🚗 龙哥读论文知识星球来了!还在为自动驾驶的传感器标定、语言指令歧义、极端场景泛化而头大?星球每日为你拆解端到端驾驶、多模态融合、世界模型等前沿论文,让你快速掌握核心方法,避开前人踩过的坑!👇扫码加入「龙哥读论文」知识星球,和龙哥一起驶向AI驾驶的未来~
龙哥推荐理由:
这篇论文瞄准了当前基于视觉语言模型(VLM)的自动驾驶的几个核心痛点:传感器配置敏感、语言指令模糊、极端场景处理能力弱。它提出的AppleVLM,通过引入可变形注意力、显式空间规划策略和思维链微调,不仅大幅提升了模拟器中的驾驶性能,更难得的是,未经真实数据微调就直接在户外AGV上成功完成了闭环驾驶。这为端到端自动驾驶的可扩展性和实际部署提供了非常有价值的思路。
原论文信息如下:
论文标题:
AppleVLM: End-to-end Autonomous Driving with Advanced Perception and Planning-Enhanced Vision-Language Models
发表日期:
2026年02月
发表单位:
未明确标注
原文链接:
https://arxiv.org/pdf/2602.04256v1.pdf
想象一下,你坐在一辆自动驾驶车里,告诉它:“下一个路口左转。” 车子点点头,到了路口一把方向……结果给你拐到对向车道上去了!😅 你赶紧解释:“我是让你沿着最左边的车道左转,不是让你逆行啊喂!”
这就是当前基于视觉语言模型的自动驾驶(VLM-based Autonomous Driving)面临的一个尴尬:人类的语言充满了模糊性,而机器却常常“死脑筋”。
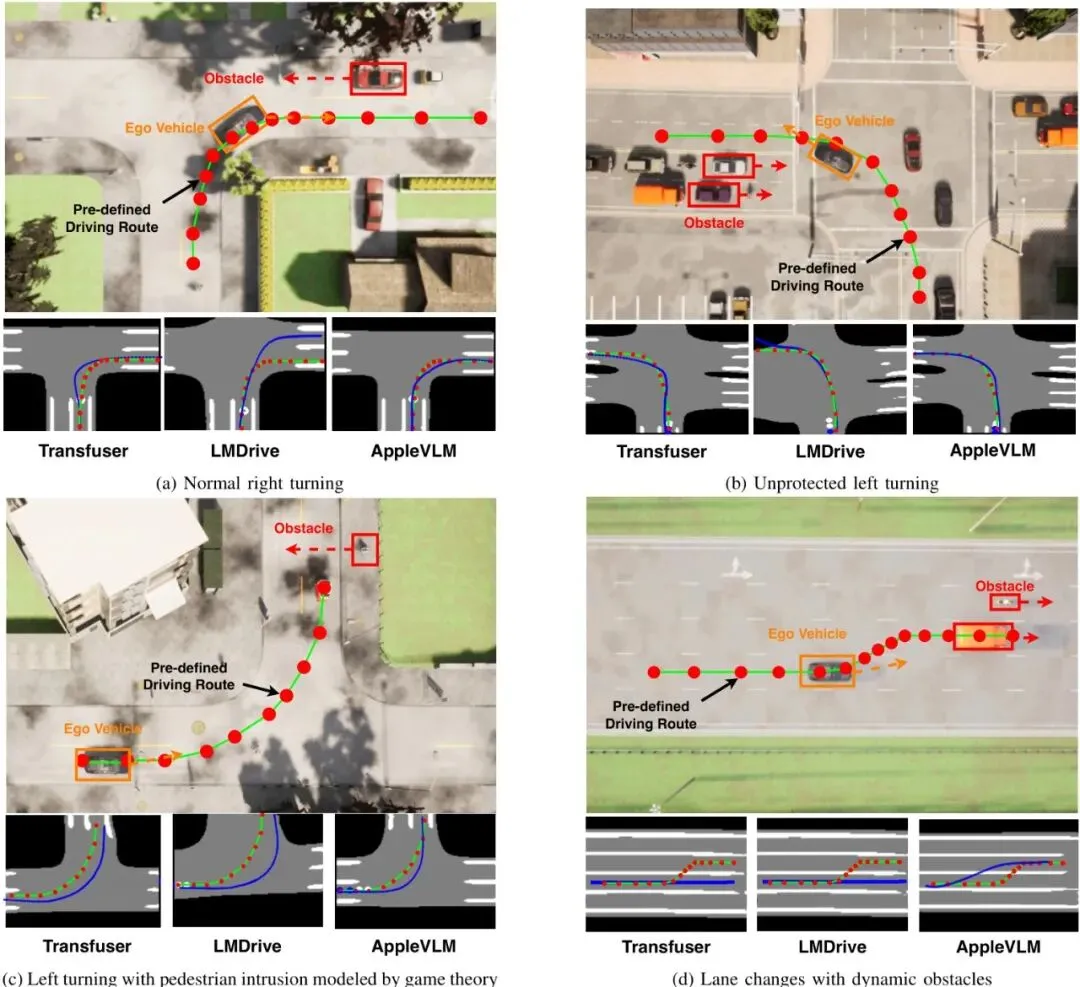
最近,一篇名叫AppleVLM的论文(注意,这里的Apple不是指水果公司🍎,而是Advanced Perception and PLanning-Enhanced的缩写)提出了一个很有意思的解决方案。它不仅让车子更能听懂“人话”,还意外地解决了另外两个老大难问题,甚至直接把模型搬上真实小车,在复杂户外环境里成功开起来了!图7:AppleVLM(左)与基线模型在复杂路口场景下的驾驶轨迹对比可视化图。可以看到AppleVLM的轨迹(蓝色)更贴近专家轨迹(绿色),且能更好地处理动态障碍物(红色虚线框)。
挑战:现有VLM驾驶模型的三大痛点
要理解AppleVLM的创新,我们先得看看它想解决什么问题。目前的VLM驾驶模型,虽然看起来很炫,但想真正“上路”,还卡在三个关键的痛点上:
大部分模型在训练时,摄像头的安装位置、角度、分辨率都是固定的。这就好比给一个厨师规定了锅必须放在灶台正中央、盐罐必须放左手边,他才能做出好菜。一旦你把摄像头往旁边挪了5厘米,或者换了个不同焦距的镜头,模型可能就“懵”了,感知能力大幅下降。这严重限制了模型在不同车型、不同传感器配置上的可扩展性。
就像开头的例子,“左转”这个指令缺乏精确的空间信息。在多车道情况下,是转进最左车道,还是中间车道?模型只能靠“猜”,或者依赖训练数据中的统计偏见,这容易导致驾驶轨迹摇摆或不安全。自然语言作为一种高度抽象的表示,天生就难以精确描述复杂的空间几何关系。
模型通常在标准驾驶数据集上训练,对于极端场景或长尾案例(比如突然窜出的行人、车辆故障占道等)处理能力很弱。这就好比一个学生只刷常规题库,一上考场遇到没见过的压轴题就直接傻眼。在真实的开放道路环境中,这种对“生题”的无力感,是安全性的巨大隐患。AppleVLM:三大创新点解决核心难题
针对这三大痛点,AppleVLM祭出了三把“手术刀”,刀刀对准要害:
创新一:自带“柔焦镜头”的视觉编码器为了解决传感器敏感问题,AppleVLM在视觉编码器中引入了可变形注意力机制(Deformable Attention)。你可以把它想象成一个能自动对焦、自由调整视野的智能镜头。它不再僵硬地看图像的固定网格位置,而是学习去关注那些真正重要的特征区域,无论这个区域因为摄像头位姿变化而移到了画面的哪个角落。同时,这个机制还能在时间(连续多帧)和空间(多视角图像与激光雷达点云)上融合信息,让感知更鲁棒。
创新二:给语言配上“空间导航图”为了解决语言模糊的问题,AppleVLM创新性地引入了一个规划策略编码器。它不依赖抽象的语言,而是基于视觉感知结果,生成一张鸟瞰图(Bird‘s-Eye-View, BEV),并利用一个叫EPSILON的规划算法,在这张图上标出安全的、可行的驾驶走廊(就像图3里那些彩色的管道)。这张精确的“空间导航图”与模糊的语言指令相结合,极大地消除了歧义,告诉模型:“左转”的精确空间含义是“驶入这个橙色走廊所定义的几何空间”。
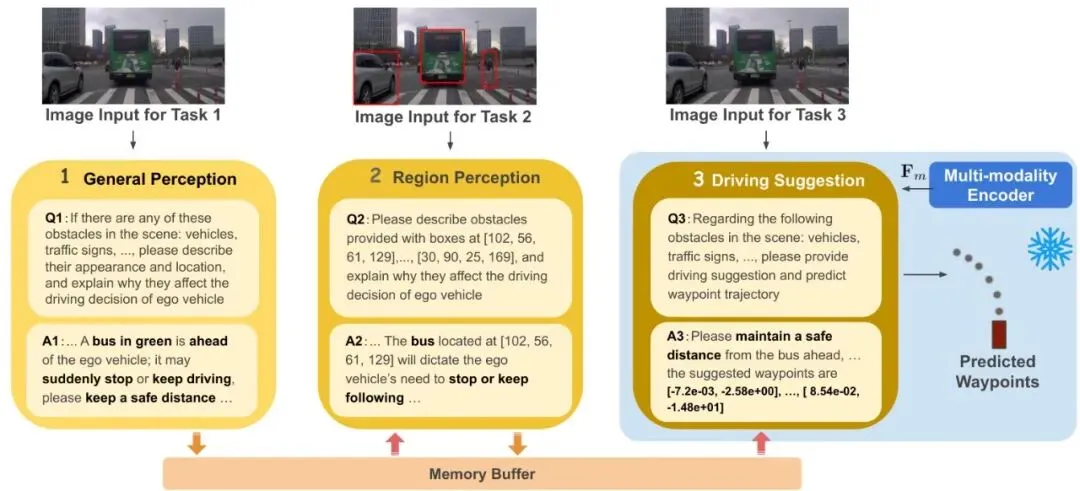
创新三:用“思维链”给大脑做极端场景特训为了让模型能应对罕见但危险的场景,AppleVLM在训练其核心的VLM解码器时,用上了思维链(Chain-of-Thought, CoT)技术,并专门使用极端场景数据集进行微调。这个过程不是直接让模型输出驾驶点,而是让它像人类一样分步推理:先识别道路上有什么关键物体(通用感知),再分析特定区域内的物体为何危险(区域感知),最后综合给出驾驶建议(驾驶建议)。通过这种循序渐进的“特训”,模型处理复杂、陌生场景的能力得到了强化。
核心架构揭秘:多模态编码与思维链解码
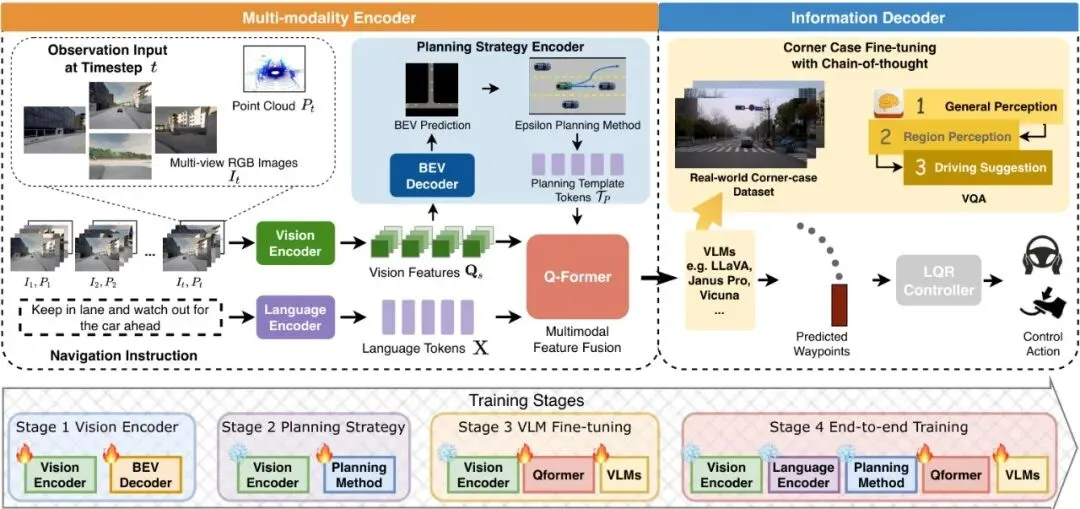
把这三把“手术刀”组装起来,就形成了AppleVLM完整的“编码器-解码器”架构。整个系统像一条精密的流水线,我们通过下面的总览图来一探究竟。图1:AppleVLM整体架构图。它包含多模态编码器(视觉、语言、规划策略)和信息解码器(经思维链微调的VLM)。训练分四阶段进行:视觉编码器BEV预训练、规划策略编码器学习、VLM极端场景微调、整个系统的端到端训练。
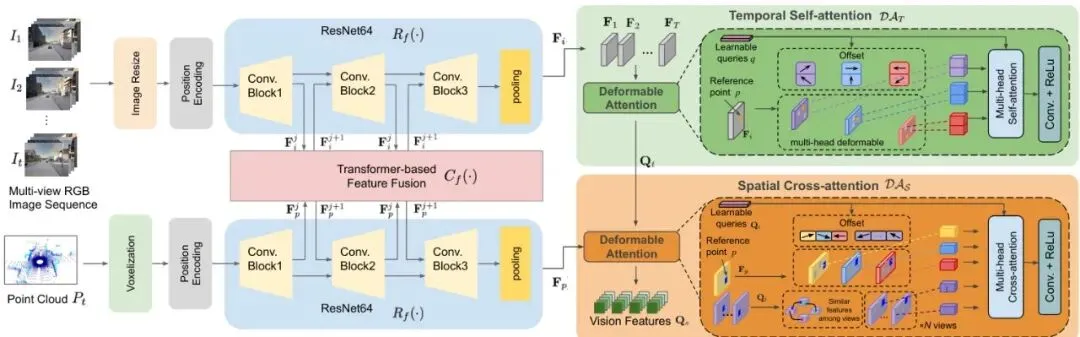
1. 视觉编码器:输入是连续多帧的多视角RGB图像和激光雷达点云。点云先被体素化处理成伪图像。然后,图像和伪图像分别通过一个共享权重的RegNet64(图中标注为ResNet64,应为笔误)网络提取特征,并在每个卷积块后通过Transformer的交叉注意力进行特征融合。图2:视觉编码器细节。核心是可变形注意力机制(Deformable Attention),它分别在时间维度(多帧间)和空间维度(图像与点云间)进行特征关联与融合。
关键就在这里!融合后的特征会经过一个时间自注意力块和一个空间交叉注意力块,这两个模块都基于可变形注意力。这使得模型能够动态地关注不同时间、不同视角下相关的特征点,从而对传感器位置变化“脱敏”。
2. 语言编码器:将“前方路口左转”这类导航指令,通过Word2Vec等工具转化为词向量序列,并加入一些为自动驾驶设计的特殊令牌(如[CLS], [Distance])。
3. 规划策略编码器(核心创新):这是AppleVLM的“空间翻译官”。它接收视觉编码器的输出,通过一个BEV解码器生成包含可行驶区域、车道线、周围物体状态的语义分割图。然后,EPSILON规划算法在这张图上工作,生成多条可能的未来轨迹和对应的时空安全走廊。
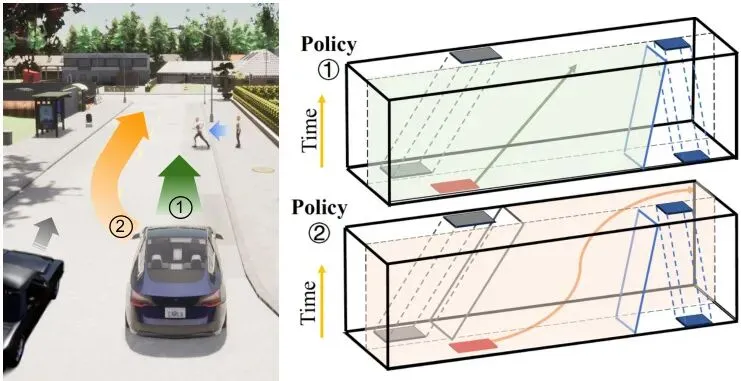
图3:EPSILON规划方法生成的驾驶走廊示例。左图为驾驶场景,右图显示了其他车辆(灰色)和行人(蓝色)的预测走廊,以及为自车规划出的两条高评分策略(橙色和绿线)所定义的约束走廊。
这些走廊被编码成规划模板令牌,为模型提供了精确的、显式的空间几何指导。
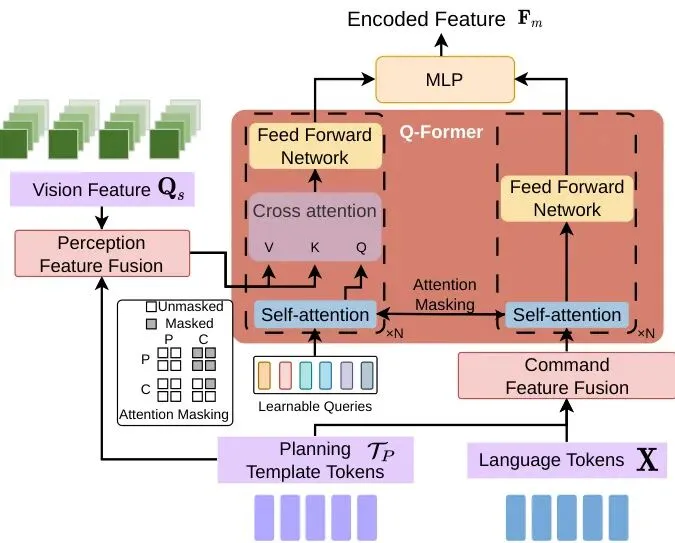
4. 特征融合:来自视觉、语言、规划三路的特征如何统一?AppleVLM借鉴了BLIP-2模型中的Q-Former架构。规划令牌分别与视觉特征、语言特征进行交叉注意力融合,形成感知特征和指令特征,再由Q-Former中的可学习查询(Query)抽取最相关的信息,最终完成多模态对齐。图4:基于Q-Former的规划模板令牌与视觉、语言特征融合过程。
融合后的多模态特征被送入信息解码器,其核心是一个经过思维链微调的VLM骨干网络(如Janus Pro)。这个微调过程是其应对极端场景的关键。图5:VLM的思维链微调流程。包含通用感知、区域感知和驾驶建议三个逐步推理的任务。在端到端驾驶时,只使用最后一个“驾驶建议”任务来生成路径点,保证效率。
在最终驾驶时,这个微调好的VLM是冻结的。它接收融合特征和“驾驶建议”的提问,直接输出一系列未来路径点。这些路径点再通过一个线性二次调节器(LQR)控制器,转化为方向盘转角、油门、刹车等具体的控制信号,驱动车辆行驶。
实验验证:模拟器全面领先,真实世界成功驾驶
理论很丰满,效果如何?论文在自动驾驶研究常用的CARLA模拟器和真实户外环境中进行了双重验证。
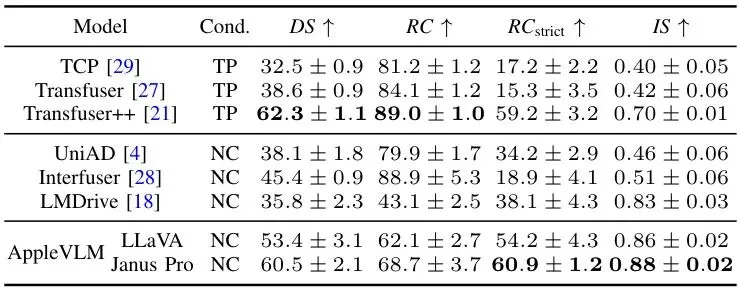
在CARLA的LangAuto和Longest6两个权威闭环驾驶基准测试上,AppleVLM与7个前沿的端到端驾驶模型同台竞技。评价指标包括驾驶得分(DS,综合评分)、路线完成率(RC)、违规分数(IS)。表I:LangAuto基准上8个端到端驾驶模型的性能对比。AppleVLM在驾驶得分(DS)和路线完成率(RC)上均取得最佳成绩。表II:Longest6基准上8个端到端驾驶模型的性能对比。AppleVLM同样在核心指标上领先。
从表格可以清晰看到,AppleVLM在两个测试集上都取得了全面的领先优势,尤其是在综合驾驶得分上,相比之前的VLM驾驶SOTA模型LMDrive有显著提升。
更硬核的测试来了:传感器配置扰动测试。研究人员故意改变了测试时摄像头的位置、角度和分辨率(模拟不同车型的安装差异),然后观察模型性能的下降程度。表III:传感器配置变化对所有模型的影响测试(在LangAuto基准上)。AppleVLM在各项扰动下的性能下降幅度最小,展现出极强的鲁棒性。
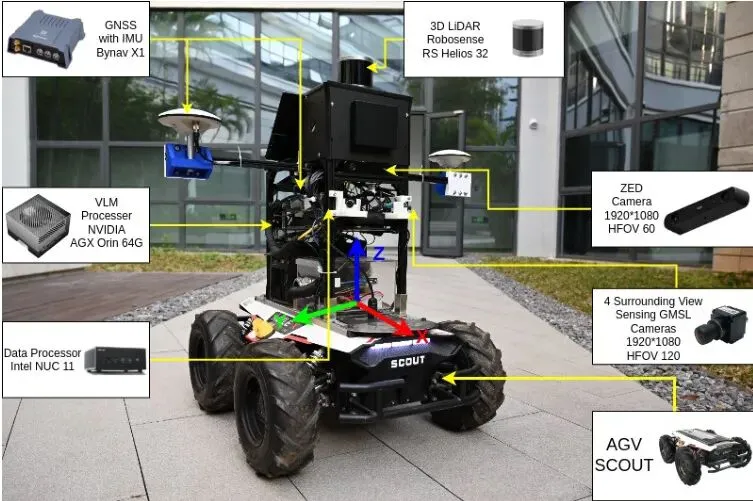
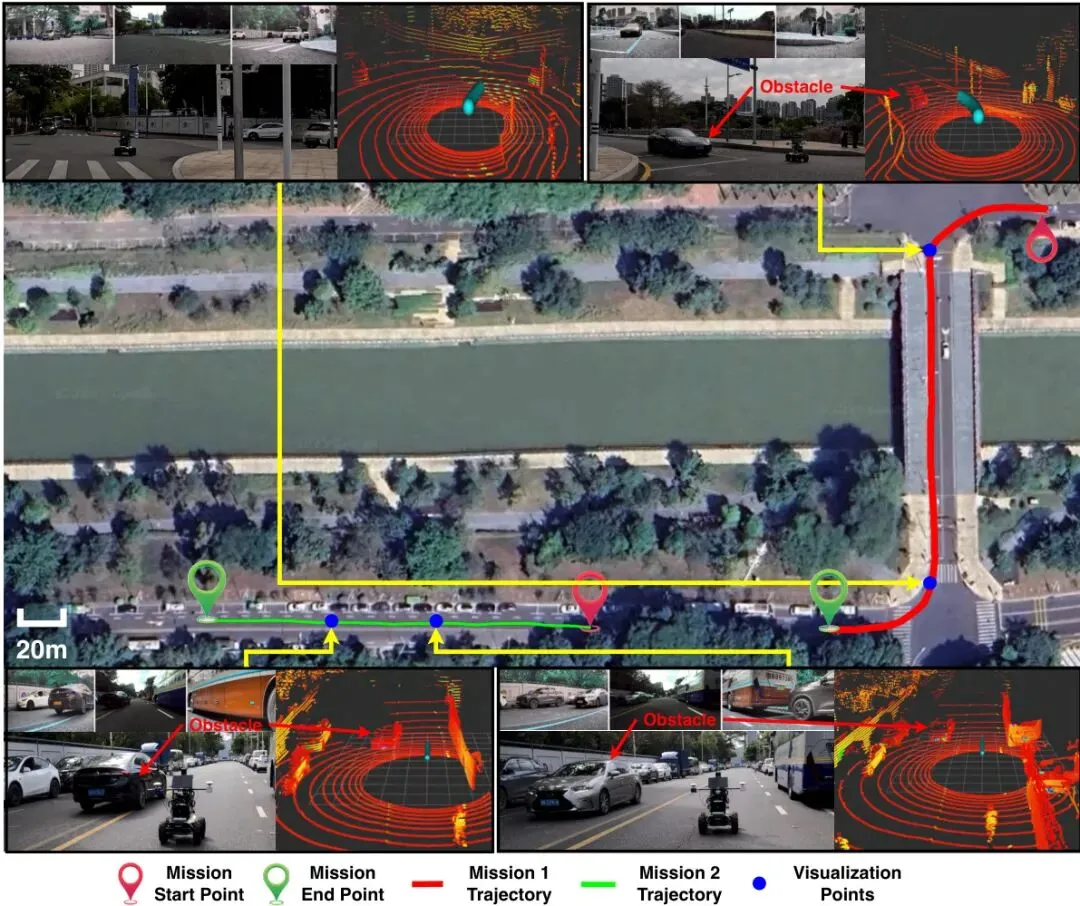
结果令人印象深刻!在摄像头位置、角度、分辨率均发生改变的最严苛测试下,对比模型性能暴跌(DS从~70跌至~30),而AppleVLM的驾驶得分依然能保持在50以上,稳定性远超其他模型。这直接验证了其可变形注意力视觉编码器的强大威力。模拟器成绩再好,也只是“纸上谈兵”。这篇论文最厉害的一点是,他们真的把训练好的AppleVLM模型直接部署到了一台真实的自动导引车(AGV)平台上,在未经任何真实数据微调的情况下,进行了户外环境的闭环驾驶测试。图9:真实世界户外环境中的闭环驾驶。绿色线为“直行”任务轨迹,红色线为“转弯”任务轨迹。放大的蓝色点显示了车辆在动态行人和车辆环绕下的实际路径点。
车辆成功完成了包含直行、转弯等指令的驾驶任务,并能实时避让动态的行人和车辆。这个实验虽然规模不大,但意义重大。它强有力地证明了,通过精心设计的架构(特别是对传感器鲁棒的视觉编码和引入显式规划),端到端VLM驾驶模型具备从模拟器向真实世界迁移和部署的潜力,无需昂贵的真实数据大规模收集与标注。
论文还进行了详尽的消融实验,分别验证了可变形注意力、规划策略编码器和思维链微调各自带来的性能增益,结果均表明这些设计是有效且必要的。
未来展望与启示
AppleVLM展示了一条非常有前景的技术路径:将强大的基础VLM与领域特定的、鲁棒的感知和规划先验知识相结合。它的成功给了我们几点重要启示:
1. “混合智能”是关键:完全依赖数据驱动的“黑箱”VLM在安全攸关的驾驶任务中存在风险。像规划策略编码器这样引入显式的、可解释的几何与规则表示,能与VLM的语义理解能力形成优势互补,提升系统的可靠性和可调试性。
2. 泛化能力来自架构设计:对传感器变化的鲁棒性不应仅靠海量多配置数据来“硬记”,而应通过像可变形注意力这样的机制内嵌到模型架构中,使其具备本质上的适应能力,这是实现跨平台部署的基础。
3. 模拟到现实的鸿沟可以跨越:这项工作是端到端驾驶领域少有的、成功进行零样本真实世界部署的案例之一。它表明,通过在模拟器中构建足够丰富和多样的训练环境,并辅以恰当的架构和训练策略(如CoT微调),模型是能够获得强大泛化能力的。
当然,前路依然漫长。模型的计算效率、对更复杂长尾场景(如恶劣天气、极端光照)的应对、以及大规模真实道路上的长期安全验证,都是需要持续探索的课题。龙迷三问
VLM(Vision-Language Model)到底是什么?VLM,即视觉语言模型,是一种能够同时理解和处理图像与文本信息的人工智能模型。它通常由一个视觉编码器(理解图片)和一个语言模型(理解文本并生成文本)组合而成。在自动驾驶中,VLM可以接收摄像头画面和“前方左转”的语音指令,综合理解后输出驾驶决策。
BEV(Bird‘s-Eye-View)在自动驾驶中为什么重要?BEV,即鸟瞰图,是从车辆正上方垂直向下看的视角。它将周围环境(车辆、车道线、行人等)投影到一个统一的二维平面上。这个视角消除了透视变形,使得物体间的空间关系和距离度量变得非常直观和准确,极其适合进行路径规划和碰撞检测,因此是现代自动驾驶感知和规划模块的核心表示形式。
CoT(Chain-of-Thought)思维链具体是怎么工作的?思维链是一种让大模型进行分步推理的技术。简单来说,不是直接问模型“答案是什么?”,而是引导它“让我们先思考第一步:看到了什么?第二步:这些东西为什么重要?第三步:所以我们应该怎么做?”。通过将复杂问题分解成一系列中间推理步骤,并展示这些步骤,模型更容易得出正确的最终答案。在AppleVLM中,就是用“感知->分析->决策”的三步CoT来微调模型处理极端场景的能力。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~龙哥点评
论文创新性分数:★★★★☆
整体创新性优秀。核心创新点明确且具有针对性:1)将可变形注意力引入端到端驾驶的视觉编码,以提升传感器鲁棒性;2)创造性地增加一个“规划策略编码器”作为中间模态,用显式空间几何信息去偏语言指令。这两个设计思路清晰,解决了领域内公认的痛点。思维链微调属于现有技术的精妙应用,整合得当。实验合理度:★★★★★
实验设计非常扎实且具有说服力。不仅在两个主流模拟器基准上进行了全面的SOTA对比,还设计了极具洞察力的“传感器扰动”测试来直接验证其核心优势。消融实验完整,覆盖了所有关键模块。最加分的是进行了真实的户外AGV闭环驾驶演示,虽然场景相对简单,但这是从模拟到现实的关键一步,极大地提升了论文价值。学术研究价值:★★★★★
研究价值很高。论文为端到端自动驾驶,特别是VLM-based方向,提供了一个非常系统且工程实现思路清晰的框架。它证明了“基础VLM + 领域专用鲁棒感知/规划先验”这条技术路线的巨大潜力,尤其是在提升模型可部署性(传感器鲁棒)和可解释性(引入规划表示)方面,对后续研究和工业落地都有很强的启发意义。稳定性:★★★☆☆
在模拟器定义的环境和有限的真实场景中展现出良好的稳定性,特别是对传感器配置的变化鲁棒性突出。但由于其核心仍是数据驱动的深度学习模型,在面对完全未知的、超出训练数据分布的极端对抗性场景时,其稳定性无法得到理论保证。真实世界的长期闭环测试规模尚小,需更大规模验证。适应性以及泛化能力:★★★★☆
适应性表现优异,尤其体现在对不同传感器配置的泛化上,这是其设计的主要目标之一。通过极端场景数据微调和CoT训练,在模拟器内对复杂、长尾场景的泛化能力也有提升。但泛化能力的上限仍然受限于训练数据的多样性和模拟器与真实世界的差异。硬件需求及成本:★★☆☆☆
计算成本和硬件需求较高。模型包含大型VLM骨干(如Janus Pro)、多个编码器和复杂的注意力机制。尽管推理时冻结了VLM的绝大部分参数,但整体模型规模依然庞大,需要较强的GPU进行实时推理,在车载嵌入式平台上的部署和优化将是一个挑战。复现难度:★★☆☆☆
复现难度中等偏高。论文描述了四阶段训练流程,涉及多个模块的预训练、微调和整合,工程复杂度高。需要复现CARLA数据收集、EPSILON规划器、以及获取极端场景数据集。论文未提及代码是否开源,若不开源,完全复现将非常困难。产品化成熟度:★★☆☆☆
目前仍处于前沿研究向原型验证过渡的阶段。其在有限真实场景的成功演示证明了可行性,但距离车规级产品化还有很长的路要走。需要解决计算平台的适配、系统的功能安全认证、在更广泛真实道路上的大规模验证与迭代等一系列工程和法规问题。可能的问题:论文本身质量很高,若硬要挑刺,其真实世界测试的规模和复杂性相较于模拟器实验略显单薄,未能充分展示在极端复杂城市场景(如无保护左转、密集车流切入)下的能力。此外,多阶段训练带来的工程复杂性和时间成本,在实际应用中也是一个需要考虑的因素。
[1] Yuxuan Han, Kunyuan Wu, et al. “AppleVLM: End-to-end Autonomous Driving with Advanced Perception and Planning-Enhanced Vision-Language Models”. arXiv preprint arXiv:2602.04256, 2026. (本论文)[18] Hao Shao, et al. “LMDrive: Closed-Loop End-to-End Driving with Large Language Models”. arXiv preprint arXiv:2312.07488, 2023. (文中引用的LangAuto基准来源)[27] Kashyap Chitta, et al. “Transfuser: Imitation with Transformer-Based Sensor Fusion for Autonomous Driving”. IEEE TPAMI, 2022. (文中引用的Longest6基准及对比方法来源)[39] 等. “EPSILON: An Efficient Planning and Imitation Learning Framework for Autonomous Driving”. (文中使用的规划算法)[43] 等. “CODA-LM: A Corner Case Dataset for Language Model Evaluation in Driving”. (文中使用的极端场景数据集)*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的"阅读原文",查看更多原论文细节哦!

🚗 想和更多自动驾驶、机器人领域的小伙伴一起交流前沿技术?
欢迎加入龙哥读论文粉丝群,
扫描下方二维码或者添加龙哥助手微信号加群:kangjinlonghelper。
一定要备注:研究方向+地点+学校/公司+昵称(如 自动驾驶+北京+清华+龙哥),根据格式备注,可更快被通过且邀请进群。