Waymo World Model × Genie 3:面向规模化、可控、超逼真驾驶模拟的技术拆解
关键词:Waymo;DeepMind;Genie 3;世界模型;自动驾驶仿真;多传感器生成;可控模拟
图1 Waymo 在官方博客发布“Waymo World Model”时使用的主视觉(来源:Waymo Blog, 2026-02-06)
自动驾驶研发的核心矛盾一直很朴素:道路场景无限多,但真实测试的成本、风险和速度都有限。为了解决“见得不够多”的问题,行业早早把仿真当作主战场——让自动驾驶系统在虚拟世界里先跑够里程,再把能力带回真实道路。Waymo 在官方博客中披露:Waymo Driver 已完成“接近 2 亿英里”的完全自动驾驶真实里程,而在虚拟世界中则进行“数十亿英里”的测试与训练。[1]
今天,Waymo 把仿真这条路推到新阶段:发布 Waymo World Model,一套“生成式”仿真系统,目标是用更逼真的世界、更强的可控性与更大规模的推演,提前覆盖那些现实里难以采集、难以复现、但又可能决定安全边界的长尾场景。[1] DeepMind CEO Demis Hassabis 也在社交媒体上转发并评价这一方向,强调世界模型在模拟与智能体能力上的潜力。[3]
1 从“画得像”到“推得动”:世界模型在自动驾驶仿真里的位置
在机器学习语境下,“世界模型(World Model)”通常指一种能把环境状态压缩进内部表征,并能在这个表征上进行时间推进的模型:它不仅生成观测(例如视频帧、点云),还要能回答“如果采取某个动作,下一刻会发生什么”。DeepMind 在 Genie 3 的官方介绍中将世界模型定义为:利用对世界的理解来模拟其部分方面,从而让智能体预测环境如何演化,以及动作如何改变环境。[2]
把这个定义放到自动驾驶里,世界模型的价值不止是“做更漂亮的仿真”,而是把仿真变成可采样的反事实引擎:给定同一段真实记录,你可以用不同动作/不同天气/不同交通参与者配置,生成多条可能轨迹,系统化扫描决策边界与安全裕度。[1]
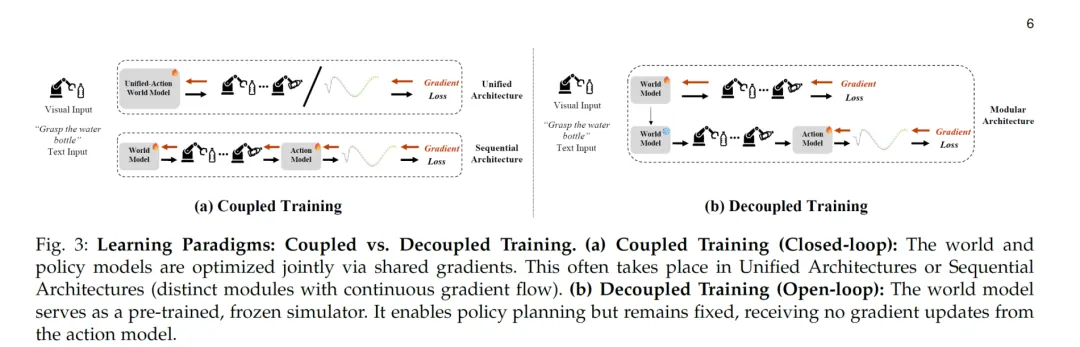
图2 “闭环耦合训练”与“开环解耦训练”的对比示意,可用来理解仿真/世界模型与策略系统的接口(来源:Wang et al., arXiv:2601.17067, PDF 第 6 页)
为什么自动驾驶更需要“会推演”的仿真?因为驾驶是一个高度交互系统:你的一次减速会改变后车的相对速度,你的一次并线会改变周围车流的空隙结构。传统基于规则或几何的仿真能覆盖大量常规情况,但对于“极端天气”“罕见物体”“多主体复杂互动”这类长尾事件,往往面临建模成本高、逼真度不足、分布偏差大的问题。[1]
Waymo 在博客里明确把 Waymo World Model 视作其仿真体系的生成核心:负责生成“超逼真(hyper-realistic)”的模拟环境,并把仿真作为其“可证明安全 AI(demonstrably safe AI)”三大支柱之一。[1] 这也暗示了一个判断:当仿真被放到安全论证链条里,它需要的不只是视觉可信度,更要在多模态一致性、可控性与规模性上达到工程可用的门槛。
2 Waymo World Model:一套面向驾驶域的“生成式仿真引擎”
Waymo 对外公开的核心信息可以浓缩为三句话:[1]
- 底座:Waymo World Model 构建在 DeepMind 的 Genie 3 之上,并针对驾驶域做适配;
- 目标:生成可交互、可控、逼真度高的 3D 环境,用于大规模自动驾驶仿真;
- 输出:不仅生成相机视角图像,还生成与 Waymo 硬件体系匹配的激光雷达(LiDAR)等多传感器输出。
Waymo 特别强调,Waymo World Model 不是只“复刻”道路数据,而是借助 Genie 3 预训练获得的广泛世界知识,去模拟现实里难以采集的极端与长尾事件,例如龙卷风、洪水、火灾,甚至“偶遇大象”等。[1]
3 Genie 3 是什么:从“视频生成”到“可交互世界”的基础设施
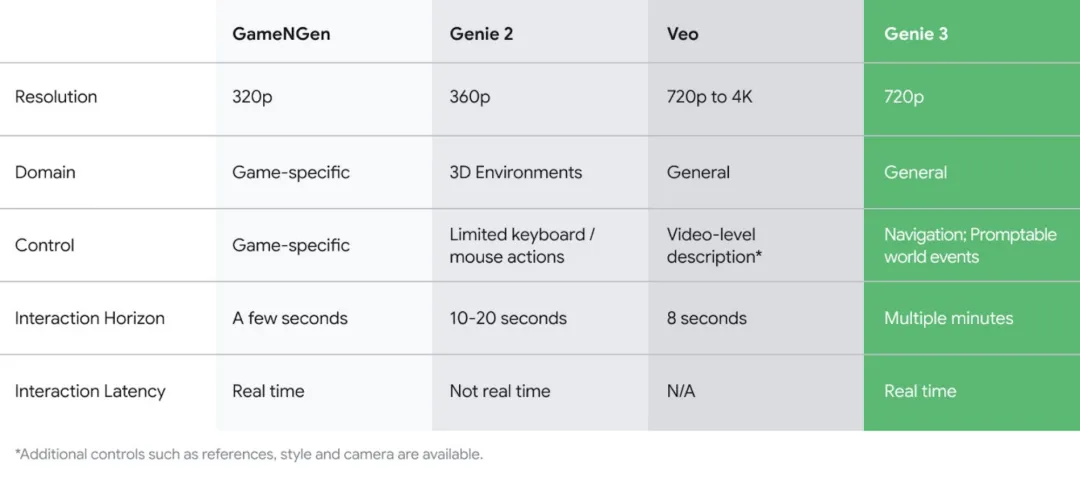
Genie 3 是 DeepMind 在 2025 年公开的通用世界模型。官方描述中,它可以根据文本提示生成“可实时导航”的动态世界,实时交互帧率为 24 FPS,并能在 720p 分辨率下保持“几分钟”级别的一致性。[2] DeepMind 还给出了与 GameNGen、Genie 2、Veo 等系统的能力对比,突出 Genie 3 在交互时长与实时性上的提升。[2]
图3 DeepMind 官方对比:Genie 3 与 GameNGen、Genie 2、Veo 在分辨率、控制方式、交互时长、交互延迟等维度的差异(来源:Google DeepMind Blog, 2025-08-05)
图4 DeepMind 展示的 Genie 3 交互世界示例拼图(来源:Google DeepMind Blog, 2025-08-05)
对自动驾驶而言,Genie 3 的“通用世界知识”价值在于:驾驶数据天然偏向“常态成功样本”,极端与罕见事件很难规模化采集;而通用视频预训练能让模型对自然现象、物体外观、光照天气等具备更广覆盖的先验,再通过驾驶域后训练把先验对齐到传感器与道路几何。[1][2]
Waymo 在博客中明确写到,他们通过“专门的后训练(specialized post-training)”把 Genie 3 的 2D 视频世界知识迁移到 3D LiDAR 输出,这是其适配驾驶域硬件体系的关键一步。[1]
4 三把“控制旋钮”:把世界模型变成工程可用的仿真工具
Waymo 将其可控性机制总结为三类控制:[1]
1)Driving action control(驾驶动作控制):仿真对给定的驾驶输入做响应;
2)Scene layout control(场景布局控制):可编辑道路结构、信号灯状态、其他交通参与者行为;
3)Language control(语言控制):用自然语言修改时间、天气等条件,甚至生成完全合成的长尾场景。
这三者的共同目标,是把“生成式仿真”的不确定性收敛到工程可调的维度上:你不仅能看见一个逼真的世界,还能让它按你想要的方式变化,从而做系统化测试。
4.1 驾驶动作控制:反事实(counterfactual)推演的接口
Waymo 在博客里给出典型用法:对于过去记录的一次真实驾驶事件,可以在仿真中沿着原始路线复现,也可以切换到“完全不同的新路线”,并比较系统在不同决策下是否更安全、更高效。[1] 这类能力对应“反事实推演”:同一世界初态,不同动作,得到不同未来。
值得注意的是,Waymo 在该段落中对比了“纯重建式仿真方法”在路线差异较大时可能出现的视觉崩溃(例如 3D Gaussian Splats/3DGS 在缺失观测区域的退化),并强调“完全学习式”的 Waymo World Model 能维持更好的逼真度与一致性。[1]
4.2 场景布局控制:把“道路系统”当作可编辑的生成条件
场景布局控制更贴近工程团队的日常需求:变更路口拓扑、切换信号灯状态、对其他交通参与者进行“选择性放置”,或者对道路布局施加“自定义突变”,从而构造高覆盖的测试集。[1]
在自动驾驶验证里,这类控制常用于两件事:
- 做覆盖性:把同一驾驶技能(例如无保护左转)放进不同几何/车流条件下;
- 做边界性:系统化逼近“刚好会失败”的临界条件,以定位策略与感知的薄弱环节。[1]
4.3 语言控制:统一调参入口,让长尾分布“可被生成”
语言控制被Waymo 描述为“最灵活的工具”:可以调整一天中不同时段(dawn/morning/noon…)、不同天气(cloudy/foggy/rainy…),也能直接提示生成长尾合成场景。[1]
从仿真的角度看,它把大量原本需要手工脚本化的参数空间,映射到更高层的语义空间。工程收益在于:构造场景的成本下降,探索场景的速度上升。对于需要覆盖“低照度”“强反光”“浓雾”等感知困难条件的自动驾驶系统,这种快速生成与变体扩增尤为关键。[1]
5 从“随手拍”到“多传感器仿真”:把现实视频转成可用的测试世界
Waymo 专门用一节讲“Converting Dashcam Videos”:他们声称,Waymo World Model 可以把普通相机、手机或行车记录仪拍到的视频,转成多模态仿真,并以“Waymo Driver 会如何看到这段场景”的方式呈现。[1]
Waymo 给出的动机很直接:这条路线能带来“最高程度的真实感与事实性(highest degree of realism and factuality)”,因为仿真来自真实拍摄素材。[1] 对工程团队而言,这相当于把“互联网上的大量长尾视频”变成可用的测试入口——当然,最终能到什么程度取决于后训练与多模态对齐质量,但从公开表述来看,Waymo 把它作为一条重要的现实数据补充通路。
6 可扩展推演:长 rollout 与计算效率的平衡
在自动驾驶仿真里,很多关键场景需要“慢慢发生”:例如狭窄车道会车、复杂车流中的多次交互。Waymo 指出,仿真越长,计算越难、稳定质量越难,并给出解决方案:通过一个“更高效的 Waymo World Model 变体”,在显著降低计算量的同时维持高逼真度与高保真,从而支持大规模长时推演;他们还展示了“4×速度播放”的长 rollout 示例。[1]
这段表述对应一个现实约束:如果世界模型只能生成短片段,它更像内容生成;只有当它能在可接受成本下滚动更久,它才更像“仿真基础设施”。Waymo 的公开表达明确把“规模化推演”放在了产品化目标里。[1]
7 这套系统在 Waymo 体系里怎么用:安全验证链条的一个关键环节
Waymo 把仿真放进“可证明安全 AI”的三大支柱之一,并把 Waymo World Model 定位为生成模拟环境的组件。[1] 换句话说,它不是一个孤立的研究 demo,而是要进入验证、回归与部署流程的工程能力。
从公开材料可读出的接口大致包括:[1][4]
- 输入侧:语言提示、驾驶输入、场景布局,以及来自真实行驶/外部视频的观测;
- 输出侧:相机与 LiDAR 等多传感器合成数据,供“Waymo Driver”在仿真里闭环运行;
- 目标侧:用长尾与极端事件构造更严苛的安全基准,让系统在现实遇到之前先在虚拟世界里“见过、练过、通过过”。
此外,Waymo 早前公开过基于 Gemini 的端到端多模态驾驶模型 EMMA,强调利用大模型的世界知识理解复杂道路场景。[4] 这类工作与“世界模型仿真”在概念上是一致的:一个负责“理解与决策”,一个负责“生成可推演的环境”,共同指向更强的闭环研发基础设施。
8 对行业意味着什么:生成式仿真可能带来的三点变化
在不引入无依据推测的前提下,基于Waymo 与 DeepMind 的公开表述,可以归纳出生成式仿真对自动驾驶研发的三类“确定性收益方向”:
·覆盖密度提升:依托通用视频预训练与语言/布局控制,长尾场景的构造成本下降,能更快形成系统化测试集。[1][2]
·反事实能力增强:驾驶动作控制把“同一初态、多种决策”的对比推演变成标准接口,有利于定位策略边界与安全裕度。[1]
·多模态一致性强化:Waymo 明确强调生成相机与 LiDAR 的多传感器输出,并通过后训练把 2D 世界知识迁移到 3D LiDAR,这对自动驾驶硬件栈尤其关键。[1]
9 延伸阅读与开源入口
Waymo World Model 本身并未在官方博客中提供开源代码入口,但围绕数据、评测与相关研究,已有多条公开路径可继续跟进:
·Waymo 官方博客:The Waymo World Model: A New Frontier For Autonomous Driving Simulation(主信息源)。[1]
·DeepMind 官方博客:Genie 3: A new frontier for world models(底座模型公开介绍)。[2]
·Waymo Open Dataset(官方开源数据集与工具链)。[5]
·Waymo Research(官方研究主页/论文入口,可用于追踪 3D 生成、仿真与感知相关工作)。[6]
·视频世界模型机制化综述(arXiv:2601.17067)用于补足“状态—动力学—评测”框架。[7]
参考文献
[1] Waymo. The Waymo World Model: A New Frontier For Autonomous Driving Simulation. Waymo Blog, 2026-02-06. https://waymo.com/blog/2026/02/the-waymo-world-model-a-new-frontier-for-autonomous-driving-simulation
[2] Google DeepMind. Genie 3: A new frontier for world models. DeepMind Blog, 2025-08-05. https://deepmind.google/blog/genie-3-a-new-frontier-for-world-models/
[3] Demis Hassabis. Post about the Waymo World Model (X/Twitter). 2026-02 (post id: 2019827916385972517). https://x.com/demishassabis/status/2019827916385972517
[4] Waymo. Introducing EMMA: An End-to-End Multimodal Model for Autonomous Driving (powered by Gemini). Waymo Blog, 2024-10-??. https://waymo.com/blog/2024/10/introducing-emma
[5] Waymo Research. Waymo Open Dataset (GitHub). https://github.com/waymo-research/waymo-open-dataset
[6] Waymo Research portal (selected publications & projects). https://waymo.com/research/
[7] Luozhou Wang et al. A Mechanistic View on Video Generation as World Models: State and Dynamics. arXiv:2601.17067, 2026. https://arxiv.org/abs/2601.17067


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
