自动驾驶车辆对交警手势的识别,首要环节是实现对交通环境的精细化感知。在早期计算机视觉技术方案中,自动驾驶系统主要依靠刚性边界框技术进行目标定位,这种方式虽能将交警从复杂背景中分离出来,完成“人体”这一基础目标的识别,但粗颗粒度的定位无法捕捉手势中蕴含的核心指挥信息,难以满足实际通行需求。
为破解这一痛点,人体姿态估计技术被广泛应用于自动驾驶感知系统。该技术不再将交警视为一个整体目标,而是通过提取人体关键节点——包括肩膀、肘部、手腕、髋部、脚踝等,构建出精细化的生物力学骨架模型,以此捕捉肢体动作的细微变化,进而解析手势语义。这一过程的实现,离不开车辆搭载的多类传感器协同工作、优势互补。
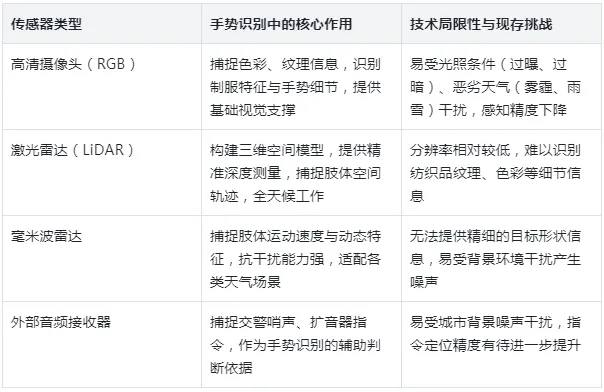
高清摄像头作为视觉感知的核心部件,负责捕捉场景中的色彩、纹理信息,可精准识别交警的制服特征、反光背心样式,以及手部摆动的细微动作,为手势识别提供基础视觉支撑。但摄像头的感知效果易受环境因素影响,在强光直射、夜间昏暗环境或雨雪雾霾天气下,容易出现感知精度下降、细节丢失等问题。
此时,激光雷达可发挥其全天候感知优势——通过向周围环境发射激光脉冲并接收反射点云,为系统构建具备精准深度信息的三维空间模型,即便在光线不足的场景中,也能清晰勾勒出交警手臂摆动的空间轨迹,弥补摄像头的感知短板。毫米波雷达则专注于捕捉肢体运动的动态特征,通过监测交警身体运动的多普勒频率变化,感知动作的爆发力与节奏,进一步提升动态手势的识别准确性。
这种多模态传感器数据融合的方式,让自动驾驶系统摆脱了单一传感器的局限性,构建出超越人类肉眼感知能力的全天候数字视界,为手势识别奠定了坚实基础。
除了姿态捕捉,自动驾驶系统还需完成交警身份的精准确认——交通环境中,路边招手的行人、施工的环卫工、普通路人的肢体动作,均不具备交通指挥意义,若误判将引发严重通行风险。因此,感知层会通过卷积神经网络(CNN)对目标进行精细分类,通过识别制服、指挥棒等特征,确认目标是否为正在执行指挥任务的交警。一旦完成身份确认,系统会将计算资源集中分配给该目标,重点追踪其姿态变化。
目前,MoveNet、MediaPipe等主流姿态估计算法,可在极低计算延迟的前提下,快速提取人体关键节点,这种高效性对于车辆在高速行驶中(时速几十公里)做出瞬时决策至关重要。同时,针对手部动作识别中的难点——如手套颜色干扰、手部被遮挡、交警侧身朝向车辆等,行业内已提出三维手部模型解决方案,通过对关键帧的深度学习,系统可推断出被遮挡部位的可能姿态,进一步提升识别鲁棒性。
以Waymo的感知系统为例,其可在繁忙路口同时追踪上百个行人的动态,并通过分层式识别架构,快速筛选出对车辆行驶有直接影响的交警指挥信号,从整体目标定位到局部手势捕捉,构建起自动驾驶系统理解人类指挥的第一道技术防线。