第一次认真把这篇论文从头到尾读完,我脑子里一直冒出一个很人类的问题:我们开车的时候,真的会“看见”一切吗?
答案显然是否定的。人开车时,注意力高度集中在车道线、前车、行人、红绿灯这些“要命的东西”上,而天空是不是蓝的、路边是哪栋楼,说实话,大脑根本没空处理。但今天的大多数自动驾驶模型,偏偏是个“老实人”——摄像头拍到什么,它就老老实实全算一遍。这正是小鹏团队这项研究要解决的核心矛盾:算得太多,反而算不快、算不好。
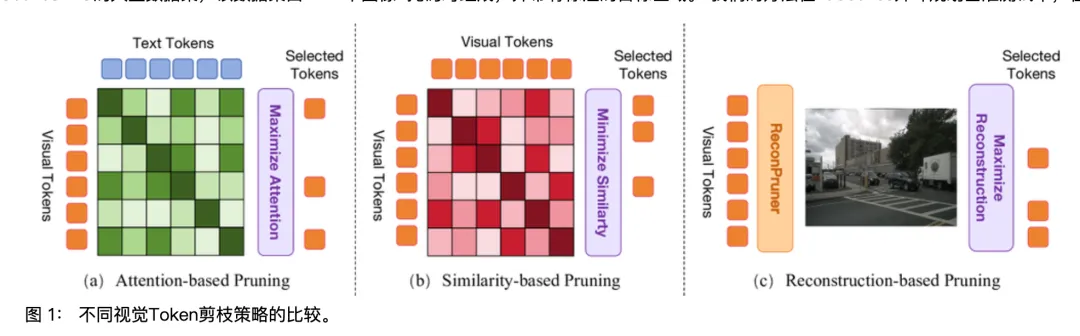
在论文里,作者把现在主流的视觉-语言-动作模型(VLA)描述成一种“什么都想看”的系统。一张行车画面被切成几千个视觉 Token,相当于把一张照片拆成几千块拼图,不管是车、人、路,还是天、树、楼,全都送进模型的大脑一起算。
结果很直接:计算量爆炸,推理延迟变高,离真正能上车跑的实时系统还有距离。FastDriveVLA 的出发点非常朴素——既然人会选择性注意,模型能不能也学会“只看重点”?
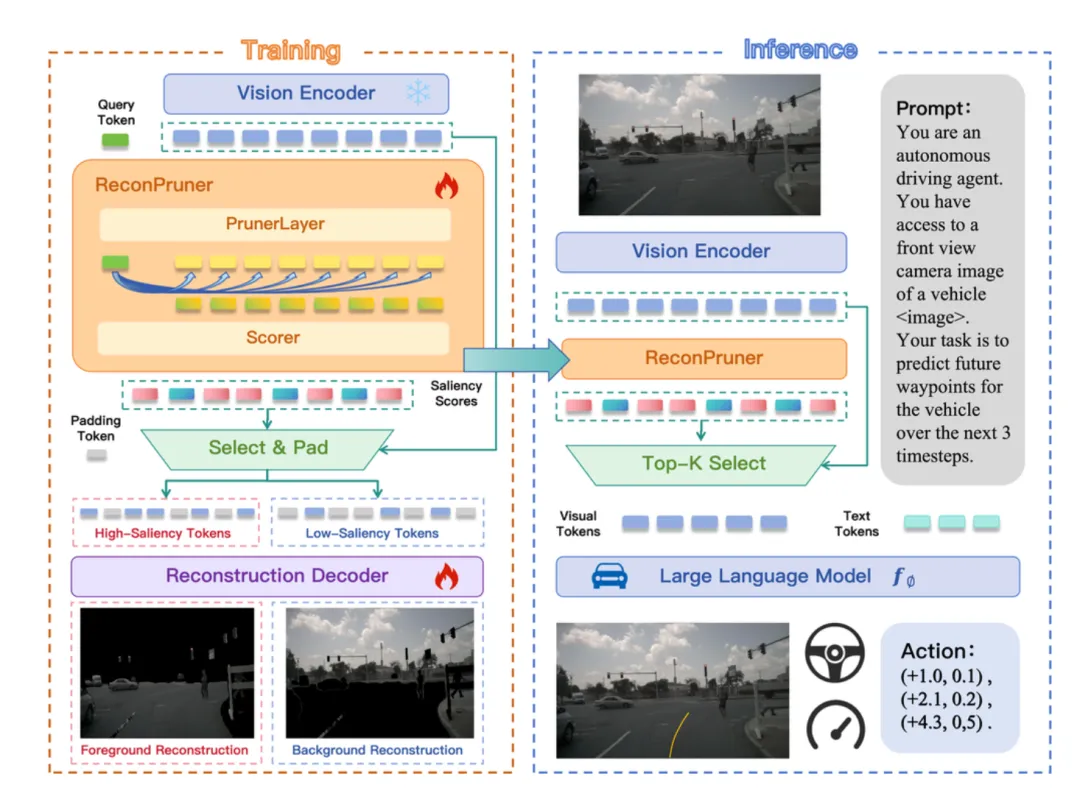
于是论文提出了一个非常形象的思路:让模型学会“扔垃圾”。但这里的垃圾不是没用的数据,而是对驾驶决策几乎没有帮助的信息。比如天空、远处的建筑、路边的树,这些在大多数情况下,对“下一秒该不该刹车”“要不要变道”帮助极小。问题在于,怎么教模型分清“干货”和“背景”?这就引出了论文里最核心的组件——ReconPruner,一个专门负责给视觉 Token 打分、做取舍的“分拣员”。
ReconPruner 的设计让我印象很深,因为它并不是简单用规则硬切,而是通过“重建”来学会判断价值。作者把一张图像拆成大量 Token 后,先让 ReconPruner 给每个 Token 打一个“重要性分数”。分数高的留下,分数低的准备扔掉。但光打分不够,万一它偷懒,所有 Token 都打高分怎么办?于是作者设计了一个非常巧妙的训练方式——前景-背景对抗重建。
这个训练过程可以理解成一个“拼图游戏”。系统会要求:你用“高分 Token”去重建前景画面,比如车、路、行人;同时,用“低分 Token”去重建背景画面,比如天空、建筑。如果你把该留的前景 Token 扔了,前景重建就会失败;如果你把背景 Token 留太多,背景重建反而会太好,也要被惩罚。
通过这种对抗式训练,ReconPruner 被逼着学会真正区分:哪些 Token 是“对驾驶决策不可替代的”,哪些只是视觉噪声。
让我觉得这项工作很工程化、很“能落地”的一点是:ReconPruner 非常轻量,而且是即插即用的。
它本身只有 0.07B 参数,相比动辄几十亿参数的 VLA 模型,几乎可以忽略不计。更关键的是,它不需要重新训练整套自动驾驶模型,只要视觉编码器一致,就能直接插到不同的 VLA 前面用。这对真实车端部署来说非常重要,因为重训一个大模型的成本,往往是不可接受的。
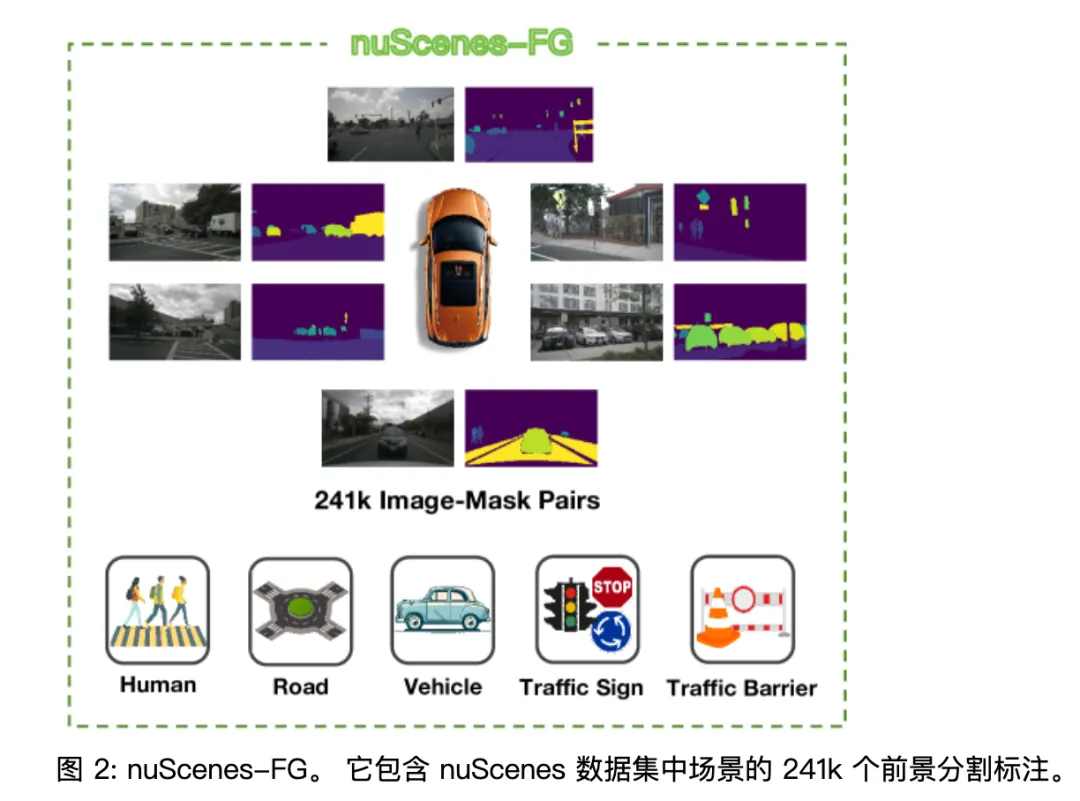
为了把这个“分拣员”训练好,小鹏团队还专门构建了一个新的数据集——nuScenes-FG。他们重新定义了“驾驶前景”的概念:人、车、道路、交通灯、交通标志,统统算前景;天空、树木、远处建筑,统一算背景。然后用 Grounded-SAM 在 nuScenes 上生成了 24.1 万张带前景掩码的图像。
这一步非常关键,因为它让模型第一次有了系统性区分“驾驶相关视觉信息”和“无关视觉信息”的监督信号。
论文里最让我信服的,是那一大堆看起来有点枯燥、但非常实在的实验结果。简单说一句话概括:Token 砍掉一半,车反而开得更稳了。
在剪枝 25%、50%、75% 的多种设置下,FastDriveVLA 在轨迹误差、碰撞率、越界率等指标上,几乎全面优于基于注意力或基于相似度的剪枝方法。甚至在 25% 剪枝时,某些指标还超过了“完全不剪枝”的原模型。这其实验证了一个反直觉的事实:信息不是越多越好,关键在于有没有把注意力放在对的地方。
从效率角度看,提升更是直接。视觉 Token 从 3249 减到 812,FLOPs 降低了约 7.5 倍,预处理延迟快了 3 倍多。换句话说,原来模型像是在一秒钟里解七道数学题,现在只用解一道,而且答案还更准。这对自动驾驶这种“毫秒级决策”的系统来说,价值不言而喻。
论文后半部分的大量消融实验,其实也在不断强调一个结论:光知道“前景在哪”还不够,必须让模型学会“前景里谁更重要”。
如果只用二值掩码,模型无法区分“车”和“路边锥桶”的相对重要性;如果没有对抗性的背景重建,模型很容易偷懒,把所有 Token 都打高分。
FastDriveVLA 的价值,就在于它通过重建任务,把“重要性判断”这件事,交给了模型自己去学,而不是工程师手写规则。
读完这篇论文,我最大的感受是:这不是一篇炫技的模型论文,而是一篇非常“懂驾驶”的系统论文。
它没有一味追求更大的模型、更复杂的注意力机制,而是回到了一个看似简单、却长期被忽略的问题——在自动驾驶里,什么信息才真正值得算?小鹏团队给出的答案是:让模型像人一样,把算力用在刀刃上。
如果说过去的 VLA 模型是在“睁大眼睛拼命看”,那 FastDriveVLA 更像是在教它“眯起眼睛,看重点”。这一步看似是“偷懒”,但实际上,是通向真实落地自动驾驶的必经之路。