在自动驾驶、机器人感知等关键领域,红外-可见光图像融合与语义分割是场景解析的核心技术。可见光图像细节丰富但依赖光照,红外图像可穿透低能见度环境却分辨率低,如何让二者优势互补,同时实现高质量融合与精准分割?近期发表于TIP 2025的MAFS模型给出了答案——首次将知识蒸馏引入融合与分割联合训练,用掩码自编码器+多任务协同策略,实现了两大任务的双向赋能!
unsetunset论文信息unsetunset
题目:MAFS: Masked Autoencoder for Infrared-Visible Image Fusion and Semantic Segmentation
用于红外-可见光图像融合与语义分割的掩码自编码器
作者:Liying Wang, Xiaoli Zhang, Chuanmin Jia, Siwei Ma
源码:https://github.com/Abraham-Einstein/MAFS/
unsetunset一、研究背景:融合与分割的“各自为战”难题unsetunset
传统红外-可见光图像融合方法仅聚焦于生成视觉效果好的融合图像,却忽略了与下游语义分割任务的联动;而现有的多任务学习方案多采用级联架构,将融合图像直接输入分割网络,不仅容易导致性能损耗,还无法平衡两个任务的训练难度。
更关键的是,现有方法要么从微观网络层面设计交互模块,要么单纯追求单任务性能,从未从宏观任务层面探索像素级融合与特征级分割的相互促进潜力。针对这些痛点,MAFS模型应运而生。
unsetunset二、MAFS核心创新:四大突破点重构多任务学习框架unsetunset
1. 首次引入知识蒸馏,实现任务级相互促进
MAFS构建了“教师-学生”双模型架构:教师模型包含融合子网络和分割主干网络,其输出的逻辑图(logits maps)作为软标签,指导仅包含分割网络的学生模型训练。这种设计跳出了传统级联优化的局限,让融合任务的知识能够迁移到分割任务中,反之分割任务的语义信息也能反哺融合效果。
2. 两阶段自监督训练:掩码自编码器夯实特征基础
MAFS的训练分为两个阶段:第一阶段利用多模态掩码自编码器(MAE) 做自监督预训练——通过掩码图像的部分区域并重建,让网络学习到丰富的跨模态特征表示;第二阶段基于预训练的高质量初始化,开展融合与分割的多任务联合训练,大幅提升了网络的特征学习效率。
3. 渐进式异构特征融合:让融合图像“懂语义”
针对融合任务,MAFS设计了PHF渐进式异构特征融合模块:将浅层纹理特征(保留细节)与分割网络的深层语义特征(蕴含场景信息)自适应融合,生成的融合图像不再只是“视觉好看”,更具备强语义感知能力,大幅降低下游分割任务的难度。
4. 动态权重因子:平衡任务训练难度
融合任务相对简单,分割任务复杂度高,二者损失幅度差异大易导致训练失衡。MAFS引入基于最大最小公平原则的动态权重因子,能自适应调整两个任务损失函数的权重,确保多任务训练的平稳性与有效性。
unsetunset三、MAFS整体框架:从特征融合到多任务输出unsetunset
MAFS的核心框架(图1)打破了传统级联架构的桎梏,实现了融合与分割的并行协同:
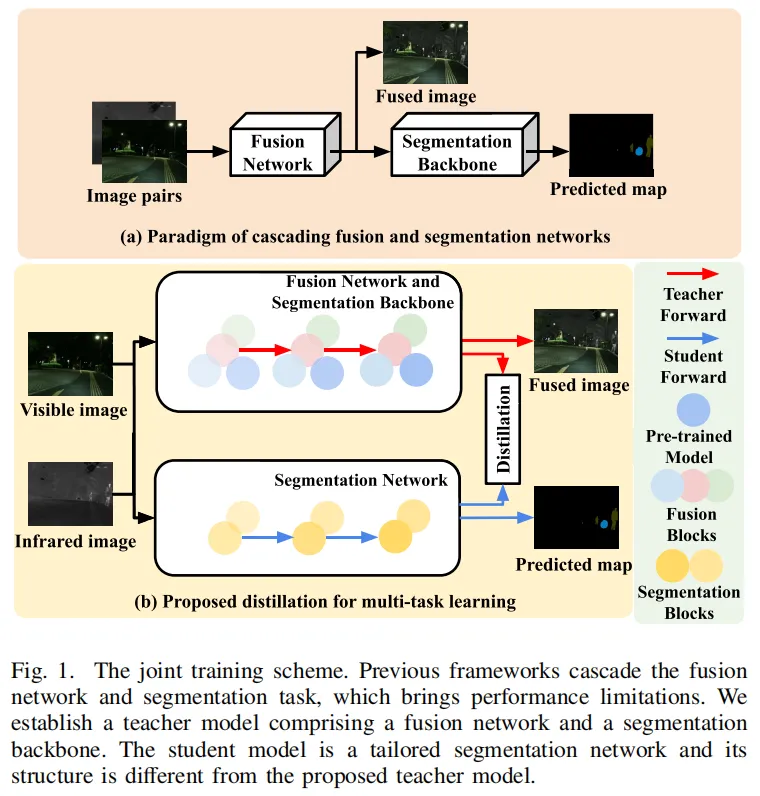 图1:MAFS框架(b)与传统级联架构(a)对比,可见MAFS的教师-学生蒸馏范式与并行多任务设计
图1:MAFS框架(b)与传统级联架构(a)对比,可见MAFS的教师-学生蒸馏范式与并行多任务设计
1. 特征提取与融合:分层捕捉跨模态信息
首先通过浅层特征提取模块(SFE)将红外、可见光图像转换到统一特征空间,再通过动态提取模块(DEM)获取多尺度深层语义特征(图2a、e);接着针对浅层特征用自适应融合策略(AFM)、深层特征用通道注意力融合(CAM),最后通过PHF模块完成异构特征的渐进式融合(图2b、c、d)。
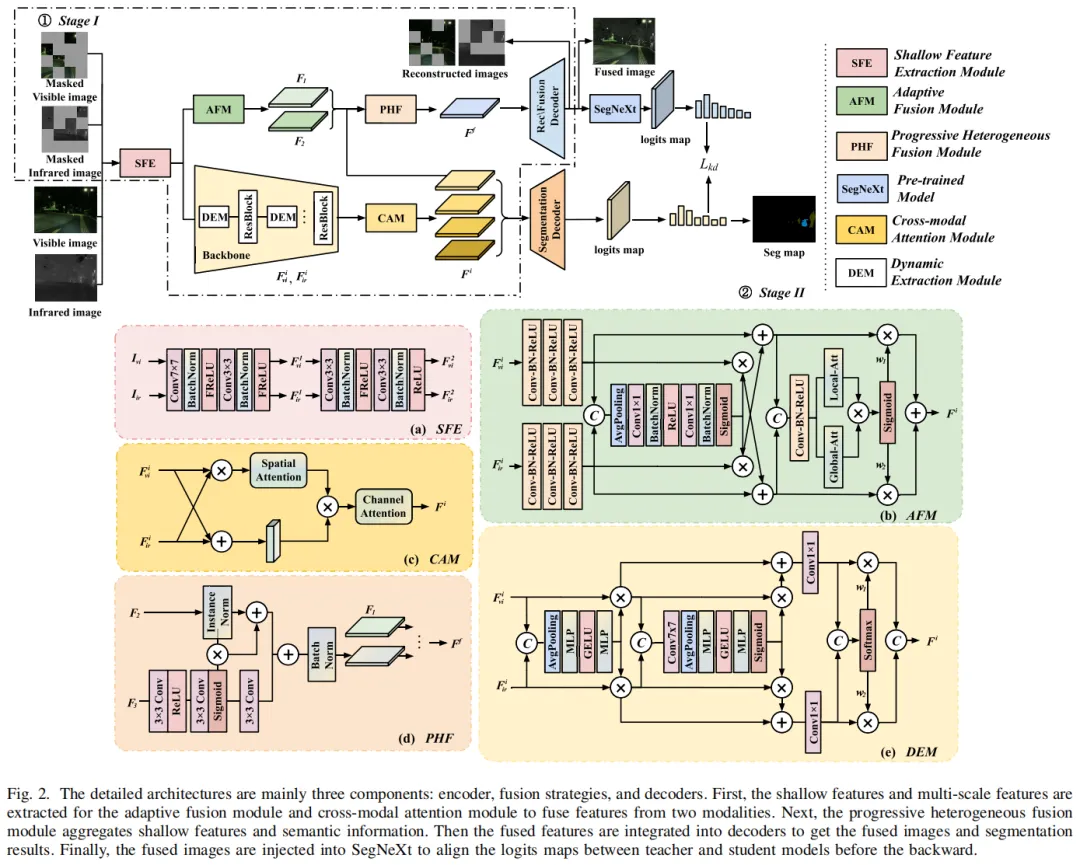 图2:MAFS特征提取与融合核心模块,包含SFE、AFM、CAM、PHF、DEM五大关键组件
图2:MAFS特征提取与融合核心模块,包含SFE、AFM、CAM、PHF、DEM五大关键组件
2. 融合解码器:减少细节损失
为避免融合过程中高频细节丢失,MAFS采用密集连接的可逆神经网络作为融合解码器(图3),通过残差通道注意力操作重建图像,既能保留红外图像的热目标信息,又能还原可见光图像的纹理细节。
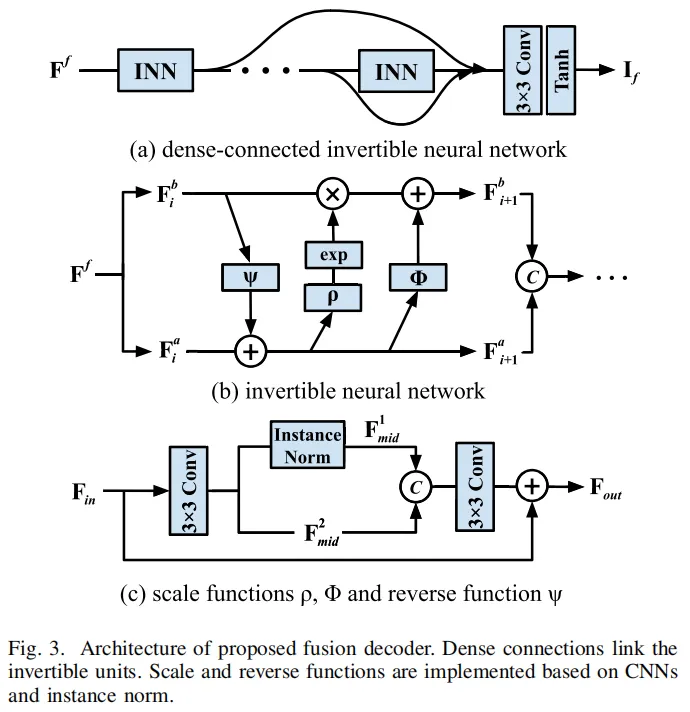 图3:可逆神经网络解码器,有效减少融合图像的细节信息损失
图3:可逆神经网络解码器,有效减少融合图像的细节信息损失
3. 分割解码器:Transformer建模全局上下文
分割任务的核心是捕捉全局上下文,MAFS设计了多阶段Transformer解码器(图4):先通过FPN精炼深层语义特征,再用ASPP扩大感受野,最后通过倒金字塔Transformer聚合多尺度特征,输出高精度的分割预测图。
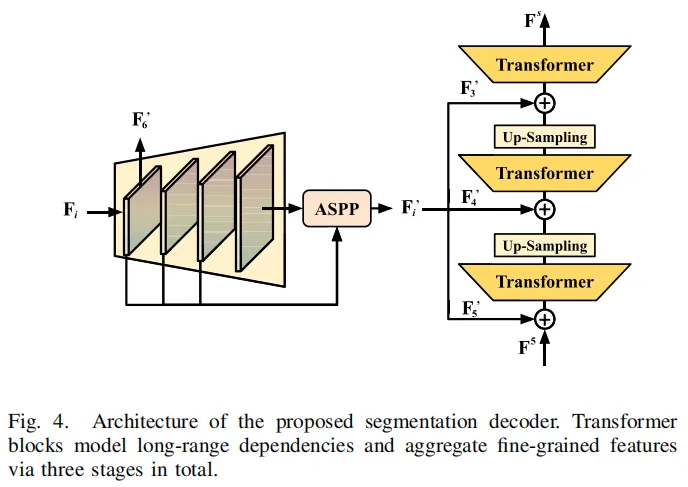 图4:基于Transformer的分割解码器,高效建模长距离空间关系
图4:基于Transformer的分割解码器,高效建模长距离空间关系
unsetunset四、实验结果:融合与分割双维度领先unsetunset
MAFS在MFNet、PST900、FMB、M3FD四大权威数据集上完成了全面验证,无论是融合图像的视觉/定量指标,还是分割任务的mIoU,均超越现有SOTA方法。
1. 融合效果:细节与语义兼得
主观对比中(图6、7、8),MAFS生成的融合图像在低光、强光等极端场景下,既能突出行人、车辆等关键目标,又能保留建筑物纹理、交通灯细节等精细信息,对比度和色彩饱和度均优于其他方法。
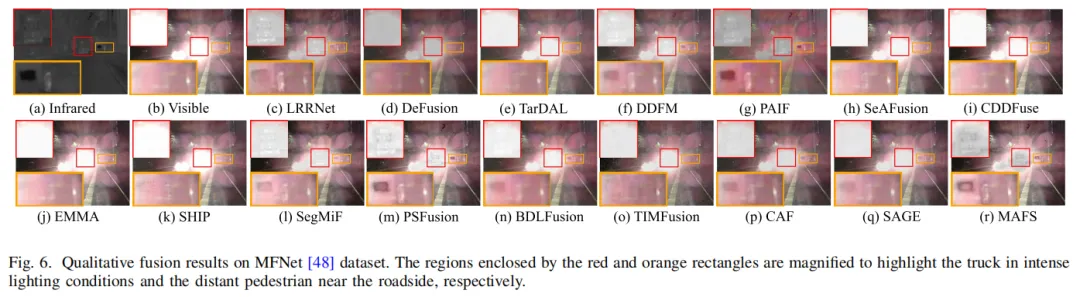 图6:低光场景下MAFS与其他SOTA方法的融合效果对比,MAFS清晰突出行人与车辆纹理
图6:低光场景下MAFS与其他SOTA方法的融合效果对比,MAFS清晰突出行人与车辆纹理
 图7:建筑物纹理细节对比,MAFS保留更丰富的结构信息
图7:建筑物纹理细节对比,MAFS保留更丰富的结构信息
定量指标上,MAFS在MFNet数据集的6项评估指标中拿下5项第一,在FMB、M3FD数据集的空间频率(SF)、视觉信息保真度(VIF)等核心指标上均排名第一,证明了融合图像的高质量。
2. 分割效果:语义感知提升场景解析精度
在语义分割任务中,MAFS凭借融合图像的语义感知优势,在MFNet数据集上mIoU超越PSFusion 0.06%,在FMB数据集上mIoU比SegMiF高出1.6%,尤其在“人”“车”“路灯”等关键类别上分割精度显著提升(图9、11)。
 图9:夜间场景分割效果,MAFS对远处行人和车辆的分割更精准
图9:夜间场景分割效果,MAFS对远处行人和车辆的分割更精准
 图11:FMB数据集白天场景分割,MAFS对植被、建筑物边界分割更精细
图11:FMB数据集白天场景分割,MAFS对植被、建筑物边界分割更精细
unsetunset五、总结:多任务协同的新范式unsetunset
MAFS的核心价值在于跳出了“融合只为视觉效果”“分割仅依赖单一模态”的传统思维,从宏观任务层面打通了融合与分割的知识壁垒:通过知识蒸馏实现任务间的相互促进,用掩码自编码器夯实特征基础,以异构特征融合和动态权重平衡训练过程,最终实现了两大任务的性能双提升。
这一研究不仅为红外-可见光图像融合与语义分割提供了新的解决方案,也为多模态、多任务计算机视觉研究提供了可借鉴的思路——让不同任务从“各自为战”走向“协同共赢”,才是复杂场景感知的未来方向。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
