论文标题:Vega: Learning to Drive with Natural Language Instructions
作者:Sicheng Zuo, Yuxuan Li, Wenzhao Zheng, Zheng Zhu, Jie Zhou, Jiwen Lu
链接:https://arxiv.org/abs/2603.25741
研究背景
Vision-language-action models已重塑自动驾驶,将语言融入决策过程。然而,现有方法仅利用语言进行场景描述或推理,缺乏根据多样化用户指令进行个性化驾驶的灵活性。自动驾驶需要理解复杂的交通场景、行人行为和道路规则,同时还需要能够响应各种类型的自然语言指令。
⚠️ 核心挑战
当前视觉-语言-动作模型面临的核心挑战在于:无法根据多样化的自然语言指令生成个性化驾驶策略。用户指令可能包括变道、转弯、避让等多种需求,而模型需要理解这些指令并生成对应的驾驶行为。此外,多轨迹预测能力也是实现灵活驾驶的关键。
技术方法
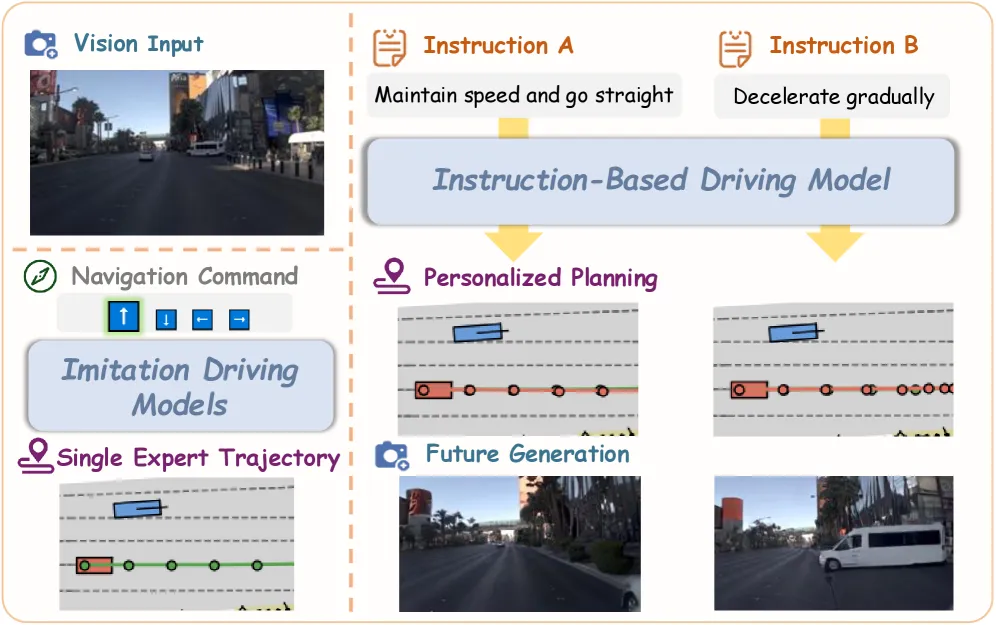
🔹 Vega 模型架构
Vega是一种统一的视觉-语言-世界-动作模型,能够根据自然语言指令进行轨迹预测和规划。模型采用多模态融合机制,将视觉信息、语言指令和世界模型进行协同建模。
🔹 指令理解与对齐
通过大规模驾驶数据集InstructScene进行预训练,模型学会了理解多样化用户指令并将其映射到相应的驾驶行为。指令类型涵盖变道、转向、速度调节等常见驾驶操作。
🔹 多轨迹预测能力
Vega能够在同一场景下根据不同指令预测多条轨迹,实现多样化的驾驶策略生成。这一能力使模型能够根据用户偏好提供个性化的驾驶体验。
实验结果
📊 数据集与基线对比:在InstructScene数据集上,Vega相比现有方法在指令跟随精度和轨迹预测准确性上均有显著提升,验证了方法的有效性。
📊 零样本泛化能力:模型展现出良好的零样本泛化能力,能够处理训练集中未见过的新指令类型,证明了学习到的表示具有较强的迁移性。
✅ 核心结论
本文提出Vega,一种统一的视觉-语言-世界-动作模型,用于指令引导的自动驾驶。Vega通过大规模指令数据集训练,实现了对多样化自然语言指令的灵活响应,并在多轨迹预测任务上展现出卓越性能。项目主页:https://zuosc19.github.io/Vega
总结与展望
本文提出Vega,一种统一的视觉-语言-世界-动作模型,用于指令引导的自动驾驶。Vega通过大规模指令数据集训练,实现了对多样化自然语言指令的灵活响应,并在多轨迹预测任务上展现出卓越性能。项目主页:https://zuosc19.github.io/Vega
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
