三维视觉技术的上半场,往往是在“温室”中度过的:依赖精准的真值位姿(Ground Truth Poses)、理想的静态场景以及高质量的RGB图像。然而,NeRF 要赋能具身智能(Embodied AI)真正落地,必须直面真实世界的“狂野”挑战:自动驾驶中不仅面临动态车流更缺失真值位姿、事件相机在极速运动下伴随着强噪声干扰、深空探测中需应对姿态未知的非合作目标,以及复杂轨迹下相机的剧烈运动。
本文精选了在ICRA 2025、IJCNN 2025、CVPR 2025 Workshop及 IROS 2025上发表的四篇前沿论文(FreeDriveRF, SaENERF, Space Object Reconstruction, RA-NeRF),集中展示了神经辐射场技术在“无位姿态动态解耦”、“事件视觉去噪”、“非合作目标姿态反演”以及“复杂轨迹鲁棒估计”四个关键维度的突破。这些技术正在联手打破理想与现实的壁垒,为具身智能打造一套在“野外”也能生存的视觉感知系统。

FreeDriveRF:单眼RGB 动态NeRF,无姿态,通过点级动态-静态解耦实现自动驾驶(ICRA 2025)
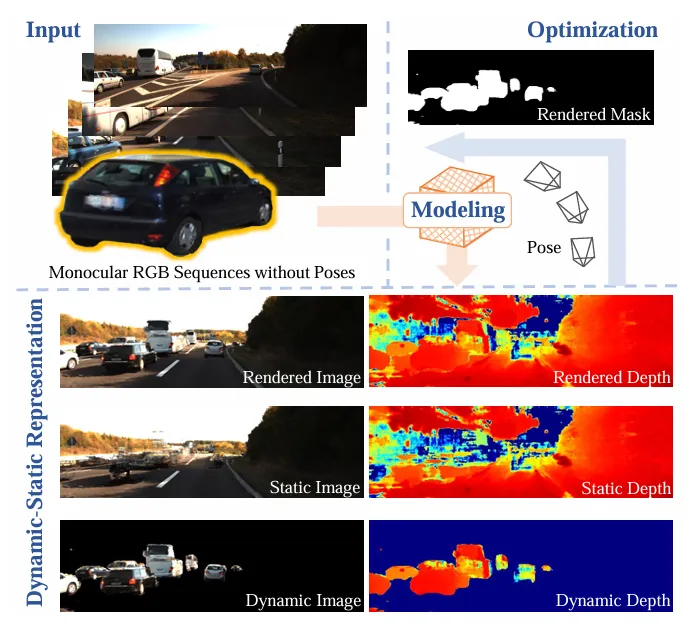 图1:FreeDriveRF 效果概览。仅凭单目RGB序列,在无位姿输入下实现自动驾驶场景重建。上图展示了从输入序列到动静解耦、掩膜生成及最终渲染的全流程。
图1:FreeDriveRF 效果概览。仅凭单目RGB序列,在无位姿输入下实现自动驾驶场景重建。上图展示了从输入序列到动静解耦、掩膜生成及最终渲染的全流程。亮点速览
彻底告别位姿依赖:针对自动驾驶场景,打破了对多传感器(如LiDAR)或预计算位姿的依赖。仅凭单目RGB图像序列,即可在无位姿输入的情况下实现高质量的动态场景重建。
动静完美分离:解决了动态物体(如行驶车辆)在重建中产生的“鬼影”和伪影问题,能够清晰地还原被动态物体遮挡的静态背景。
创新点
采样级语义解耦(Sampling-Level Decoupling):不同于传统方法在渲染后期进行混合,该方法在射线采样的早期阶段引入语义监督分离场。它为每个采样点分配“动态”或“静态”概率,直接将它们送入独立的模型进行处理,从源头上杜绝了动静特征的混淆。
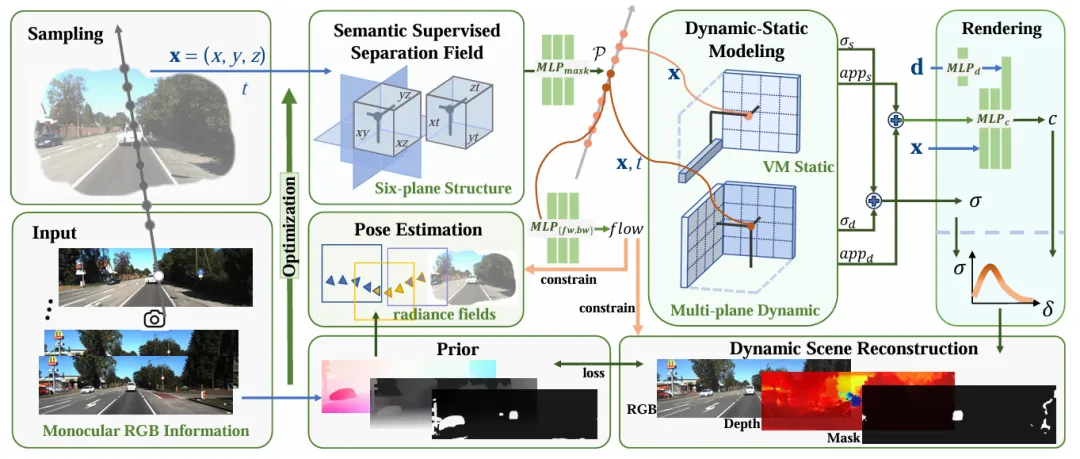 图2:FreeDriveRF 算法管线。 核心在于左上角的“语义监督分离场”,它在采样阶段直接将点云解耦。同时,利用右侧的动态流场(Flow Field)约束位姿优化,解决遮挡问题。
图2:FreeDriveRF 算法管线。 核心在于左上角的“语义监督分离场”,它在采样阶段直接将点云解耦。同时,利用右侧的动态流场(Flow Field)约束位姿优化,解决遮挡问题。扭曲射线引导的一致性(Warped Ray-Guided Consistency):针对单目相机的遮挡难题,利用光流信息对射线进行“扭曲”。这就像给射线装上了追踪器,确保它能始终锁定移动物体上的同一物理点,强制保证了时间维度上的渲染一致性。
流约束位姿优化(流量约束优化):不只是简单地把动态物体“抠掉”,而是利用估计出的动态流来反向约束相机的位姿优化过程。这有效防止了物体自身的运动干扰算法对相机运动的判断。
成果
背景修复能力:在 KITTI 和 Waymo 数据集上,不仅准确重建了动态车辆,还成功修复了大量被车辆遮挡的静态背景区域。
鲁棒性提升:在无真值位姿的挑战下,其重建质量和位姿估计精度显著优于 EmerNeRF 和 RoDynRF 等基线方法。
SaENERF: Suppressing Artifacts in Event-based Neural Radiance Fields (Accepted by IJCNN 2025)
亮点速览
事件视觉净化器:专为高动态范围、低延迟的事件相机设计。针对现有 Event-NeRF 方法生成的场景“雾蒙蒙”、伪影重重的痛点,提出了一套自监督的伪影抑制框架。
噪点“消音”技术:巧妙利用事件流中的“静默”信息,在无需额外真值数据的情况下,显著提升了重建场景的纯净度和边缘锐度。
创新点
渐进式归一化学习 (Progressive Learning with Normalization):为了防止模型在训练初期“操之过急”地拟合复杂光照而产生伪影,引入了基于 L1 范数的归一化策略。这迫使模型先“打地基”(学习几何结构),再“装修”(学习光照变化),从而规避了早期伪影的生成。
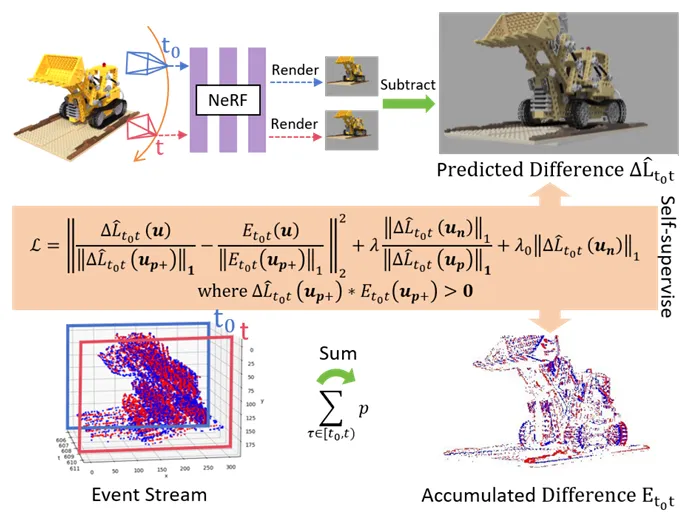 图3:SaENERF 渐进式学习框架。 针对事件相机的噪声,系统通过归一化辐射度变化来加速几何收敛,并利用“零事件正则化损失”抑制非活跃区域的伪影。
图3:SaENERF 渐进式学习框架。 针对事件相机的噪声,系统通过归一化辐射度变化来加速几何收敛,并利用“零事件正则化损失”抑制非活跃区域的伪影。零事件正则化 (Zero-Events Regularization):这是一个极其敏锐的观察。作者认为“没有事件发生的地方就不应有光度变化”。基于此设计了正则化损失,专门压制零事件区域的波动,同时增强非零区域的对比度,有效去除了背景噪声。
隐式位姿滤波器 (Implicit Pose Filter):针对事件数据自带的噪声,设计了一个隐式滤波器来建模相机的运动模式,平滑了梯度噪声,进一步提升了重建的稳定性。
成果
画质飞跃:在合成与真实数据集的对比中,SaENERF 重建的背景几乎没有噪点,物体的几何边缘也更加清晰,视觉保真度远超 EventNeRF 和 E-NeRF。
极低 LPIPS:在 Ficus 场景中,其 LPIPS(感知相似度指标)低至 0.05,而对比方法高达 0.16,证明了其卓越的去伪影能力。
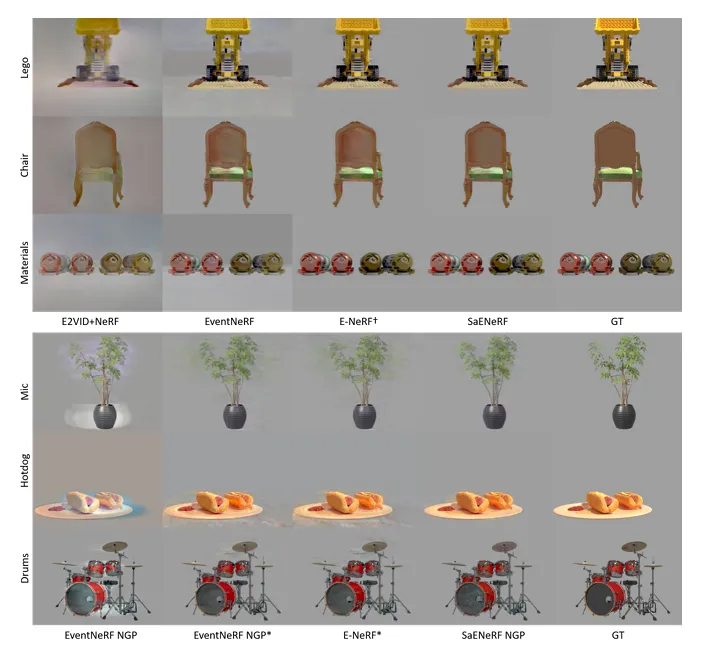 图4:合成场景下的伪影抑制效果。 对比 EventNeRF 和 E-NeRF(中间列),SaENERF(右二列)生成的图像背景极其干净(如Lego场景),彻底消除了雾状噪声,边缘细节更锐利。
图4:合成场景下的伪影抑制效果。 对比 EventNeRF 和 E-NeRF(中间列),SaENERF(右二列)生成的图像背景极其干净(如Lego场景),彻底消除了雾状噪声,边缘细节更锐利。Joint Attitude Estimation and 3D Neural Reconstruction of Non-Cooperative Space Objects (Accepted for CVPR 2025 NFBCC Workshop)
亮点速览
深空非合作目标扫描:面向在轨服务与太空碎片清理,解决了对“非合作”(无通信、无姿态信息)卫星进行3D重建的难题。
极端光照适应:在只有单一太阳光源、背景全黑且物体可能具备高反光或透明材质的极端环境下,依然实现了精准的姿态反演与几何重建。
创新点
增量式均匀姿态估计 (Incremental Uniform Attitude Estimation):放弃了“一步到位”的幻想,采用增量策略。假设目标做均匀旋转运动,联合优化 NeRF 模型与旋转参数。通过逐步加入图像,让模型在“运动中”学会姿态。
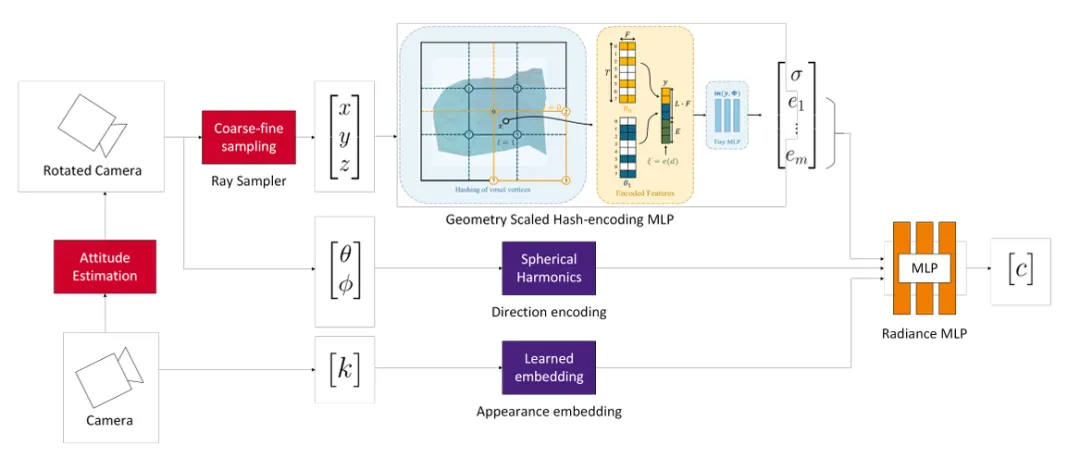 图5:太空目标联合重建架构。 针对无姿态的非合作目标,模型引入了姿态估计模块(左侧红色模块),并结合梯度缩放的哈希编码,在单一太阳光源下同步优化卫星的几何结构与运动参数
图5:太空目标联合重建架构。 针对无姿态的非合作目标,模型引入了姿态估计模块(左侧红色模块),并结合梯度缩放的哈希编码,在单一太阳光源下同步优化卫星的几何结构与运动参数梯度缩放哈希编码 (Gradient-Scaled Hash Encoding):为了防止优化过程陷入局部极小值(Local Minima),设计了一种训练调度策略。在初期屏蔽高频特征的梯度,让姿态估计器先在低频空间“找准方向”,再逐步丰富细节。
透明度与辐射正则化:针对太空物体的特殊材质,引入了不透明度(Opacity)和辐射度(Radiance)正则化,防止模型偷懒生成“半透明幽灵”状的错误解。
成果
毫米级精度:在模拟的伽利略卫星数据集上,实现了平均 17.2mm 的几何重建精度。
 图6:高精度重建结果验证。 模型不仅恢复了RGB辐射度图(Radiance),还精准输出了深度图(Depth)和表面法向量(Normals),验证了在极端光照条件下几何重建的鲁棒性。
图6:高精度重建结果验证。 模型不仅恢复了RGB辐射度图(Radiance),还精准输出了深度图(Depth)和表面法向量(Normals),验证了在极端光照条件下几何重建的鲁棒性。高鲁棒姿态反演:在完全未知的初始姿态下,最终的姿态估计误差控制在 3 度以内,而传统的 SfM 方法在该场景下完全失效。
RA-NeRF: Robust Neural Radiance Field Reconstruction with Accurate Camera Pose Estimation under Complex Trajectories (IROS 2025)
亮点速览
复杂轨迹终结者:打破了 NeRF 联合位姿估计仅适用于前向场景(Forward-facing)的局限。针对大角度旋转、复杂轨迹运动的场景,实现了从零开始的精准位姿估计。
摆脱局部最优:通过引入几何约束和滤波机制,解决了 BARF 等方法在大幅度运动下容易陷入局部极小值的问题。
创新点
流驱动位姿调节 (Flow-Driven Pose Regulation):不只依赖光度误差,而是利用光流计算图像对之间的相对位姿,并以此作为“路标”直接约束全局位姿优化。这为模型提供了一个强有力的几何先验,防止其“跑偏”。
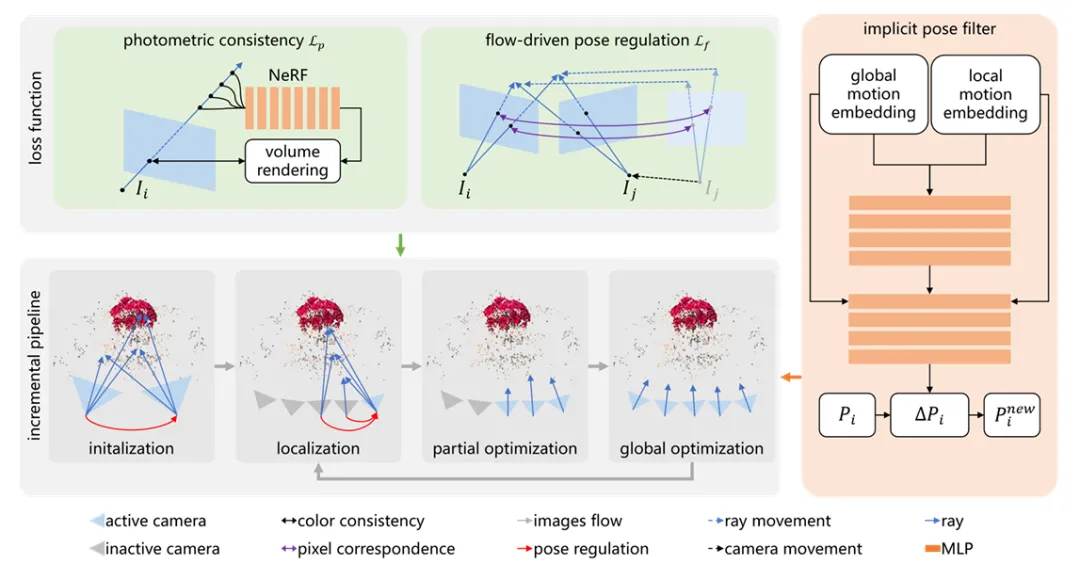 图7:RA-NeRF 增量式重建流程。 为了解决复杂轨迹下的局部极小值问题,系统引入了流驱动的位姿调节(上方中间)以及隐式位姿滤波器(右侧),通过平滑梯度噪声来实现精准定位。
图7:RA-NeRF 增量式重建流程。 为了解决复杂轨迹下的局部极小值问题,系统引入了流驱动的位姿调节(上方中间)以及隐式位姿滤波器(右侧),通过平滑梯度噪声来实现精准定位。隐式位姿滤波器 (Implicit Pose Filter):作者没有直接优化位姿参数,而是训练了一个 MLP 网络作为滤波器。它接收全局和局部的运动嵌入(Embedding),输出平滑的位姿更新量,有效过滤了优化过程中的梯度噪声。
增量式重建管线 (Incremental Pipeline):采用“初始化 -> 定位 -> 局部/全局优化”的严谨流程,步步为营,确保每一步的位姿估计都足够稳健。
成果
SOTA 精度:在极具挑战性的 NeRFBuster 数据集(包含复杂旋转运动)上,RA-NeRF 将旋转误差降低至约 1.1 度,而同类方法(如 NeRFmm, BARF)的误差往往超过 50 度,展现了压倒性的优势。
 图8:NeRFBuster 数据集上的轨迹估计对比。 在包含大幅度旋转的复杂场景中,RA-NeRF(图d)估计的相机轨迹(蓝色锥体)与真值最为贴合,而 Nope-NeRF 等基线方法(图a-c)出现了严重的轨迹漂移(红色连线表示误差)。
图8:NeRFBuster 数据集上的轨迹估计对比。 在包含大幅度旋转的复杂场景中,RA-NeRF(图d)估计的相机轨迹(蓝色锥体)与真值最为贴合,而 Nope-NeRF 等基线方法(图a-c)出现了严重的轨迹漂移(红色连线表示误差)。跨越理想与现实的鸿沟:构建全天候的 3D 感知能力
如果说早期的 NeRF 研究是在探索“能重建什么”,那么这四篇工作则是在回答“能在哪里重建”。当自动驾驶不再惧怕动态车流(FreeDriveRF),当事件相机不再受困于噪点(SaENERF),当深空探测器能看懂未知的卫星(Space Object Reconstruction),当算法能搞定任意复杂的轨迹(RA-NeRF),我们看到的是 3D 视觉技术正在跨越从“理想实验室”到“复杂现实”的巨大鸿沟。
这些技术共同构建了一种全天候、强鲁棒、自适应的 3D 感知基座。对于具身智能而言,这意味着它不再是一个只能在特定条件下工作的“娇气包”,而是一个能适应噪点、动态、未知姿态等各种极端挑战的“全能战士”。唯有具备这种“野外生存”能力,智能体才能真正走出实验室,在纷繁复杂的物理世界中自由探索。
如果大家有要宣传的工作(paper、项目、rp、招聘等),欢迎后台留言或者私信我~关注+星标不迷路~
入场券:CCF/SCI/kaggle比赛指路




