第一篇:“车辆到底在哪?”:自动驾驶定位算法的第 1 次数学进化
在自动驾驶定位与多传感器融合的算法世界里,所有的推导都始于一个最根本的问题:如何用数学公式,完美描述一辆车在一路上走对路线的概率?许多刚入行的同学常犯一个直觉错误:把一路上每个路口走对的概率直接相乘。这种方法忽略了车辆运动的时间连续性与因果依赖性。为了严谨地表达这种时空上的物理关联,概率论给出了绝对严谨的武器——贝叶斯链式法则(Chain Rule)。在自动驾驶状态估计中,车辆的位姿既受到我们“主动施加”或高频采样的物理动作(如 IMU 读数、轮速计里程等)的影响,又受到外部环境“被动感知”(如激光雷达、摄像头等)的约束。为了严谨建模,我们定义以下数学符号:利用贝叶斯链式法则(Chain Rule),在没有任何化简、完全无损的情况下,这个联合概率分布被严谨地展开为一条条件概率链:上述概率链的依赖历史会随着时间 T 的增加而无限拉长(例如 t 时刻的状态会受到前面所有状态、观测和输入的联合制约),导致计算量呈指数级爆炸。为了让工程能够落地,必须引入自动驾驶状态估计的两个基石假设:将这两个包含 u的核心假设代入无损展开的贝叶斯链式法则中,高维联合分布问题便实现了极为优雅的化简:经过马尔可夫和观测独立性假设化简后:
这个包含了 u的联合概率分布,由 IMU(状态转移) 和 LiDAR(观测似然) 共同构建的乘积链:在很多经典的 SLAM 论文或学术报告中,为了让公式显得清爽,作者往往会选择隐式表达(即在公式中直接省略 u。但作为写给工程师的硬核硬货,显式地把 u挂在条件概率的右侧,不仅逻辑上毫无破绽,更能帮助初学者一眼看清 “IMU 数据到底在概率公式的哪一项里起作用”。💡 总结:第 1 次数学进化的本质
自动驾驶定位算法的第一次进化,成功将“车辆在哪”的哲学思考,规范为了标准的数值矩阵优化问题。它在空间与时间交织的因果链条上,为后续所有的滤波器(KF/EKF/UKF)与现代因子图(FGO)算法奠定了坚实的数学根基。


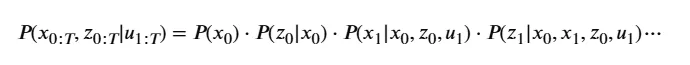



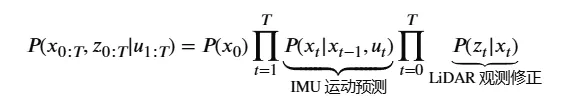





 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
