当前的纯端到端模型更像司机的“肌肉记忆”,处理新奇语义场景极易失灵。下一代智驾范式的真正底牌,是走向具身智能的 VLA 模型与快慢思考系统。“现在的端到端(E2E),其实只是在模仿老司机的‘肌肉记忆’,它根本没有‘脑子’。”
💥 开篇暴击:端到端只是前菜,具身智能才是主菜
搞智驾的兄弟们,咱们聊句扎心的。这两年行业里“端到端”(E2E)被炒得神乎其神,仿佛只要把传感器数据喂进去,车端直接吐出转向和油门指令,自动驾驶就大功告成了。
但你发现没有?现在的车,处理高频的、重复的物理工况(比如丝滑地变道、跟车加塞)确实越来越像老司机。可一旦遇到低频、强语义、强社会规则的长尾场景——比如路口交警打了个奇怪的手势,或者前方有个大坑旁边插了一块写着“此路不通,请绕行”的简易木牌,它就立刻变身“人工智障”。
原因很简单:目前的端到端模型,只有“直觉”,没有“逻辑”。它无法理解人类复杂的社会语言指令,更无法在从未见过的新奇场景中进行深度因果推理。今天,老兵知猷就带大家看透下一代智驾的终极范式——VLA(Vision-Language-Action)模型与快慢思考系统,拆解目前两大顶尖流派的暗战。
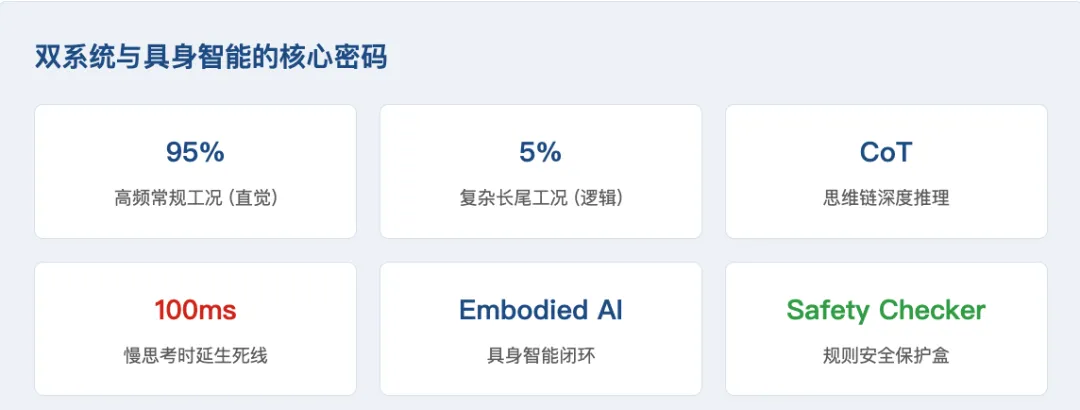
双系统与具身智能的核心密码
🧠 底层逻辑:走向具身智能的交汇点
具身智能(Embodied AI)的核心逻辑,是让 AI 从“缸中之脑”走向“有身体的物理实体”。在智驾领域,这意味着系统必须完成从视觉(V)到语言理解(L),再到物理动作执行(A)的完美闭环。VLA 本质上是在把单一的“看见”升级成“理解”,再把“理解”映射到车辆底盘的动作。
在这个通往终极 L4 的赛道上,目前行业内形成了两种极具代表性的“华山论剑”路线:
图 1:从模仿肌肉记忆到构建逻辑大脑的能力跃迁路线 1:“快慢思考”双系统架构(以某造车新势力为代表)
这套架构深受诺奖得主丹尼尔·卡尼曼《思考,快与慢》的启发,它完美映射了人类的认知架构:绝大多数时刻靠直觉驾驶,极少数危机时刻靠逻辑接管。
- 系统 1(快思考 - E2E 直觉模型):负责 95% 的日常驾驶。它像人类的本能反应,输入视觉,瞬间输出方向盘和刹车动作。它速度极快,但遇到长尾场景容易懵逼。
- 系统 2(慢思考 - VLM 视觉语言模型):负责 5% 的复杂逻辑。当系统 1 拿不准、信心度下降时,系统 2 启动。它利用大模型的思维链(Chain of Thought, CoT)进行推理:“前面有个穿反光背心的人在挥手,木牌上写着修路,结合常识,我应该缓行并寻找变道机会。”
图 2:双系统协同让智驾同时具备老司机的本能与逻辑大脑路线 2:WA 世界动作模型路线(以某通信大厂为代表)
这种路线主张“大道至简”,他们敏锐地抓住了语言模型的致命弱点:物理精度的丧失。 将视觉信息转成文字(Language)再转回物理动作(Action),中间会产生巨大的精度损耗。比如,距离前车真实物理距离是 3.5 米,经过语言层翻译,可能只留下一句“距离很近”的抽象描述。这种模糊的语言映射,落到转向角和刹车卡钳上,就是一场灾难。
因此,WA(World Action)路线直接跳过语言环节。它在统一的特征潜空间(Latent Space)里,让模型直接建立从“世界演化预判”到“物理动作执行”的映射。它不教 AI “聊天”,而是追求极致的三维物理精度与一致性。
图 3:WA 路线直接在潜空间打通视觉与物理动作,规避“聊天模型”的伪精度路线对标:E2E vs VLA双系统 vs WA世界动作 | | | |
|---|
| 推理逻辑 | | | |
| 语义理解能力 | | 极强,能读懂人类文字/手势 | |
| 物理执行精度 | | | 极高,跳过翻译直接输出动作 |
| 系统推理时延 | | | |
| 安全兜底策略 | | 必须加 Rule-based Safety Checker | |
📓 知猷回忆录:小路口挥杆的保安,与被逼疯的 if-else
这段路线博弈,让我想起了几年前在某头部 L4 研发团队带队搞 Robotaxi 复杂交互时的“至暗时刻”。
当时我们在测试场地遇到一个棘手场景:测试车在通过一个小路口时,前方施工,遇到一位物业保安在路中间挥舞一根蓝白条纹的交通标杆,示意车辆逆行绕过去。 我们的传统感知模型和早期的直觉控制模型能非常精准地框出“Person”(人)和“Pole”(杆子),但它完全理解不了这个挥舞动作背后的社会学交互含义。
规控团队被逼得写了几百行 `if-else`:如果杆子角度是30度,如果人的相对位置在车道左侧边缘…… 结果呢?保安挥得快一点,系统就疯狂闪烁警报刹停;保安挥得慢一点,系统就想硬闯过去。
图 4:VLM 的引入让机器具备了社会学的常识推理能力后来,我们尝试把一个脱敏后的视觉语言大模型引入到决策闭环中作为“慢系统”兜底。那天,当模型在后台静默运行,成功推理出“前方有人引导,需遵从手势变道”并生成了一条完美的绕行轨迹时,我彻底醒悟了: 真正的智能,不是靠穷尽 C++ 规则去打补丁,而是靠理解物理世界与人类社会的交互逻辑。语言模型给智驾带来的不是让车陪你聊天,而是赋予它处理复杂、未知关系的“常识底座”。
🛡️ 实战避坑:通往 L4 架构的 3 条生死红线
双系统和 VLA 听起来是降维打击,但工程落地的坑足以埋掉一家二线厂商。对于正在调研演进路线的架构团队,老兵提 3 点血泪避坑指南:
- 第一:慢思考不能真的“慢”(死守 100ms 约束)如果你的 VLM 在车端算力下推理一次要花 500ms 甚至 1秒,那这套系统只能用于静态路线规划,在瞬息万变的高速路况上等于自杀。必须通过模型量化、剪枝甚至底层算子级 NPU 加速,把端侧推理时延硬生生压到 100ms 以内,大模型才有上车的现实操作意义。
- 第二:严防“语言损耗”(Language Loss)如果你坚定走 VLA 路线,一定要死磕视觉 Token 与动作 Token 之间的物理对齐。千万不要直接套用云端聊天大模型(LLM)通用的 Tokenizer!文字描述天然是抽象且有颗粒度的,如果损失了空间精度,你的车在微调方向盘时会开得像个“多动症”患者。
- 第三:安全围栏是最后的保命锁大语言模型无论吹得多么有逻辑,它骨子里依然存在不可解释的“AI 幻觉”。不要把命全交给 AI 的推理。在执行底盘动作之前,底层的规则安全保护盒(Rule-based Safety Checker)永远、永远不能拿掉。它是防止 AI 突然发疯的最后一道物理和逻辑锁。
图 5:大模型落地的三大“夺命红线”:时延、对齐损失与安全兜底
🎁 变现转化区:获取双系统核心架构底稿
从 E2E 到 VLA 具身智能的超车密卷👉 获取硬核全栈资料:如果你是架构师或者需要给高层讲清楚具身智能的路标,直接去我的闲鱼(搜索用户:知猷新能源咨询)拍下。一杯咖啡钱,省下你翻 50 篇论文、熬夜对齐系统架构的时间!👉 免费白嫖福利:在微信公众号后台回复关键词【具身】,小助手免费发你“智驾快慢系统架构流转图”高清版,就当交个朋友。
👇 总结互动话题智驾技术从“规则驱动”演进到“直觉驱动”,如今又向“直觉+逻辑”攀登。如果是你做智驾底层架构 Tech Lead,面对极高难度的城市复杂交互,你会优先押注走“快慢双系统”、走去语言化的“WA世界动作”,还是坚持头铁深挖纯“端到端(E2E)”?欢迎在评论区留下你的硬核直觉,老兵会在评论区逐一探讨切磋!
📮 版权声明:本文版权归【知猷君】所有,未经授权禁止爬取、复制和洗稿转载。如需白名单授权,请联系作者本人。
📱 🎯 知猷·新能源智库 | 你的随身技术军师👇 获取更多硬核资源 & 搞钱路子 👇
- 微信公众号:搜索 “知猷”,关注后点击“发消息”,长期围观老兵的造车手记。
- 小红书:
- 闲鱼:独家脱敏PPT/行业报告/架构脑图(搜索用户“知猷新能源咨询”)
💡 打赏随意:如果这篇文章帮你省了加班时间,欢迎打赏,金额随意,交个朋友!
关注知猷君,在浮躁的时代,我们只谈有逻辑的硬核技术。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
