撕开模型压缩的遮羞布,探寻不可妥协的安全底线
 自动驾驶大模型上车,安全底线不容妥协
自动驾驶大模型上车,安全底线不容妥协💥 开篇暴击:危险的“大跃进”
现在的智驾算法圈,有一种非常危险的“大跃进”风气。
大家为了把动辄几十亿参数的端到端大模型(如 UniAD、VLA 架构)塞进算力捉襟见肘的车端域控制器里,疯狂地搞模型压缩:剪枝(Pruning)、量化(Quantization)、稀疏化(Sparsification)。
汇报的 PPT 上写得极其漂亮:“采用 INT8 量化,模型体积缩小 75%,推理延迟(Latency)从 200ms 打到 40ms,且开源数据集的 mAP(平均精度均值)只掉了 0.5%!”
作为带过量产项目的老兵,我每次看到这种数据,后背都会冒冷汗。
为什么?因为深度学习是一个极度非线性的高维黑盒。mAP 只掉了 0.5%,在统计学上看似完美,但在自动驾驶这种“容错率为零”的场景里,这丢失的 0.5% 如果恰好发生在一个罕见的“前车紧急加塞(Cut-in)”或者“弱光环境下的异形障碍物”特征上,到了规控端(Planning & Control),就会演变成一次导致车毁人亡的“幽灵刹车”或“直撞”。
在自动驾驶这个命悬一线的行业里,“跑得快”只是及格线,“不出错”才是不可妥协的底线。今天,我们就把大模型部署的遮羞布撕开,深度拆解一条极其严苛的 P0 级标准准出作业流程(SOP),以及如何用数学手段进行白盒级的“多维一致性校验”。
🧠 底层逻辑:扒皮抽筋式的多维校验
一个经过深度加速优化的模型,绝对不能直接拿去上车。无论是采用 PTQ(训练后量化:模型训练完再进行压缩) 还是 QAT(量化感知训练:在训练过程中就模拟压缩误差),它都必须经历一套标准闭环:
需求分析 ➔ 算子剖析与极致压榨 ➔ A/B 测试(闭环仿真/影子模式) ➔ 准出交付。
在这个闭环中,最核心的命脉是多维一致性校验(Multi-dimensional Consistency Verification)。这绝不是跑个测试集看看准确率就完事的,它必须从以下三个维度进行“扒皮抽筋”式的比对:
1. 数值一致性(Numerical Consistency):防微杜渐的 Tensor 级对齐
我们不能只看最终输出,必须把大模型像切香肠一样切开,进行逐层特征输出校验和梯度校验。当我们将高精度的 FP32 权重压缩为 INT8 时,必然会产生截断误差。我们需要严格监控其相对误差或余弦相似度(Cosine Similarity)
如果在网络深层,相似度突然从 0.99 掉到 0.85,说明这一层极有可能出现了激活值异常(Activation Outliers)。特别是 Transformer 架构中,暴力的线性量化会直接抹杀关键注意力权重,此时必须引入 SmoothQuant 等算法平滑异常值。
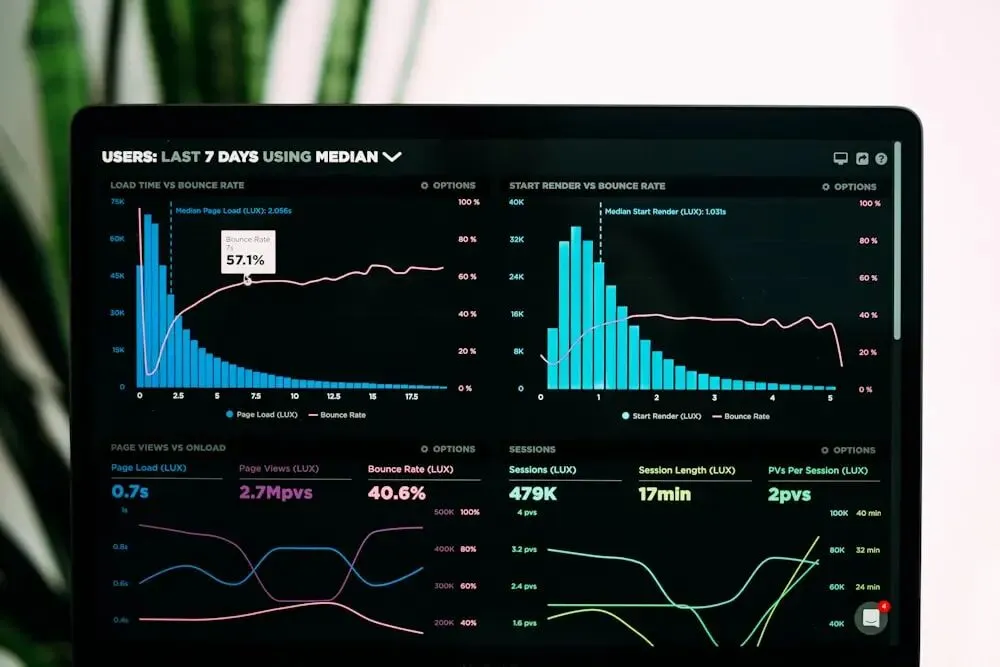 统计一致性校验:警惕量化带来的“置信度坍塌”与分布漂移
统计一致性校验:警惕量化带来的“置信度坍塌”与分布漂移2. 统计一致性(Statistical Consistency):分布不漂移
在感知或预测任务中,我们不仅看类别预测对不对,更要看“置信度(Confidence Score)的分布”。这里通常引入KL 散度(Kullback-Leibler Divergence)来衡量原始模型与量化模型概率分布的差异:
D_KL(P || Q) = Σ P(x) * log( P(x) / Q(x) )
如果量化后分布变得极其扁平,KL 散度飙升,意味着模型变得“极度不自信”。在下游的规控状态机里,这种不自信会导致车辆在路口频繁地“犹豫、点刹、画龙”。
3. 功能一致性(Functional Consistency):业务指标咬合
这是最贴近真实驾驶体感的一环。关注的核心不再是 Loss 曲线,而是规控硬指标:最大加加速度(Max Jerk)、碰撞时间(TTC)、横向轨迹偏移误差。
利用 MLOps 工具将技术降级与业务痛点咬合。例如:“即便 INT8 导致纵向测距误差增加 0.2 米,但只要最坏 TTC 仍大于安全阈值(如 1.5s),且推理延迟降至 50ms 争取了更多刹车时间,该方案即判定达标。”
📓 知猷回忆录:凭空消失的清障车
这段避坑史,是实打实用血汗和惊吓砸出来的。
记得 2022 年底,在某头部大厂带队搞高阶 L4 无人车量产架构时,工程组接到了一个 P0 级任务:将核心的 3D 占据网络(Occupancy Network)和轨迹预测模型,从云端的 FP32 暴力塞进车端的某国产 100+ TOPS 算力芯片中。
第一版 PTQ 跑完,工程兄弟们很兴奋,延迟直接砍了 70%,在内部的 10 万帧测试集上,IoU 只掉了 1%。大家觉得稳了,直接合入主干代码,推到实车上跑封闭测试场。
 极端长尾场景下的激活值异常,可能导致致命的“幽灵盲区”
极端长尾场景下的激活值异常,可能导致致命的“幽灵盲区”结果,在测试“大曲率弯道+前方有静止清障车”这个极端场景时,车辆竟然在距离清障车不到 5 米的地方才触发预制动(Pre-brake),最后是安全员一脚将刹车踏板踹到底,才避免了价值百万的测试车报废。
那天晚上整个团队复盘到凌晨四点。我们把出事那一帧的数据落盘,写脚本一层一层地比对 Tensor。最后发现了极其诡异的 Bug:
在 Transformer 的某一层 Cross-Attention 中,清障车边缘的几个体素产生了一个极大的负激活值。在 FP32 下,这个值被正常传递,模型判定前方为“占据”;而在 INT8 静态量化中,由于校准集(Calibration Dataset)里没有覆盖到这种极端的清障车长尾场景,截断阈值设得太小,导致这个关键的负激活值直接被“削平”成了 0。
在量化后的模型眼里,那辆巨大的清障车,直接凭空消失了。
从那以后,我在团队的 MLOps 平台上立下了一条铁律:禁止唯 mAP 论。我们硬生生花了一个月时间,开发了一套基于 KL 散度和余弦相似度的自动化白盒校验流水线。只有把底线守住,大模型上车才不是一句骗人的口号。
🛡️ 实战避坑:老兵的3条保命建议
对于正在做端到端大模型部署和底层性能优化的团队,老兵给出 3 条硬核“保命”建议:
- 1. “敏感度分析(Sensitivity Analysis)”是量化的绝对前提:在动手压缩之前,先做一套逐层的敏感度摸底。找出那些对精度极度敏感的层(通常是靠近输出的解码器层、或者包含 Softmax 的 Attention 模块),这些地方必须采用混合精度部署(Mixed Precision),该用 FP16 的地方一刀都不能切。
- 2. 校准集(Calibration Set)的质量决定生杀大权:做静态量化时,用来计算缩放因子(Scale Factor)的校准集,绝对不能随便拿 1000 张白天的正常行驶照片凑数。必须包含暴雨、逆光、极端遮挡、异形车等高熵长尾场景。
- 3. 把 WandB 和 CI/CD 刻进团队的 DNA:别再用 Excel 记各种实验的量化参数了。把 WandB 等工具深度集成到流水线里,每一次算子的改动,都必须自动生成与 Baseline 模型的轨迹偏移(Trajectory Deviation)对比曲线。
 建立基于白盒校验的自动化 MLOps 流水线,守住交付底线
建立基于白盒校验的自动化 MLOps 流水线,守住交付底线版权声明:本文为知猷君原创,未经授权严禁转载、摘编或用于商业用途。如需合作请联系后台。
🔗 找到老兵:
📍 微信公众号:搜索“知猷”
📍 小红书:知猷-新能源智库 (ID: ZhiYou_Auto)
📍 闲鱼:搜索用户“知猷新能源咨询”
关注知猷君,在浮躁的时代,我们只谈有逻辑的技术。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
