自动驾驶匝道汇入:风险约束强化学习与模型预测控制
论文摘要
高速公路匝道汇入是自动驾驶最具挑战性的场景之一。汇入车辆既要实时决策,又要在复杂动态交通中兼顾安全和效率。常规强化学习(RL)擅长通过试错学习策略,却缺乏显式的安全约束;模型预测控制(MPC)能够施加严格约束,但依赖精确模型。针对这种“智能但不安全”与“安全但僵硬”的矛盾,论文提出 安全增强强化学习与MPC集成(SARMI)框架。该框架在高层使用 受约束软行动者‑评论家(SAC‑Discrete) 结合 增广拉格朗日法 求解约束马尔可夫决策过程(CMDP),通过 高斯风险场 将 MPC 预测的未来状态转换为风险代价,实现主动规避碰撞。低层则利用 MPC 将离散动作转换为可行轨迹,不直接设置碰撞约束而由风险场与安全机制保障。论文还设计了 动作掩模(过滤无效动作)与 动作屏蔽(替换不安全动作)双重安全机制。理论分析证明增广拉格朗日 SAC‑Discrete 的原‑对偶解等价性,实验显示该方法在各种交通密度下比基线算法更安全、更高效,成功率提升显著、碰撞率显著下降。总体而言,SARMI 建立了一个同时关注安全、效率和舒适性的匝道汇入决策与规划框架,拓展了安全强化学习与MPC结合的研究边界。
一、研究背景与挑战
1.1 匝道汇入的复杂性
高速匝道汇入需要车辆在有限加速道内完成加速、变道并与主车道车辆安全融合。环境中既有自主车(AV),也有多数人类驾驶车辆(HV)。当前方法常陷于两种极端:过度保守导致堵塞或延迟,过度激进又易触发碰撞。因此,决策系统必须在安全、效率和舒适之间权衡。
1.2 RL 与安全约束的矛盾
强化学习通过奖励驱动的试错来优化策略,但传统 RL 仅通过奖励函数约束行为,缺乏硬性安全限制。安全强化学习(Safe RL)引入成本约束,但在复杂安全约束下仍存在不稳定和约束违反的问题。另一方面,MPC 能显式施加约束,但对模型准确性要求高、计算开销大。如何同时利用 RL 的自适应性和 MPC 的约束能力,是本研究的出发点。
1.3 解决思路概述
论文提出的 SARMI 框架建立在 分层决策与规划 思想上:高层 RL 负责生成离散动作(左转、右转、加速、减速、保持),低层 MPC 将动作转化为轨迹并预测未来状态。在高层中,通过引入高斯风险场构建成本函数,结合增广拉格朗日 SAC‑Discrete 求解 CMDP;同时通过动作掩模与动作屏蔽双机制保证探索过程和执行过程的安全。该方法既解决了 RL 缺乏安全约束的问题,又兼顾了 MPC 的动态预测能力,形成闭环反馈。
二、整体框架与方法设计
2.1 SARMI 总体架构
下面的图展示了 SARMI 的整体框架。高层决策层输出离散动作,低层运动规划层根据动作生成参考路径并执行 MPC 优化。
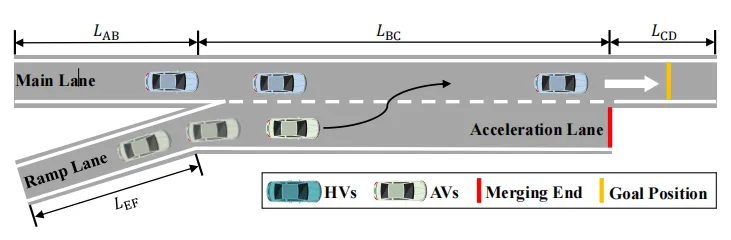 图1 匝道汇入场景示意(取自 Fig.1)
图1 匝道汇入场景示意(取自 Fig.1)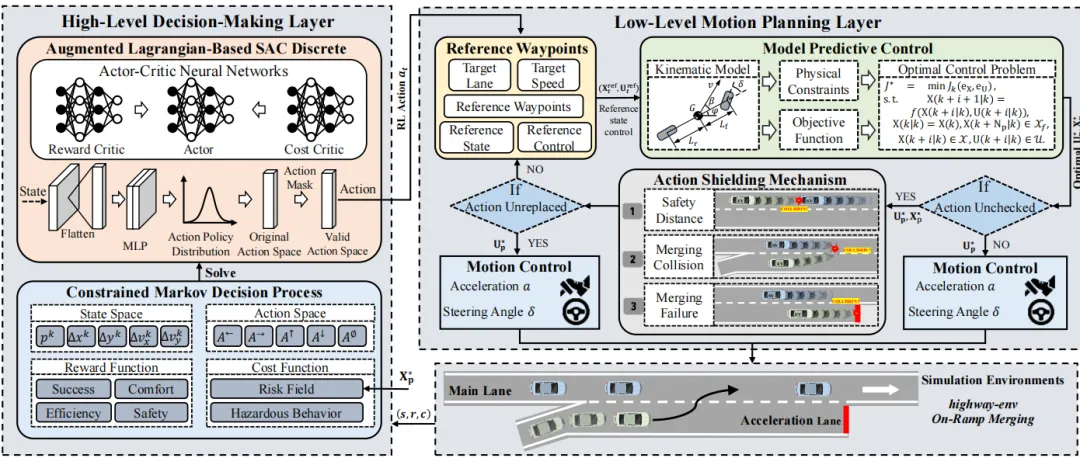 图2 SARMI框架概述(取自 Fig.2)
图2 SARMI框架概述(取自 Fig.2)如上图2所示,框架包含两个主要部分:
- 高层决策层(RL):将匝道汇入视为 CMDP,通过增广拉格朗日 SAC‑Discrete 求解,输出离散动作。此层利用高斯风险场和约束成本衡量未来碰撞风险,避免短视决策。
- 低层运动规划层(MPC):接收高层动作后生成目标车道和目标速度,再采用 MPC 优化得到实际控制输入,并向高层反馈预测轨迹,用于风险评估。
2.2 关键创新点
- 风险场成本设计:与传统只在碰撞时增加成本不同,论文利用 MPC 预测的未来轨迹构建 二维高斯风险场,根据周围车辆位置、速度和道路边界持续评估碰撞风险。
- 增广拉格朗日 SAC‑Discrete:在 SAC‑Discrete 中加入二次惩罚项,构建增广拉格朗日函数,使得对偶更新更加稳定,理论上证明其原‑对偶解等价性。
- 动作掩模(AMM)与动作屏蔽(ASM):AMM 在采样阶段利用规则屏蔽违反交通规则或物理限制的动作,ASM 在执行前基于 MPC 预测检查动作是否导致安全距离不足、合流碰撞或合流失败,并替换为保守的减速动作。
三、安全强化学习策略
3.1 CMDP 建模
高层决策层将匝道汇入建模为 受约束马尔可夫决策过程 (CMDP) ,描述为八元组 。其中状态 包含自车与可观测周车的相对距离、速度等信息,动作集合 包含左转、右转、加速、减速和静止五种离散动作。
奖励设计
奖励函数综合考虑成功、舒适、效率和安全四个目标:
其中:
- 舒适奖励:惩罚纵向和横向加加速度以及方向盘角速度的平方,权重为 。
成本设计
成本函数由风险场成本和危险行为成本组成:
- 风险场成本:基于高斯函数构建周车风险场 和道路边界风险场 ,通过 MPC 预测的未来轨迹积分得到总风险 。
- 危险行为成本:对于触发碰撞(与合流终点、周车或预测碰撞)分别给予 2.0、2.0 和 0.1 的惩罚。
CMDP 求解目标是在最大化期望折扣奖励的同时,使期望折扣成本不超过阈值 。
3.2 增广拉格朗日 SAC‑Discrete
传统拉格朗日 SAC 在处理复杂约束时易产生振荡。论文构建了增广拉格朗日函数:
通过交替更新策略 和拉格朗日乘子 ,并逐渐放大惩罚因子 ,使约束收敛更稳定。理论分析证明当 足够大时,增广拉格朗日对偶问题的最优解与原问题一致。
该算法采用双重 Q 网络评估奖励和成本值。策略网络输出离散动作概率 ,通过 软值函数评估期望值。具体损失函数和梯度更新公式见式 (23)-(30) 和 (31)-(36),本推文不再逐一列出,以便聚焦核心思路。
策略更新流程
图3展示了策略更新流程。经验通过交互收集后,算法使用小批量更新奖励、成本评论者网络和策略网络,同时更新温度参数和拉格朗日乘子。软更新和惩罚因子更新周期性进行,确保训练稳定。
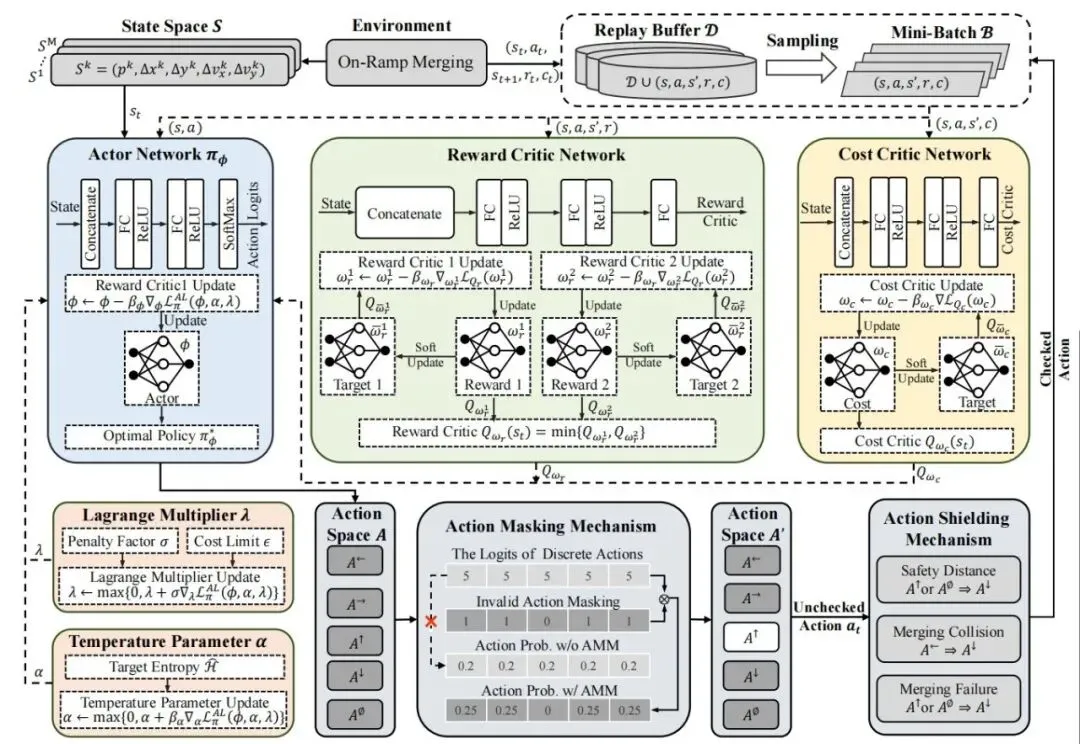 图3 策略更新流程与网络架构(取自 Fig.3)
图3 策略更新流程与网络架构(取自 Fig.3)3.3 动作掩模与动作屏蔽
为了进一步保障安全,论文引入 动作掩模 (Action Masking Mechanism, AMM) 和 动作屏蔽 (Action Shielding Mechanism, ASM) 双机制:
- 动作掩模:根据交通规则过滤无效动作,如在匝道禁止左右转、车速已达到限速时禁止加速或减速等。掩模将无效动作的 Softmax logit 设为极小值,使其采样概率约为零,重新归一化后只从合法动作中采样。
- 动作屏蔽:对采样的合法动作,用 MPC 预测未来轨迹判断是否违反安全距离、造成合流碰撞或错过合流时机。当动作落入不安全集合,替换为保守的减速动作。
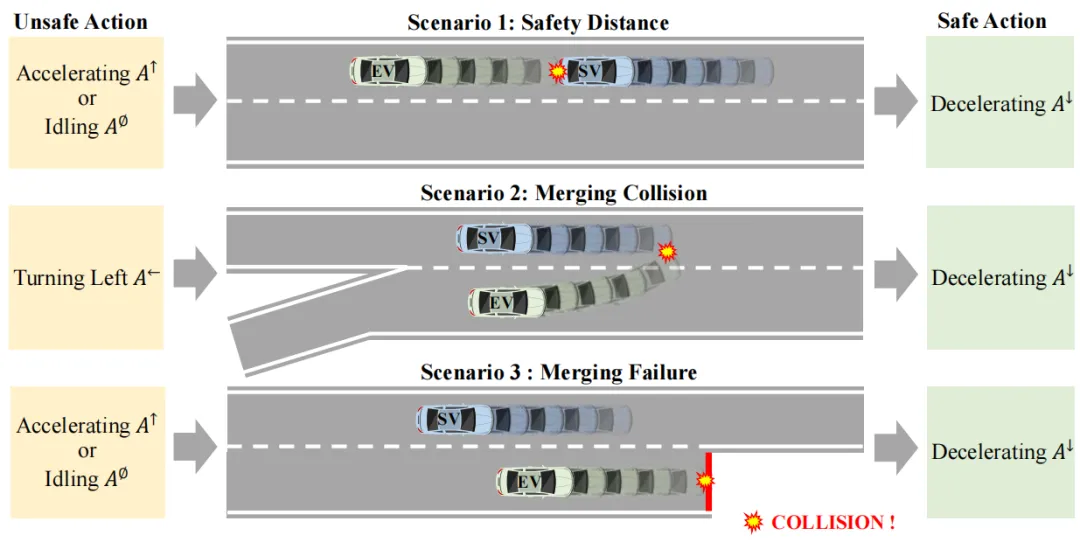 图4 预测式动作屏蔽机制示意(取自 Fig.4)
图4 预测式动作屏蔽机制示意(取自 Fig.4)该双重机制在探索和执行两阶段防患于未然,显著降低碰撞率。
四、低层运动规划与模型预测控制
4.1 参考路径生成
高层离散动作决定了目标车道和目标速度。车辆当前位置转换为 Frenet 坐标,在预测时域内以恒定目标速度生成参考纵向和横向序列,随后再转换回笛卡尔坐标获取参考位姿。控制参考被设为零,鼓励控制输入最小化。
4.2 运动学模型与优化
低层采用 运动学自行车模型:
其中 为侧滑角, 为轴距。线性化并离散化后得到状态误差方程 。
目标是最小化跟踪误差和控制输入:
满足控制约束(加速度和转角限值)及速度约束。最终形成的非线性优化问题通过 CasADi/Ipopt 求解,输出最优控制序列,其中首项用于当前控制。
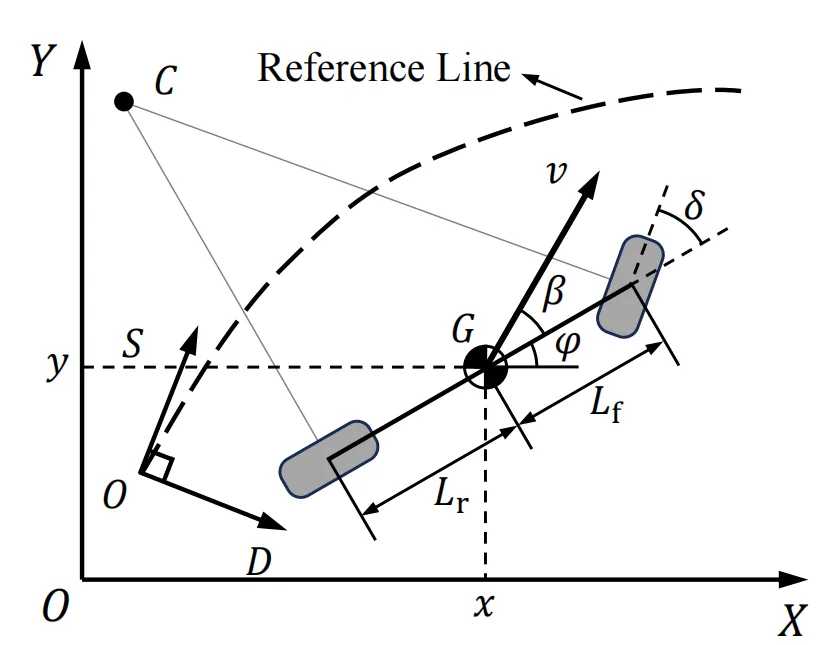 图5 车辆运动学自行车模型(取自 Fig.5)
图5 车辆运动学自行车模型(取自 Fig.5)低层 MPC 还提供预测轨迹给风险场计算和动作屏蔽使用,实现决策层与规划层的闭环联动。
五、理论分析
论文对增广拉格朗日 SAC‑Discrete 的最优性进行了严格证明。假设最优策略和拉格朗日乘子 满足 Karush‑Kuhn‑Tucker 条件,则存在有限常数 ,使当惩罚因子 时,增广拉格朗日对偶问题 (17) 的最优解与原始问题 (15) 相同。证明通过引入松弛变量将约束转化为等式,再比较增广拉格朗日函数与普通拉格朗日函数的 Hessian,从而保证在足够大的 下二次项正定,满足二阶充分条件。此外,论文提出改进的乘子更新策略:
该更新减少约束违反并抑制梯度振荡,提升收敛速度。
六、实验设计与结果分析
6.1 仿真环境与评估指标
论文基于 highway‑env 搭建匝道汇入环境:主车道长度 400 m、加速道 70 m、匝道 80 m,车宽 5 m。周车速度随机分布在 17–27 m/s,平均车速 22 m/s,交通密度通过车间距决定并设置低、中、高三档。评估指标包括 成功率、平均奖励、平均成本、碰撞率、平均时间(完成合流时间)和 平均速度。
6.2 收敛性能
下图6展示了不同方法的训练曲线。SARMI 在综合奖励、成本和碰撞率方面都快速收敛,最终奖励最高、成本和碰撞率最低。
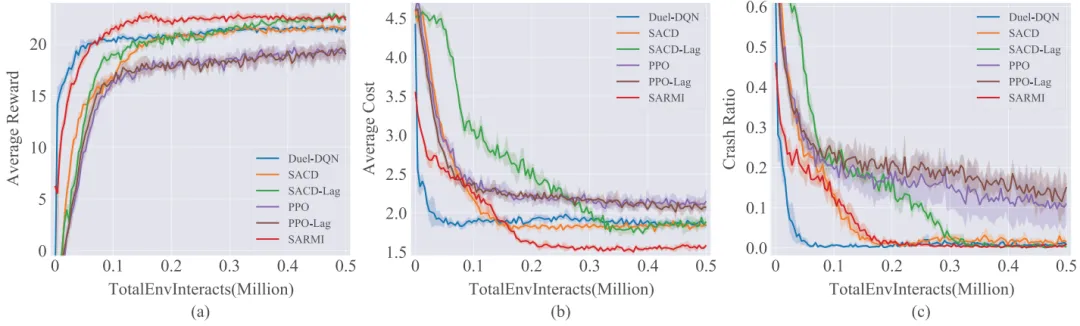 图6 训练收敛表现对比(取自 Fig.6)
图6 训练收敛表现对比(取自 Fig.6)相比之下,Duel‑DQN 收敛快但奖励略低,PPO 收敛慢且表现最差;其拉格朗日版本 PPO‑Lag 未能显著改善。SACD-Lag 虽引入约束但收敛速度较慢。SARMI 显示了增广拉格朗日和安全机制在约束强化学习中的优势。
6.3 测试表现与对比
SARMI 与 Duel‑DQN、SACD 和 PPO 在不同交通密度下进行了对比。结果如表 II 所示,SARMI 的成功率在低、中、高密度下分别达到 99.00%、95.48% 和 92.24%,比其他方法平均提升 6–15 个百分点。其碰撞率几乎为零(低密度 0.00%,中高密度 0.08%),成本显著降低。同时,SARMI 在平均时间和平均速度上略优于其他方法,实现安全与效率的平衡。
下图7展示了在低、中、高密度下 SARMI 的合流过程可视化。绿色车辆为自车,轨迹显示在不同时间段逐渐完成合流,体现出稳定、安全的驾驶行为。
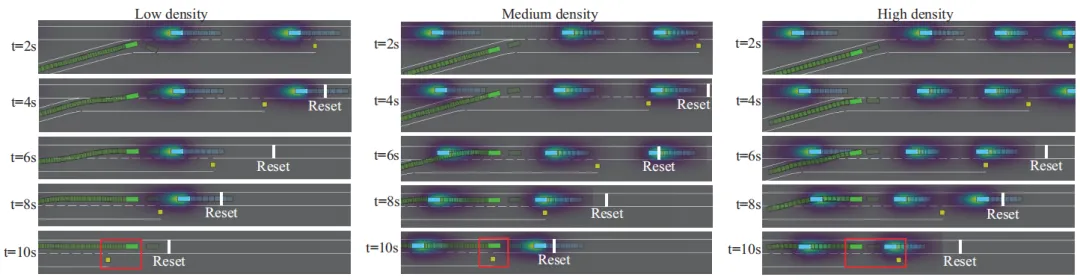 图7 不同交通密度下SARMI测试表现可视化(取自 Fig.7)
图7 不同交通密度下SARMI测试表现可视化(取自 Fig.7)6.4 消融实验
论文还进行了三种消融:移除增广拉格朗日法(ALM)、移除动作掩模(AMM)、移除动作屏蔽(ASM)。结果表明,去除 ALM 会显著增加成本;去除 AMM 对最终性能影响不大,但训练初期收敛更慢;去除 ASM 会导致训练初期碰撞率和成本大幅上升,最终奖励也下降。此外,移除风险场会降低收敛速度并使早期碰撞波动增加。
七、讨论与创新亮点
- 风险敏感决策:不同于只惩罚碰撞的成本设计,SARMI 使用高斯风险场对未来轨迹进行持续评估,实现提前规避风险。
- 增广拉格朗日安全强化学习:引入二次惩罚并改进乘子更新,使 RL 在复杂安全约束下更稳定,并通过理论证明了最优性。
- 双重安全机制:结合规则驱动的动作掩模与预测驱动的动作屏蔽,分别改善探索阶段和执行阶段的安全性。
- RL 与 MPC 深度融合:高层利用 MPC 预测反馈风险,低层利用 RL 动作生成参考路径,共享信息闭环更新,避免了传统串联 RL+MPC 的割裂问题。
- 全面实验验证:论文在不同密度、多随机种子下进行大量仿真,评估成功率、效率、舒适性等多维指标,验证了方法的通用性和优势。
八、结论与展望
本文解析了《Risk‑Constrained On‑Ramp Merging via Safety‑Augmented Reinforcement Learning and Model Predictive Control》一文的主要内容,阐述了作者如何在匝道汇入场景中通过 SARMI 框架实现安全、高效、舒适的决策与规划。该方法以高斯风险场量化风险,使用增广拉格朗日 SAC‑Discrete 求解 CMDP,并通过动作掩模与屏蔽双机制保证执行安全。理论分析证明了优化的收敛性和最优性;实验证明在不同交通密度下,SARMI 在成功率、碰撞率、效率和舒适性上均优于多种基线算法。未来研究可考虑引入感知和模型的不确定性,以及在真实车辆和更复杂交通场景中的验证。
文章须知
链上镖师团队:常文婕(AEIC)、祁园园、王一航、张仁义(EIC)、张晓乐、张巧巧
原文链接:10.1109/JIOT.2026.3676898
原文链接见文末,或扫下方交流群二维码。群内实时更新推文及原文 pdf,方便专家学者随时获取(若二维码失效,请翻阅扫描最新文章的二维码)。