纯视觉自动驾驶系统有多不容易? ——Autopilot assist app系统破解后的识别结果展示 (4)
- 2026-07-11 08:18:06

北方话讲“不出十五都是年”,所以正值牛年新春,车右智能恭祝各位公众号的读者新春快乐。小编个人虽然来晚了,但还是要套个流行语,“想死你们了~~~大家过年好!”希望鼠年的诸多不顺,在蓬勃向上的牛年统统消散不见,留下的只有努力和奋进,国泰民安一日千里。
本期文章我们还是接着上期关于Autopilot系统的视觉识别结果(autopilot assist App破解)继续分析,因为间隔时间比较长了,建议读者可以顺着这个专题(相同的副标题)往回翻一翻。顺着上次的内容先上图,承上启下:
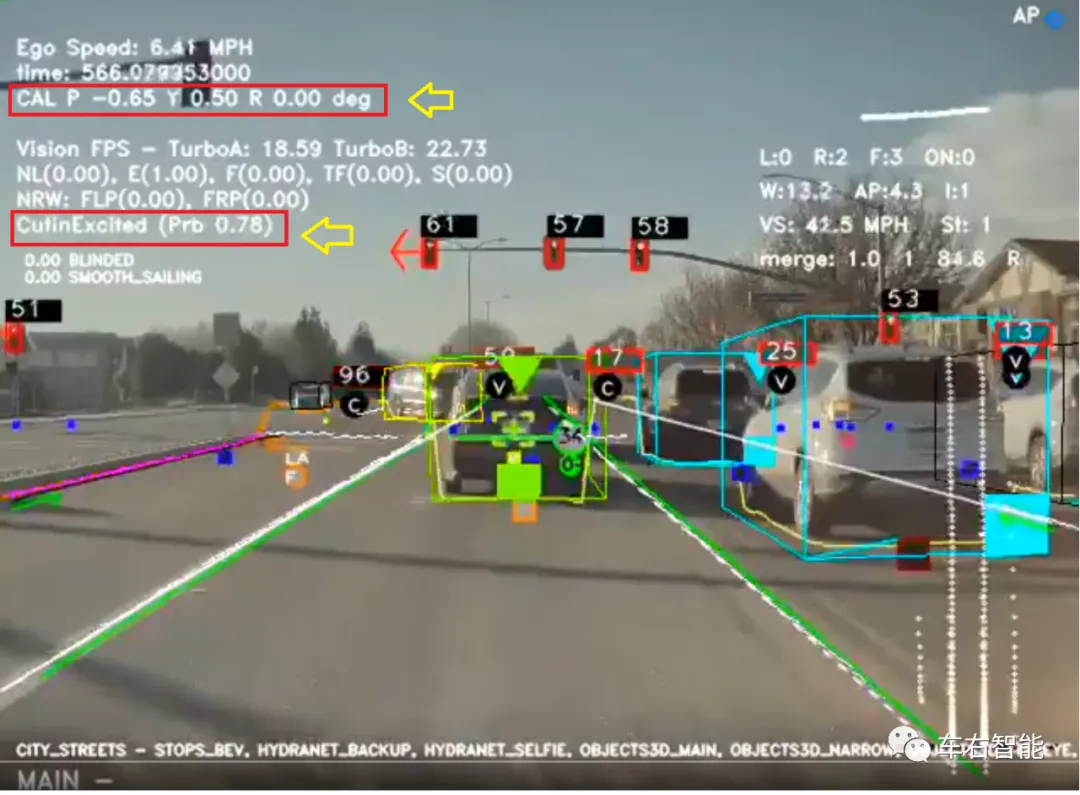
上图Autopilot assist app UI中的白色文字部分,前期文章有过对应的介绍,小编在两个地方圈了红框,主要是出于以下补充介绍:
1 CAL PitchYaw Roll(分别代表P俯仰、Y偏航和R滚转的三自由度)所代表的姿态信息,可能是我们之前理解错了。因为这个数据在整个行驶过程的记录信息中(时长为1分钟),一直保持是没有变化的固定值。上一期文章当时我们推测是系统并未引入这个车体姿态信息,因为车体的姿态信息(通常理解是相对于大地坐标)是不可能在长时间驾驶过程中保持不变的,因为路面是不可能没有起伏的。但实际上,后来分析,我们更认为这是主传感器中(页面底部显示当前的主传感器是Main Camera)的摄像头坐标体系在车体坐标系下的相对位置。这样就可以解释为什么PYR指标一直保持不变了,因为车辆出厂之后,摄像头等传感器的安装位置即是固定的,只要安装误差足够小,就可以保证摄像头所测量的信息可以被准确投影到车体坐标系内,或者大地坐标系内,从而完成对于外部交通信息的感知和对于车体的运动控制合理可靠。请参考下图:
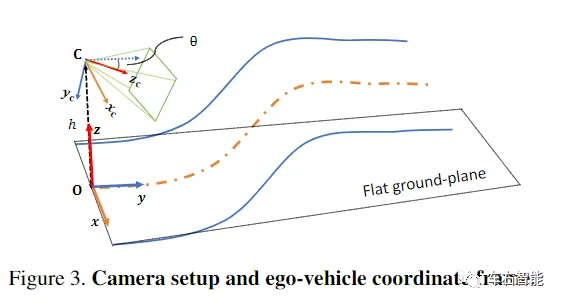
上图中的OXYZ代表车体坐标系,而CXcYcZc代表摄像头坐标系,上图的θ角,即为摄像头在车体上的设计安装角度。自动驾驶系统中,传感器在车辆出厂前的安装和标定过程可能是很复杂的,因为传感器数量众多,且异构性很强,又有标定过程本身成本不应该太高的具体限制。但对于我们这里对问题的讨论来说,在原理上又是很简单的,基本是属于摄像头的外参标定,只要标定结果小于设计误差的容限,即可固定出厂。所以这也就是为什么我们在UI上看到这个外参固定不动的原因。
2 关于CutinExcited(Pro 0.78),是一个闪现值,不会始终出现在UI中。但根据小编的观察,在车辆运行到路口红灯前降速滑入等待状态的过程中,Cut-in的预测总是很活跃地闪现。根据之前Karpathy演讲的公开资料,Autopilot中对于相邻车道行驶车辆是否会执行Cut-in操作的判断并非由代码固化人类经验来判断,而是完全有DNN神经网络来做判断,换句话说,Cut-in Excited指标的高和低,是由模型给出。我们可以做个设想,当邻道车辆密集且保持一定的速度范围,也有可能还带一些小幅度的偏转驾驶轨迹……往往就是现实世界中发生大量换道操作的时机,因此被训练出来的DNN模型,就会在这种场景下高频次输出Cut-in Excited的高置信率指标就不足为怪了。
如果我们考虑实际针对视觉处理的速度高达20FPS,即每秒钟20帧,这种误判可能并不会影响真实的车辆控制输出(比如引发顿挫感的减速)。当然这只是一个推测,作为一个控制系统中最核心的指标——控制周期,我们并不掌握Tesla的秘密,控制周期决定Autopilot执行如何根据对于其他目标的“轨迹预测”,而进行自车运动轨迹控制的节拍。
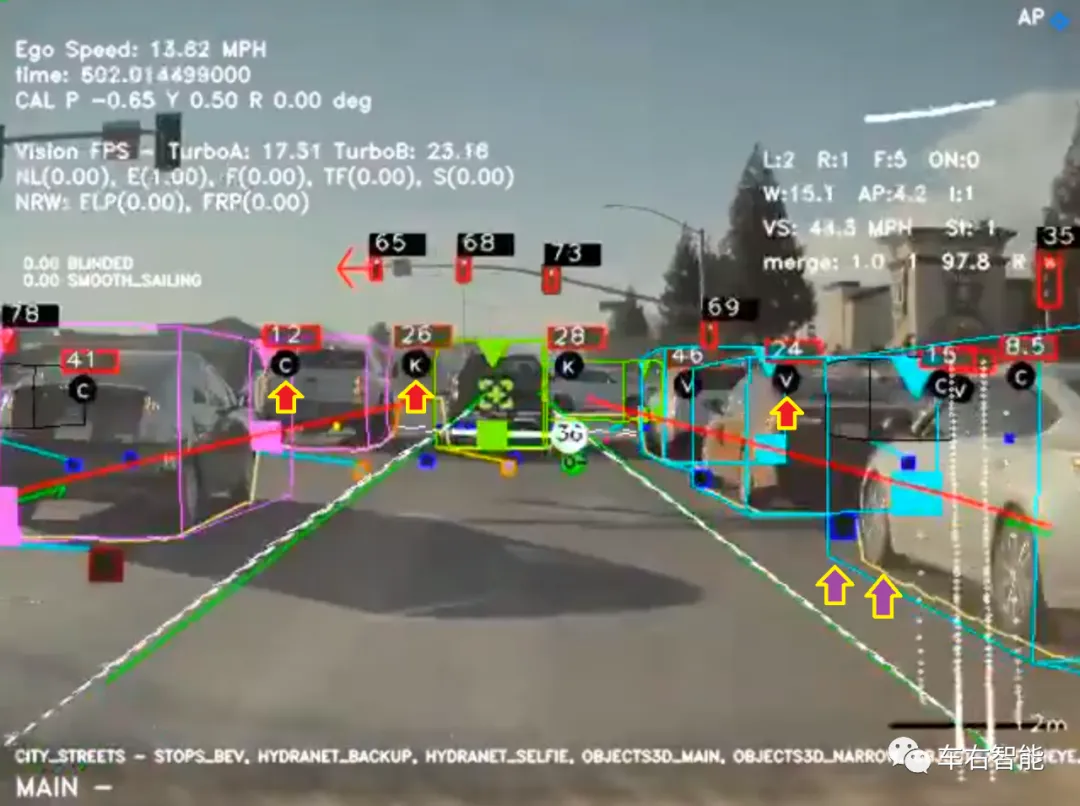
上图所包含的视觉识别结果信息量较多,分别如下:
1 红色箭头,对于车辆种类的分类识别,包含三类(可能更多,此视频截图中包含三类):C=Car代表日常的乘用小型车辆;V=Van代表小型箱式送货车,根据视频中的分类看,小编感觉基本上代表国内所指的SUV这类别的车辆;K=PicKup,代表皮卡,这是美国相当普遍的车辆大类。可能这里还少了大型客车(公交车辆)和其他特种车辆的分类。对于车辆的类别识别和区分,是视觉系统的强项,分类的准确性还可以影响到对于车辆外廓(特别是高度)的视觉识别校准。关于Autopilot的细节内容我们掌握的很少,但是根据Apollo Lite视觉系统的公开资料,我们可以看到对于交通目标的分类,是如何促进对于目标的3D信息预测准确度提升的(后续介绍)。
2 红色箭头,在车辆的分类结果之上,Autopilot给出预测的关键3D信息——距离信息。距离信息的估算来源可能由两部分组成,一部分是视觉识别和预测的结果,两一部分是毫米波雷达的测量结果。注意这里的差别,一个是“预测”,另一个是“测量”,所以不难想象这两部分测距数值上的差异。

上图为一个Autopilot自动驾驶状态下的事故回放画面截图,来源于美国一个自发性的民间搜集Tesla车辆事故信息的网站。在画面中我们可以看到车辆识别框顶部为视觉识别模型所预测的距离结果,而底部则为毫米波雷达对于车辆的距离测量结果。很明显有距离上的差距:左侧车辆视觉识别15.6m,雷达测量结果13.13m;右侧车辆视觉识别21.9m,雷达测量结果18.92m。
按照小编的理解,由于传感器的工作特性差异,导致毫米波雷达是测量被测物体的反射面回波距离,因此如果是处于主车正前方的其它目标车辆,最有可能是汽车尾部(后备箱外盖)所反射的回波距离;而对比之下,视觉系统和神经网络DNN所预测的其他目标车辆的距离,则应该是车体立体的外轮廓框尾部距离主车的距离。如果是更为简单轻便的二维视觉识别矩形,则应该对应的是主车坐标中,所能识别出的目标车辆的最大轮廓刨面距离主车的视觉距离。这两个距离必然是有差异的。小编倒是很好奇Autopilot最终的控制参数中选择了相信哪个距离指标?还是做了加权处理?
3 紫色箭头,上图中的紫色箭头指出了两个关键的视觉识别结果。一个是立体的车辆外轮廓包围框,另一个是车辆轮胎的接地轮廓线(黄色)。基于单目摄像头的3D目标识别方法,就在神经网络的框架中,就有N多种方法了,我们在这里也没有必要猜测Autopilot的具体识别方法到底是哪一种,线索非常有限。
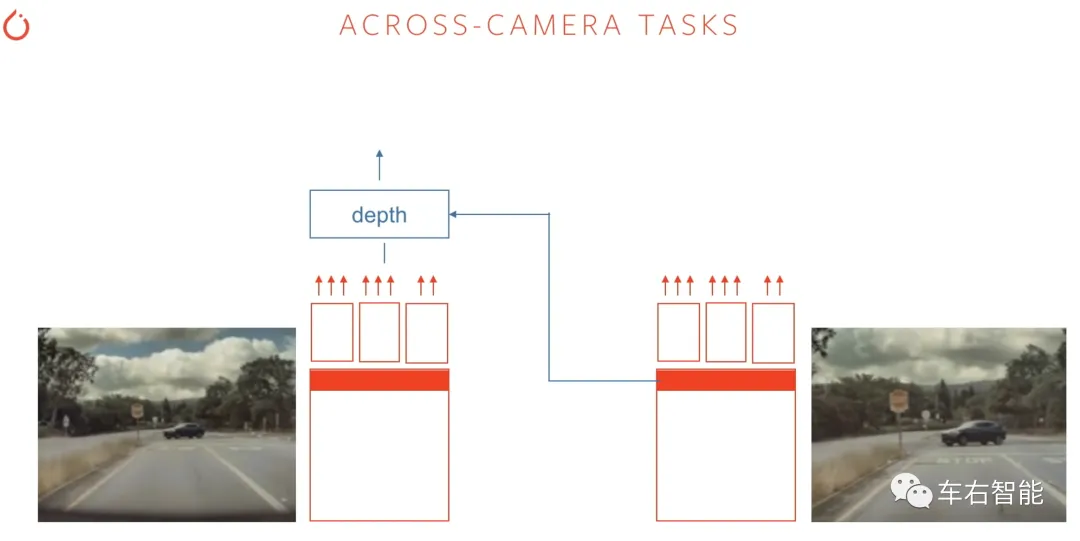
据小编所知,一个是CNN采用了ResNet-50结构,另一个是识别目标距离时,会使用多个摄像头的特征结果进行距离预测,如下图。这是一个所谓的“Across CameraTasks”,两个焦距不同的前向摄像头,在各自的主干CNN给出的特征图基础上,经由Depth模型(DNN模型)给出目标的距离预测值。我们推向模型训练的真值,是以毫米波雷达的测量值为基础的。
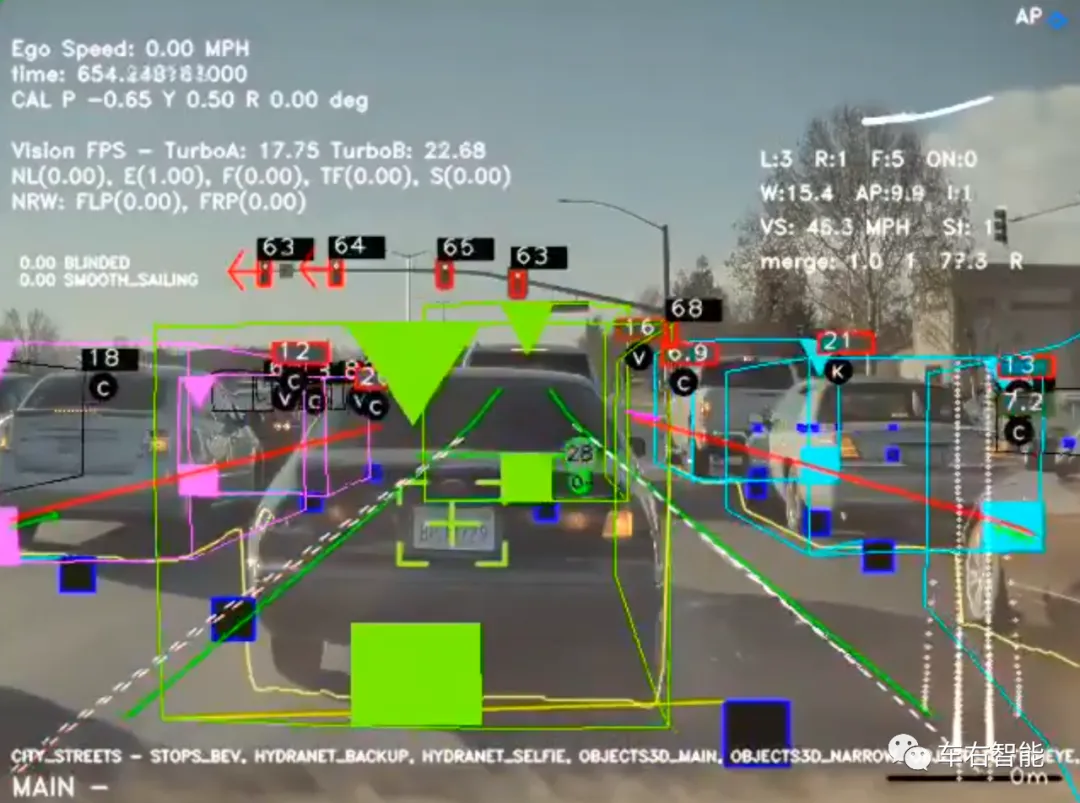
参考上图,我们可以看到Assist app中,对于主车车道前方、左侧和右侧相邻车道的识别显示,通过颜色进行区分:左侧为紫色、中间为绿色、右侧为天蓝色。视觉识别框为3D立体,在尾部有明确的顶部和底部标识符,底部为实心正方形,而顶部为绿色三角形。对于道路参与目标的视觉识别,是所有自动驾驶视觉识别系统的核心技术。我们在这里只能看到Autopilot的识别结果,貌似内容还是比较丰富,而且解决了最基本的外界目标3D信息(包含3D轮廓和距离主车的距离),甚至对于交通灯的语义识别也可以做到:上图顶部,Autopilot可以区分出左转灯和直行灯,如果这些都是实时识别结果,那就太强大了。感觉还是有结构化的道路设施地图在起作用,但别误会,肯定不是高精地图。以后我们会找专门机会做个介绍和推测分析。
另外还有个关于毫米波雷达的测量结果的展示细节;需要我们关注,如下图:
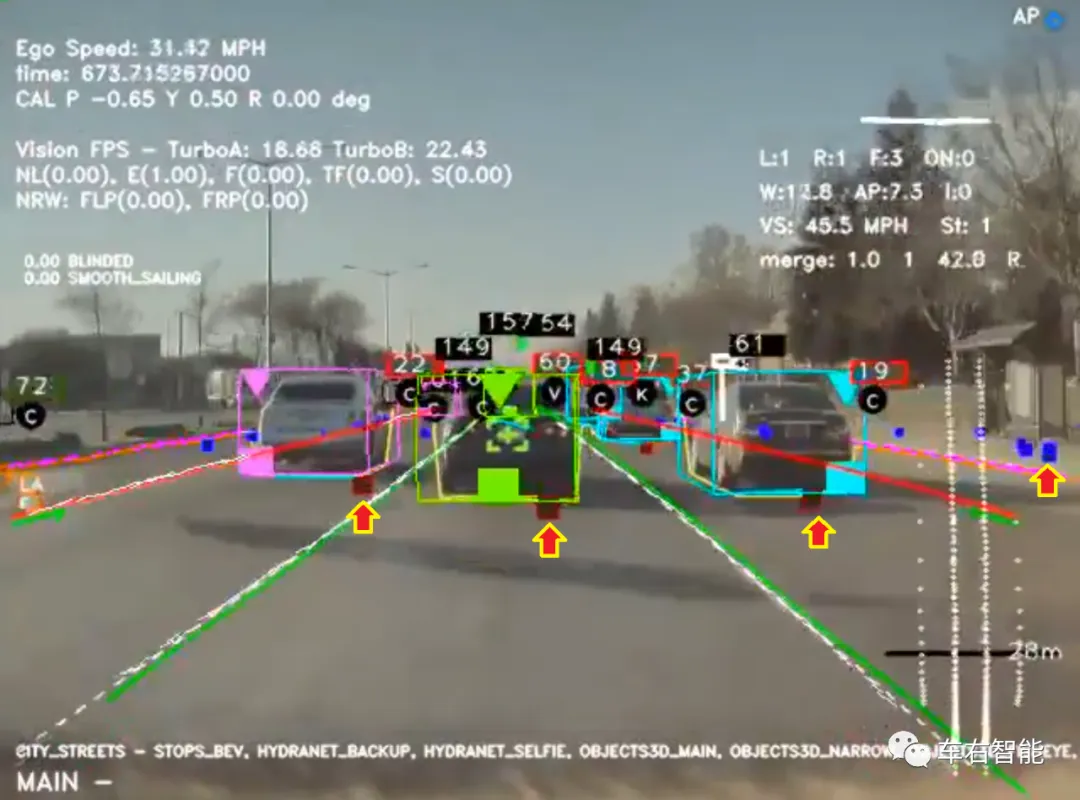
上图中的红色箭头所示,为每个运动目标车辆都会有的一个赭红色的实心方框,如果读者参见再上一幅图,可以看到当主车和目标车辆都停在路口处于静止状态等待红灯时,这些方框将转变为黑色实心方框。这个颜色差异,代表在运动状态下,毫米波雷达可以锁定目标车辆,但静止状态下,则无法区分地面杂波和路边干扰物回波和目标车辆之间的差别,则统一转为黑色方框。
另,关于目标车辆识别,在上期文章中我们提到了Apollo Lite的视觉识别系统,相关的技术文章其实也就看到一篇,但是百度的相关专利和技术文章都是可以查到的,所以资料更多一些。小编这里把相关内容再贴一次,因为对于我们理解和推测Autopilot视觉系统的能力到底如何非常重要。Tesla目前的公开信息集中在Autopilot大系统的训练和实现方法的介绍上,对于具体的网络模型和结构基本没有涉及。而Apollo Lite这方面的信息和公开技术论文就比较多一些,比如下图是整体的Apollo Lite的视觉识别DNN网络框架:
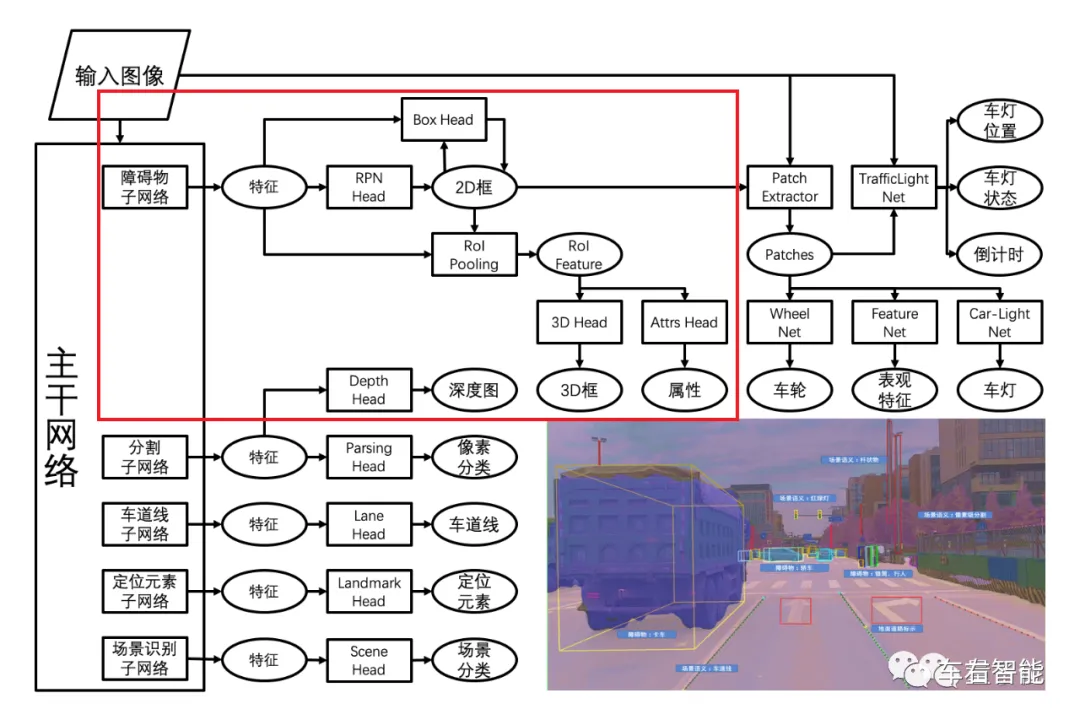
大体上,这是类似Autopilot的多任务DNN网络架构,即分为主干网络/Backbone Net和头部网络/Head Net的总分结构,设计目标是在网络规模和准确性、多样性之间找平衡。小编在图中圈出的红色方框部分,为我们最关心的道路其它参与车辆目标的识别架构。这是一个CNN为主干,RPN为Head,率先识别并圈出2D的目标框,再在RoI(Region ofInteresting兴趣区域)内利用3D Head进一步勾勒(也就是预测)出目标车辆的3D结构信息的方法。在下面小编重贴的这段文字描述中,详细论述了Apollo Lite从训练(利用Lidar测量结果构造真值和训练集,最终训练纯视觉系统的具体过程),非常值得一读。
【以下内容来自百度Apollo Lite技术文章“百度背叛激光雷达路线了吗?”一文中相关章节的引用。URL:https://mp.weixin.qq.com/s/_TJfWd605OK7mO736yufPg】
======
传统算法计算2D检测框的框底中心后通过道路平面假设和几何推理物体深度信息,这类方法简单轻量,但对2D框检测完整性和道路的坡度曲率等有较强的依赖假设,对遮挡和车辆颠簸比较敏感,算法欠缺鲁棒性,不足以应对复杂城市道路上的3D检测任务。Apollo Lite延续「模型学习+几何推理」框架同时对方法细节进行了大量打磨升级。
模型学习 – 数据和学习层面,利用激光雷达的点云数据【小编注:Apollo Lite在训练阶段时需要Lidar数据辅助进行监督训练的,实际部署时属于单纯的视觉系统】将2D标注框和3D检测框关联,在标注阶段为每个2D包围框赋予了物理世界中的距离、尺寸、朝向、遮挡状态/比例等信息。通过从安装相同摄像头(Camera configuration)并配备高线数激光雷达的百度L4自动驾驶车队获取海量时空对齐的「图像+点云」数据,训练阶段DNN(Deep neural networks)网络模型从图像appearance信息做障碍物端到端的三维属性预测,模型端完成从仅预测2D结果到学习2D+3D信息的升级,将传统“几何推理”后处理模块的任务大程度向模型端前置【小编注:将几何推理的计算力消耗和对于多样性场景的处理压力,统统转交给DNN网络,是现在无可争议的技术趋势。】,“深度学习+数据驱动”为提升预测效果提供了便捷有效的路径和更高的天花板。在添加模型端3D预测能力外,为给后续几何约束阶段提供丰富的图像线索,针对不同位置/朝向相机的安装观测特性,模型从学习障碍物矩形包围框拓展到预测更多维度更细粒度的特征,如车轮和车底接地轮廓线。
几何推理–将模型输出的图像视觉特征作为观测值,障碍物空间位置朝向和尺寸作为未知参数,基于相机姿态和经典投影几何(Projective geometry)可计算3D到2D的投影。理想条件下3D元素投影到相机的坐标和2D特征观测应该重合,由于3D信息预测误差的存在,模型输出3D投影和2D图像观测会存在一定偏差,几何推理的作用是通过场景先验和视觉几何原理对模型输出的障碍物3D初值进行优化,以此得到2D-to-3D的精确结果。投影计算方程依赖对相机的姿态进行实时估计,理想情况假设相机水平安装,视线与路面平行,俯仰角接近为0°。车辆行驶中,受地面坡度起伏影响,相机相对地面的姿态不断变化,精准估计车辆运动中相机俯仰角是求解3D-to-2D投影的必要条件,我们称这个步骤在线标定。【小编注:根据这里的技术描述,在2D到3D的过程中,Apollo Lite还是需要一个标准的几何过程,而非Tesla Autopilot系统中所采用的双焦距-双摄像头的DNN方法。】Apollo Lite在线标定算法并不依赖高精地图,通过学习道路上线状特征如车道线和马路边沿,拟合出多条空间中的平行线在图像投影上的交点 — 消失点(Vanishing point),基于透视几何原理,可精确估计车辆行驶中相机俯仰角的实时变化的情况。
经过精细化打磨的2D-to-3D算法显著提升了Apollo Lite在复杂城市道路下的自动驾驶能力和乘坐体验,因“3D位置估计不准”衍生的驾驶策略缺陷如碰撞风险、急刹等事件发生频率大幅降低,与之相关的接管频次和急刹频次指标分别下降90%和80%,200m内车辆距离估计平均相对距离误差低于4.5%,行人与非机动车平均相对距离误差低于5%。
======
车右智能
一个一直用心仿真的自动驾驶技术信徒
info@co-driver.ai
备注:
1 题图来自互联网搜索;
2 文中插图1/3/6/7来自于推特账户@Green的推文的截图;
3 文中插图2来自于CSDN关于百度GenLaneNet的论文分析文章,URL:https://blog.csdn.net/weixin_39550937/article/details/111380954;
4 文中插图4来自于推特账户@Green的推文的截图;
5 文中插图5来自于Karpathy关于“PyTorch at Tesla”的演讲截图, URL:https://www.youtube.com/watch?v=oBklltKXtDE&t=299s;
6 文中插图8来自于公众号“悦智网”的技术文章“百度背叛激光雷达路线了吗?”中的插图,URL:https://mp.weixin.qq.com/s/_TJfWd605OK7mO736yufPg;

