🚗 自动驾驶的“预判”能力,如何炼成?还在为MPC调参头疼?港大团队新作HPTune,教你如何让算法“未卜先知”,主动规避风险!想第一时间掌握自动驾驶、机器人领域的最新突破与调参秘籍?来「龙哥读论文」知识星球,每日前沿论文速递+深度解读,助你抢占技术先机!👇扫码加入「龙哥读论文」知识星球,前沿干货、实用资源一站式拿捏~
龙哥导读:
想象一下,你的自动驾驶汽车不仅能看到眼前的障碍物,还能“感知”到几秒后可能发生的危险,并提前调整策略。这听起来像科幻,但香港大学的研究团队正将其变为现实。他们提出的HPTune框架,让模型预测控制(MPC)从“事后诸葛亮”变成了“事前诸葛亮”,通过主动评估未来动作,实现了更安全、更敏捷的避障。今天,我们就来拆解这项让自动驾驶“未卜先知”的技术。
原论文信息如下:
论文标题:
HPTUNE: HIERARCHICAL PROACTIVE TUNING FOR COLLISION-FREE MODEL PREDICTIVE CONTROL
发表日期:
2026年01月
发表单位:
The University of Hong Kong, Shenzhen Institutes of Advanced Technology (Chinese Academy of Sciences), University of New South Wales
原文链接:
https://arxiv.org/pdf/2601.21346v1.pdf
从被动到主动:MPC调优的范式转变
开车时,最怕什么?当然是突然窜出来的行人或车辆。自动驾驶系统的运动规划算法,比如 模型预测控制(Model Predictive Control, MPC),每天都在处理这类避障问题。MPC就像一个“步步为营”的棋手,每走一步,都提前规划好未来十几步的动作,确保安全抵达目标。但MPC有个“老大难”问题:调参。它的成本函数里有一堆权重参数(比如跟踪目标有多重要,省油/省电有多重要,离障碍物多远算安全),这些参数调得好不好,直接决定了车子是开得稳如老狗,还是像新手一样哆哆嗦嗦甚至撞车。开环调参:像个“纸上谈兵”的将军,在规划出动作序列后就立刻根据这个“计划”的好坏来调整参数。它的问题在于,没考虑计划执行时环境(比如其他车突然变道)带来的实际影响。闭环调参:像个“事后复盘”的军师,等车真正执行了一步动作,产生了后果(比如离障碍物太近了),再根据这个“结果”的损失来调整参数。这听起来更靠谱,但它有个致命缺点:反应太慢,效率太低。为啥效率低?因为碰撞或极度接近这种“失败事件”在正常驾驶中是稀疏的,不常发生。算法大部分时间开得好好的,没有失败信号,参数也就得不到有效的更新。这就好比一个学生,只有等到考试不及格了才去改学习方法,平时作业全对就躺平,这进步能快吗?港大团队的这篇论文,正是要解决这个痛点。他们提出,我们不能只盯着“已经执行”的动作来打分,更要给“即将执行但还未执行”的未来动作也提前打个分。这就是论文的核心思想:从“反应式”的闭环调参,转向“主动式”的闭环调参。简单说,就是让MPC拥有“预判”能力。在危险真正发生之前,就通过预测感知到风险,并提前调整安全参数,做到防患于未然。这个框架,就被命名为HPTune(Hierarchical Proactive Tuning),即分层主动调优。核心揭秘:HPTune的双层调优架构
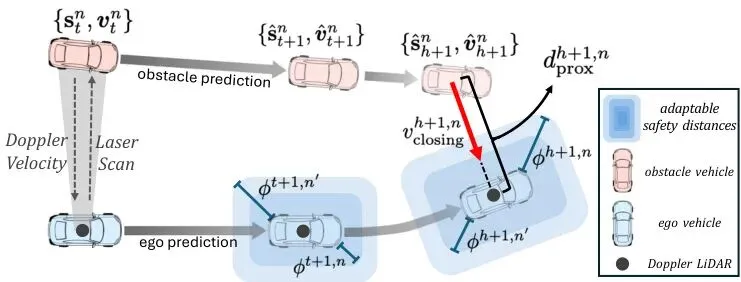
为了实现“主动预判”,HPTune设计了一个精巧的双层架构:一个高频更新的“快层”和一个低频更新的“慢层”。两者协同工作,就像汽车的“ESP车身稳定系统”(快速微调)和“驾驶员长期驾驶风格学习”(缓慢适应)的结合。快层调优的核心任务是:根据对未来的预测,动态调整MPC规划中要求与障碍物保持的安全距离。MPC每次规划,都会产生一个未来动作序列,但只执行第一步。HPTune巧妙地利用了那些“非执行”的、代表未来期望状态的动作序列,将其作为自车在未来一段时间内的预测轨迹。同时,结合对障碍物运动状态的预测,HPTune计算了两个关键的风险指标:预测接近距离:自车预测轨迹与障碍物预测轨迹在未来每个时刻的最近距离。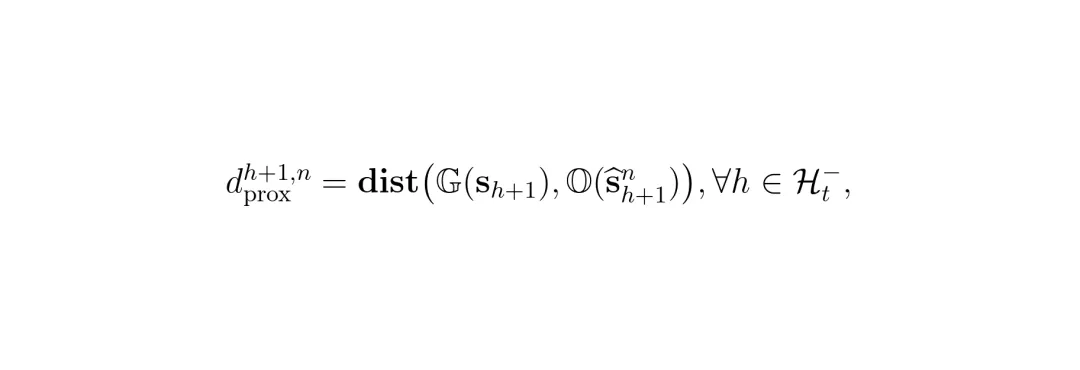 公式说明:dproxh+1, n 表示在未来的 h+1 时刻,自车与第 n 个障碍物之间的预测最小距离。预测接近速度:自车与障碍物在未来时刻的相对速度,在两者连线方向上的投影。这个值如果是正的,表示两者正在相互靠近,值越大,接近得越快,风险越高。
公式说明:dproxh+1, n 表示在未来的 h+1 时刻,自车与第 n 个障碍物之间的预测最小距离。预测接近速度:自车与障碍物在未来时刻的相对速度,在两者连线方向上的投影。这个值如果是正的,表示两者正在相互靠近,值越大,接近得越快,风险越高。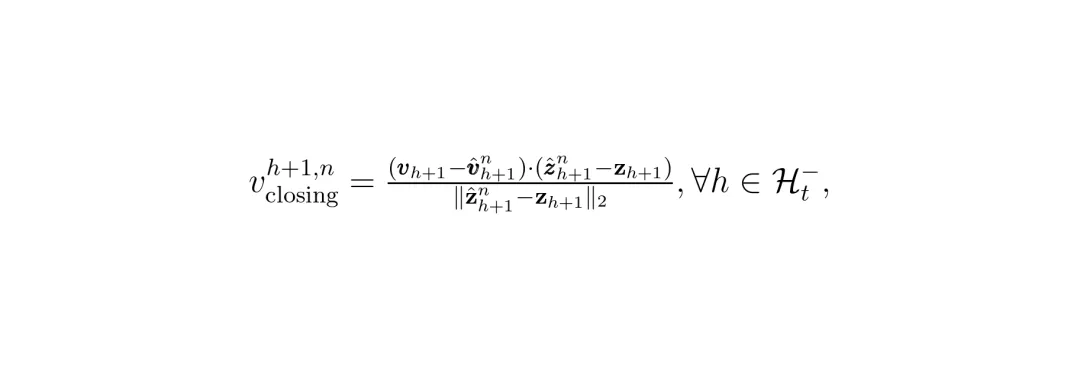 公式说明:vclosingh+1, n 计算的是相对速度矢量在“障碍物指向自车”这个方向上的分量,直观反映了“撞过来的速度有多快”。有了这两个指标,HPTune就能计算出一个动态的、“因时制宜”和“因车制宜”的安全距离。它的计算逻辑非常符合直觉:
公式说明:vclosingh+1, n 计算的是相对速度矢量在“障碍物指向自车”这个方向上的分量,直观反映了“撞过来的速度有多快”。有了这两个指标,HPTune就能计算出一个动态的、“因时制宜”和“因车制宜”的安全距离。它的计算逻辑非常符合直觉: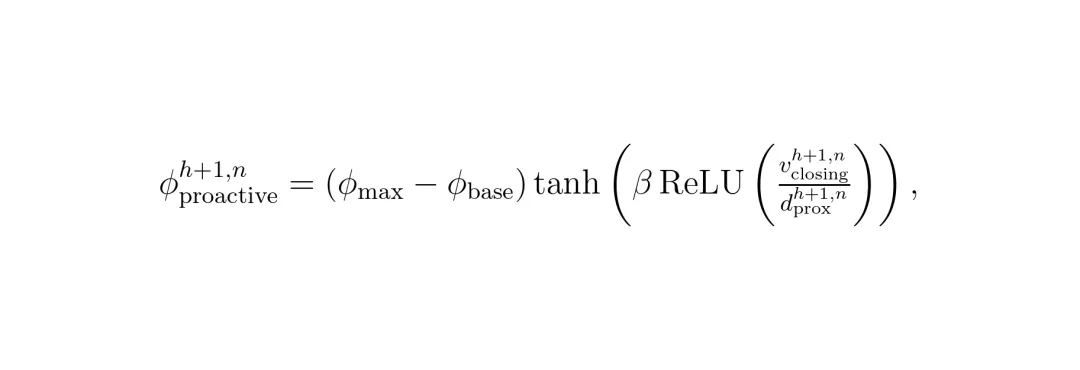 公式说明:ϕproactiveh+1, n 就是动态调整的部分。它正比于 (接近速度 / 接近距离) 这个比值。这个比值量化了危险的迫近程度:速度越快、距离越近,危险越大,所需的安全余量就越大。ReLU函数确保只有正在接近的障碍物才被考虑,tanh函数保证调整是平滑的,β是一个可调参数,控制对风险的敏感度。图1:基于风险指标的扩展评估。图中对比了传统闭环调参(只评估已执行动作,更新稀疏)和HPTune的主动评估(评估未来非执行动作,更新密集且提前)。图中 MPC Horizon 表示MPC规划的步长,Executed Actions 是已执行动作,Non-executed Actions 是非执行(未来)动作,Risk Indicators 即风险指标。最终,MPC的避障约束就从固定的“距离必须大于 ϕsafe”,变成了动态的“距离必须大于 ϕbase + ϕproactiveh+1, n”。这样一来,当系统预测到几秒后可能有一辆车快速切入时,它现在就会要求规划出一条更宽松、更早开始避让的轨迹,而不是等对方真的切进来了才手忙脚乱。快层主要调安全距离相关的参数。慢层则负责调优MPC中更根本的两个参数:α:平衡“跟踪参考路径”和“控制动作平顺性”的权重。慢层每过T个时间步(比如5步)才更新一次。它构建了一个扩展的闭环评估损失函数L(t),这个函数是三个损失项的加权和:L₁(t) 导航损失:评估过去T步已执行动作的跟踪精度和控制消耗。这是传统闭环损失。L₂(t) 预测安全损失:这是实现“主动”的关键!它惩罚那些预测接近距离小于动态安全距离的情况。也就是说,即使实际碰撞没发生,只要预测到有风险,就会产生损失,从而驱动参数β调整,让安全边界ϕproactive变得更大、更积极。L₃(t) 安全距离正则化损失:惩罚过大的安全距离,防止系统因为过于保守而导致规划问题无解(比如在狭窄通道里要求过大的安全距离,车子就“不敢”开了)。
公式说明:ϕproactiveh+1, n 就是动态调整的部分。它正比于 (接近速度 / 接近距离) 这个比值。这个比值量化了危险的迫近程度:速度越快、距离越近,危险越大,所需的安全余量就越大。ReLU函数确保只有正在接近的障碍物才被考虑,tanh函数保证调整是平滑的,β是一个可调参数,控制对风险的敏感度。图1:基于风险指标的扩展评估。图中对比了传统闭环调参(只评估已执行动作,更新稀疏)和HPTune的主动评估(评估未来非执行动作,更新密集且提前)。图中 MPC Horizon 表示MPC规划的步长,Executed Actions 是已执行动作,Non-executed Actions 是非执行(未来)动作,Risk Indicators 即风险指标。最终,MPC的避障约束就从固定的“距离必须大于 ϕsafe”,变成了动态的“距离必须大于 ϕbase + ϕproactiveh+1, n”。这样一来,当系统预测到几秒后可能有一辆车快速切入时,它现在就会要求规划出一条更宽松、更早开始避让的轨迹,而不是等对方真的切进来了才手忙脚乱。快层主要调安全距离相关的参数。慢层则负责调优MPC中更根本的两个参数:α:平衡“跟踪参考路径”和“控制动作平顺性”的权重。慢层每过T个时间步(比如5步)才更新一次。它构建了一个扩展的闭环评估损失函数L(t),这个函数是三个损失项的加权和:L₁(t) 导航损失:评估过去T步已执行动作的跟踪精度和控制消耗。这是传统闭环损失。L₂(t) 预测安全损失:这是实现“主动”的关键!它惩罚那些预测接近距离小于动态安全距离的情况。也就是说,即使实际碰撞没发生,只要预测到有风险,就会产生损失,从而驱动参数β调整,让安全边界ϕproactive变得更大、更积极。L₃(t) 安全距离正则化损失:惩罚过大的安全距离,防止系统因为过于保守而导致规划问题无解(比如在狭窄通道里要求过大的安全距离,车子就“不敢”开了)。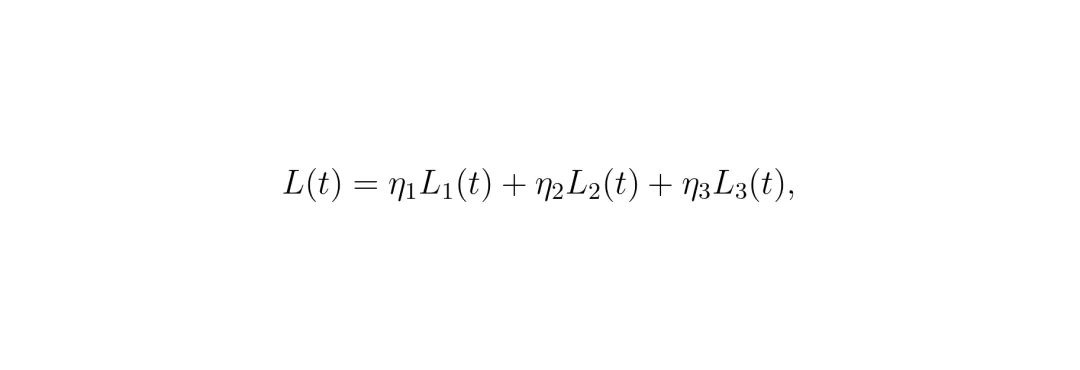 公式说明:总损失L(t)是三个损失的加权和,η是各自的权重。这个损失函数巧妙地在跟踪性能、主动安全性和规划可行性之间取得了平衡。
公式说明:总损失L(t)是三个损失的加权和,η是各自的权重。这个损失函数巧妙地在跟踪性能、主动安全性和规划可行性之间取得了平衡。计算出总损失后,HPTune使用标准的梯度下降法来更新参数α和β。整个HPTune的工作流程如下图所示(对应原文算法1):
1. 初始化状态、动作序列和可调参数Γ。
2. 在每个时间步t:
a. 使用传感器(下文详述)估计所有障碍物的速度,并预测其未来状态。
b. 求解加入了动态安全距离约束的MPC问题,得到最优规划,并执行第一步动作。
c. 基于自车预测轨迹和障碍物预测,计算所有未来时刻的风险指标。
d. 根据风险指标更新动态安全距离ϕh+1, n。
e. 如果到达慢层更新周期(t是T的倍数),则计算扩展损失L(t),并通过梯度下降更新参数α和β。
3. 重复步骤2。
关键赋能:多普勒激光雷达与预测指标
“预判”的前提是精准的预测。如果连障碍物下一步要去哪都不知道,那所谓的风险指标就是空中楼阁。HPTune性能强大的一个关键赋能,在于它集成了多普勒激光雷达。我们常见的3D激光雷达(LiDAR, Light Detection and Ranging)像个“超级秒表”,通过测量激光往返时间来确定物体的位置(距离和角度)。而多普勒激光雷达更牛,它还能利用多普勒效应,测量激光打在物体上后频率的变化,从而直接获取物体在激光方向上的径向速度。所以它被称为“4D激光雷达”(3D位置+1D速度)。论文中,安装在自车上的多普勒激光雷达扫描环境,对于探测到的第n个障碍物,通过对其点云中所有点的多普勒速度测量值进行聚合和方向投影,可以估计出该障碍物的线速度: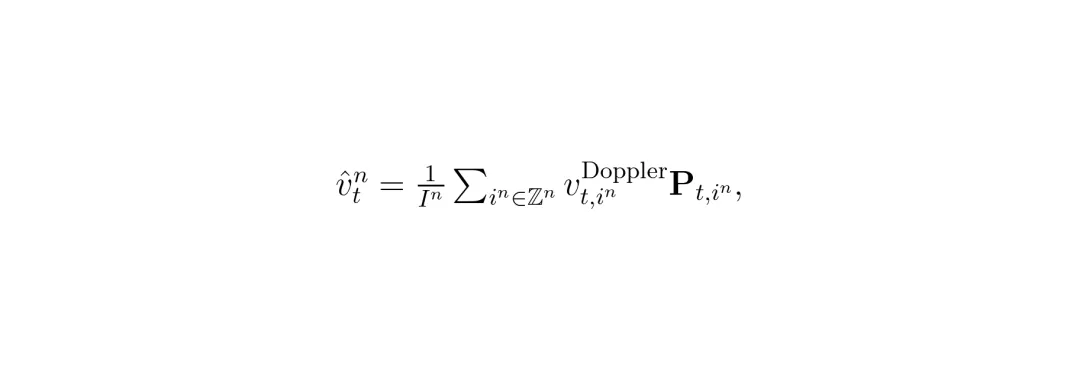 公式说明:利用多普勒LiDAR直接测量的速度分量,反推障碍物的整体运动速度。得到了障碍物准确的速度信息后,再结合卡尔曼滤波器这类状态估计算法,就可以非常可靠地预测出它未来一段时间(MPC的规划时域内)的状态序列 {ŝh+1n, v̂h+1n}。这正是计算“预测接近速度” vclosing 所必需的信息。可以说,多普勒激光雷达提供的即时速度感知,是HPTune“预判”能力的物理基础。没有这个,对未来风险的量化将大打折扣。
公式说明:利用多普勒LiDAR直接测量的速度分量,反推障碍物的整体运动速度。得到了障碍物准确的速度信息后,再结合卡尔曼滤波器这类状态估计算法,就可以非常可靠地预测出它未来一段时间(MPC的规划时域内)的状态序列 {ŝh+1n, v̂h+1n}。这正是计算“预测接近速度” vclosing 所必需的信息。可以说,多普勒激光雷达提供的即时速度感知,是HPTune“预判”能力的物理基础。没有这个,对未来风险的量化将大打折扣。实验验证:性能全面领先,效率显著提升
理论再好,也得看疗效。作者在业内知名的高仿真自动驾驶模拟器CARLA中搭建了实验场景:一个40m×40m的场地,自车需要沿参考路径穿越,而场地中有多个随机位置生成、并以5m/s速度随机运动的障碍车辆。实验对比了以下方法:
HPTune:本论文提出的方法。
DiffTune-MPC [11]:一种基于微分和闭环损失的MPC调参方法(传统闭环代表)。
RDA [6]:一种开环MPC调参方法。
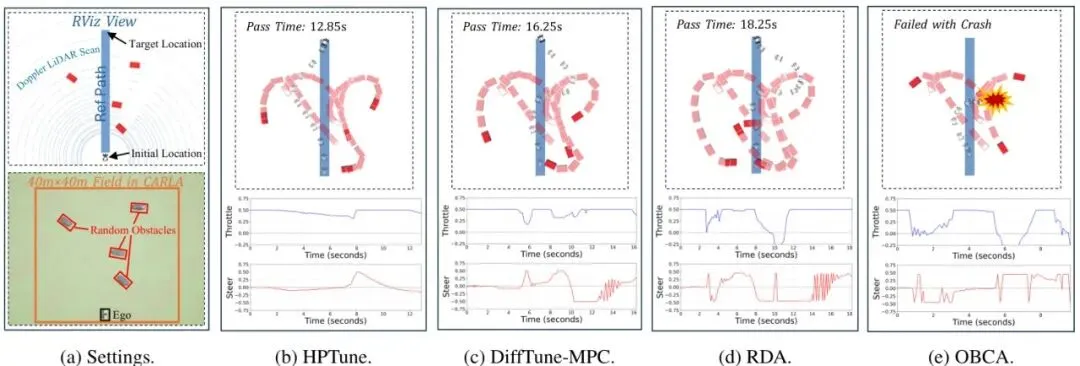
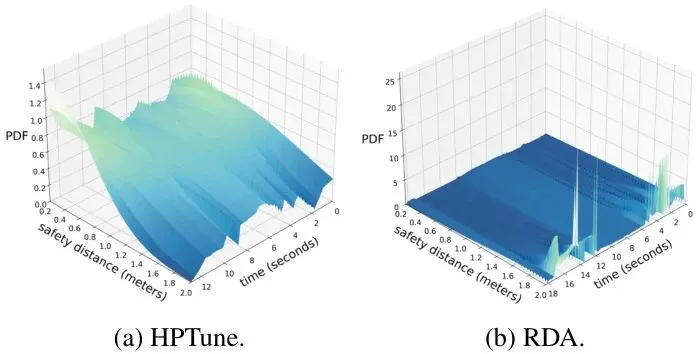
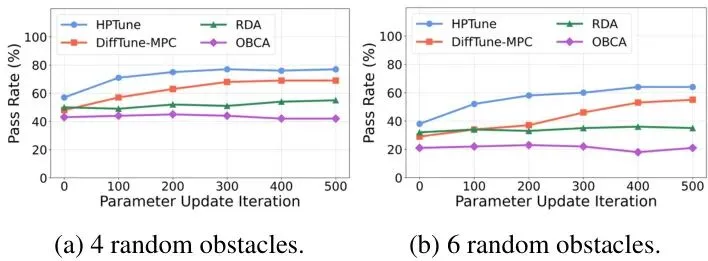
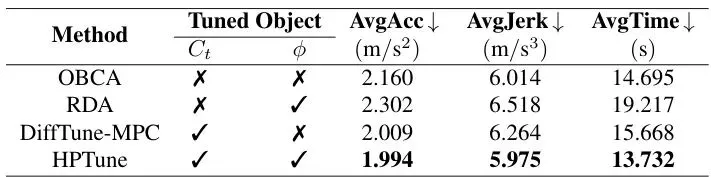
OBCA [13]:一种不调参的、基于优化的碰撞避免MPC方法(固定参数基线)。图2:场景设置与4个随机障碍物下的导航结果。(a)展示了CARLA中的实验场景及RViz中的多普勒激光雷达扫描视图。(b)-(e)分别展示了HPTune, DiffTune-MPC, RDA和OBCA方法在导航过程中的自车行为。每张子图的上半部分是车辆轨迹(绿色为实际轨迹,红色虚线为参考路径,蓝色方块为障碍物),下半部分是控制动作(油门和转向)随时间的变化。从图2可以直观看出:HPTune的轨迹更平滑,控制动作(油门和转向)的波动也明显更小,这表明其驾驶风格更平稳、舒适。而其他方法,尤其是RDA,动作曲线有剧烈的抖动。为什么HPTune能更平滑?秘密在于它对安全距离的动态、持续且前瞻性的调整。图3:安全距离的运行时概率密度函数。图中颜色越亮表示概率密度越高。横轴是时间,纵轴是安全距离值。图3的对比非常精彩。左图(a) HPTune的安全距离在整个行驶过程中都在根据预测持续、平滑地调整,呈现出连续的亮带。右图(b) RDA(开环调参)则只在障碍物真正靠近的少数几个时刻(如t=2-5秒和12-17秒)才“反应式”地调高安全距离,其他时间基本不变。这种“平时躺平,危急时蹦高”的策略,自然会导致控制动作的突变和不平滑。接下来是最硬核的量化指标对比:导航通过率。作者在不同障碍物密度(4个和6个)下,进行了大量随机试验,并统计了参数更新迭代过程中通过率的变化。图4:不同障碍物密度下,通过率随参数更新迭代次数的对比。图4的结果令人信服:HPTune在所有设定下都保持着最高的通过率,相较于其他方法,提升幅度在7%到46%之间。特别值得注意的是,与同为闭环调参的DiffTune-MPC相比,在4个和6个障碍物场景下,通过率分别提升了13.7%和8.3%。这直接证明了将评估扩展到“非执行动作”的巨大价值。此外,HPTune的通过率在大约200次迭代后就趋于收敛,展现了其高效的调参能力。表1:调优特性与导航性能。展示了各方法是否调优成本函数(Ct)和安全距离(ϕ),以及平均加速度(AvgAcc)、平均加加速度/急动度(AvgJerk)、平均通过时间(AvgTime)等性能指标。箭头↑表示该指标越高越好,↓表示越低越好。从表1的综合性能来看,HPTune在运动平滑性(AvgJerk最低)和规划效率(AvgTime最短)上均表现最佳,实现了全面领先。AvgJerk低意味着乘坐更舒适,对车辆机械部件的损耗也更小。未来展望:从仿真走向现实的挑战与机遇
HPTune在CARLA仿真中交出了一份近乎完美的答卷,但其从仿真走向真实世界,仍面临几重挑战:传感器可靠性:本文性能严重依赖于多普勒激光雷达提供的精准速度信息。现实中,传感器噪声、遮挡、极端天气(雨、雾、雪)都会影响数据质量,进而影响预测精度和风险判断。如何提升感知系统的鲁棒性是将HPTune落地的前提。预测模型复杂性:实验中的障碍物做的是随机匀速运动,预测相对简单。真实交通中,行人、自行车、汽车的行为意图复杂多变。可能需要结合更高级的行为预测模型(甚至是基于学习的预测模型)来提升长期预测的准确性。计算实时性:HPTune在快层和慢层都引入了额外的计算(风险指标计算、梯度反向传播)。在资源受限的车载计算平台上,能否满足严格的实时性要求(通常要求规划在几十到一百毫秒内完成),需要进行深入的工程优化。尽管有挑战,但HPTune指明的方向——利用预测信息进行主动的、前瞻性的决策优化——无疑是运动规划和自动驾驶控制领域一个重要的发展趋势。它不仅适用于车辆避障,也可以扩展到无人机导航、机器人操作等更广泛的场景中。龙迷三问
这篇论文到底解决了自动驾驶中的什么问题?它解决了传统模型预测控制(MPC)在运动规划中“自动调参效率低下”的问题。传统闭环调参方法像“事后诸葛亮”,只在发生危险(如差点撞车)后才调整参数,导致学习慢、驾驶不流畅。HPTune让MPC变成了“事前诸葛亮”,通过对未来风险的预判来主动、持续地调整参数,从而实现更安全、更平滑、更高效的自动驾驶。
MPC和HPTune具体调的是什么“参数”?MPC中需要调优的参数主要是其优化问题中的一些权重和边界值。在本文中,主要调优两个核心参数:α(权衡“跟踪参考路径”和“控制动作平顺性”),以及β(控制系统对预测风险的敏感度)。此外,HPTune的快层还会动态调整一个更具体的参数:与每个障碍物在未来每个时刻对应的动态安全距离 ϕh+1, n。
如果不用多普勒激光雷达,能用普通摄像头或雷达实现HPTune吗?理论上可以,但效果会打折扣。HPTune的“预判”能力严重依赖于对障碍物速度的准确、即时估计。普通摄像头需要通过复杂的视觉算法(如光流)间接估算速度,延迟和误差较大。传统毫米波雷达或激光雷达能测速,但原理和精度与多普勒激光雷达不同。多普勒激光雷达在直接、精准测量瞬时速度方面具有独特优势,是实现高质量预测的理想传感器。如果用其他传感器替代,需要对速度估计模块和后续的预测、风险计算模块进行相应的适配和强化。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~龙哥点评
论文创新性分数:★★★★☆ 将闭环评估从“已执行动作”扩展到包含“未执行动作”,并设计双层架构和精巧的风险指标来实现这一思想,在MPC自动调参领域是一个清晰且有力的创新。结合多普勒LiDAR进行赋能,也增强了方法的完整性和说服力。
实验合理度:★★★★☆ 在权威仿真平台CARLA上进行测试,对比了有代表性的开环、闭环及非调参基线方法。实验设计涵盖了轨迹可视化、安全距离动态分析、通过率统计和多项性能指标,较为全面。随机障碍物场景的设置也具有一定挑战性。
学术研究价值:★★★★☆ 提出了一种提升闭环学习效率的新范式(proactive closed-loop),对运动规划、强化学习与控制领域的交叉研究有启发价值。其“利用预测进行主动优化”的核心思路可迁移到其他序贯决策问题中。
稳定性:★★★☆☆ 在论文所述的仿真环境中表现稳定。但其稳定性高度依赖感知预测模块的准确性。在传感器噪声大或障碍物行为高度不确定的真实场景中,预测失误可能导致风险误判,进而引发非最优甚至不安全的决策。
适应性以及泛化能力:★★★☆☆ 方法框架本身具有一定的泛化性。但实验仅在车辆避障的特定运动模型和随机运动障碍物场景下验证。对于行人、非结构化环境、或需要复杂交互(如合流、让行)的场景,其适应能力有待进一步验证。
硬件需求及成本:★★☆☆☆ 需要多普勒激光雷达作为核心传感器,目前该传感器成本较高。同时,双层调优机制(特别是慢层的梯度反向传播)引入了额外的计算开销,对车载计算平台的算力有一定要求。
复现难度:★★★☆☆ 算法描述清晰,但完整复现需要搭建CARLA仿真环境、集成多普勒LiDAR仿真或真实数据接口、并实现MPC求解与梯度反向传播的协同。对工程实现能力要求较高,论文未提及代码是否开源。
产品化成熟度:★★☆☆☆ 目前处于高水平仿真验证阶段。迈向产品化需要克服传感器成本、复杂场景下的预测可靠性、车规级计算平台的实时性保障等一系列工程挑战。可作为高级别自动驾驶系统的前瞻性技术储备。
可能的问题:论文实验场景中的障碍物运动模式(随机匀速)相对理想化。HPTune性能的上限受限于预测模块的准确性,在行为不确定的动态环境中(如突然加速变道的车辆),方法的有效性需要更严格的压力测试。损失函数中各项权重的选择(η1, η2, η3)也需要更多的分析和论证。
[1] Alexey Dosovitskiy, et al. "CARLA: An open urban driving simulator." CoRL 2017.[6] Ruihua Han, et al. "RDA: An Accelerated Collision-Free Motion Planner for Autonomous Navigation in Cluttered Environments." IEEE RA-L 2023. (对比方法:开环调参)[11] Ran Tao, et al. "DiffTune-MPC: Closed-Loop Learning for Model Predictive Control." IEEE RA-L 2024. (对比方法:闭环调参)[13] Xiaojing Zhang, et al. "Optimization-Based Collision Avoidance." IEEE TCST 2020. (对比方法:非调参基线)[16] Bruno Hexsel, et al. "DICP: Doppler Iterative Closest Point Algorithm." arXiv:2201.11944 2022. (多普勒LiDAR相关算法)*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的"阅读原文",查看更多原论文细节哦!

想让你的自动驾驶算法也拥有“预判”能力吗?🚗💨 加入龙哥读论文粉丝群,与众多自动驾驶、机器人领域的小伙伴一起探讨前沿技术!
扫描下方二维码或者添加龙哥助手微信号加群:kangjinlonghelper。
一定要备注:研究方向+地点+学校/公司+昵称(如 自动驾驶+北京+清华+龙哥),根据格式备注,可更快被通过且邀请进群。