令人满意的平衡点。
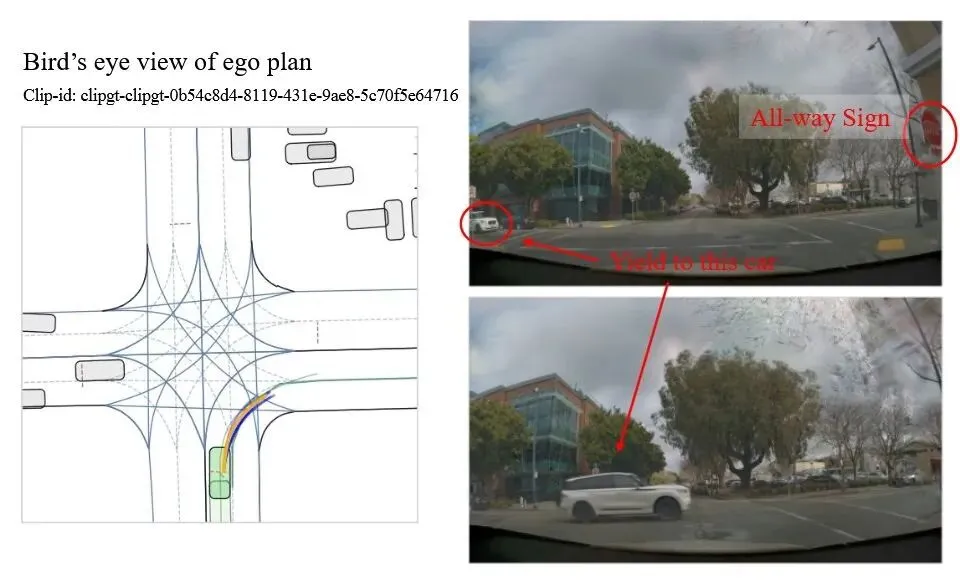
上图展示了一个闭环测试中的四向停车路口右转实例。COMPACT-VA 正确识别了路口的 all-way 标志,发现一辆直行车辆先于自车到达,于是减速让行。鸟瞰视角中预测轨迹很短,说明模型做出了"现在不该走"的判断。
消融实验揭示的细节
研究团队通过一系列消融实验验证了每个组件的贡献。
在分层压缩比例的实验中发现,最近 4 帧保持 160 token 的完整精度对性能至关重要。如果把最近帧也压缩到 80 token,起步成功率立即从 68.3% 跌到 64.6%。相反,中间层和中远层的 token 密度变化带来的影响较小,说明压缩的"梯度"——近处精细、远处稀疏——本身就是有效的归纳偏置。
在技能码本利用的分析中,模型在 20 个离散技能中稳定激活 15 到 17 个,码本利用率达到 80%。这意味着变分框架确实学到了多样化的驾驶行为模式,没有出现模式坍塌。不同的驾驶意图——停车让行、加速起步、缓慢蠕行——被自然地编码到不同的码本向量中。
在历史长度的实验中,5 秒 40 帧达到最高起步成功率 68.3%。延长到 80 帧时整体得分最高达到 78.6%,但起步成功率轻微回落至 68.2%。研究团队认为,这与基座模型预训练时接触的历史长度分布有关,微调只能在预训练分布附近寻找最优解。
为端到端驾驶模型装上工作记忆
COMPACT-VA 的核心贡献可以被提炼成一句话:把记忆压缩变成一个面向规划的可学习过程。
过去,端到端驾驶模型要么没有显式的记忆机制,只依赖最近几帧的观测;要么用规则驱动的衰减策略粗暴地裁剪历史。这两种做法都隐含了一个假设:记忆管理可以与规划任务分离。
COMPACT-VA 推翻了这个假设。它证明了让压缩模块感知未来的驾驶意图,能从海量历史观测中筛选出真正影响决策的那几条信息。这些信息可能来自 5 秒前一辆正在接近路口的车,可能来自 3 秒前被遮挡的行人,也可能来自刚刚开始减速的对向车流——规则永远无法穷举这些模式,但变分耦合可以学习它们。
这种"从未来看过去"的训练范式具有超越自动驾驶的潜力。任何需要从长时上下文中提取决策相关信息的具身智能系统——机器人操作、导航、人机交互——都可能从中受益。
当然,这篇工作在一般驾驶场景上的增益相对温和,主要战场仍然集中在记忆关键场景。研究团队展望了更高复杂度的场景,比如严重遮挡或多交通参与者的路口,初步观察表明这些场景中可能存在更大的提升空间。同时,循环记忆机制和状态空间模型等替代架构,也是将规划对齐压缩扩展到更广泛具身 AI 领域的可能方向。
给端到端模型装上一个有"取舍能力"的工作记忆,而不是一个只知遗忘的计时器——这或许正是通往更可靠自动驾驶的关键一步。




 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
