从“看到什么就做什么”,到“推演未来再决策”——自动驾驶的世界模型终于有了统一的离散化方案。
导读: 自动驾驶正在从“反应式驾驶”走向“推演式驾驶”。论文《Discrete-WAM: Unified Discrete Vision-Action Token Editing for World-Policy Learning》提出了一种新的世界-策略统一建模框架:把视觉观测、未来状态、高层决策和底层动作全部映射到同一个离散 Token 空间中,让模型不仅能预测未来世界,还能在预测中学习如何决策。这可能是自动驾驶世界模型从“看懂场景”迈向“预演未来”的重要一步。
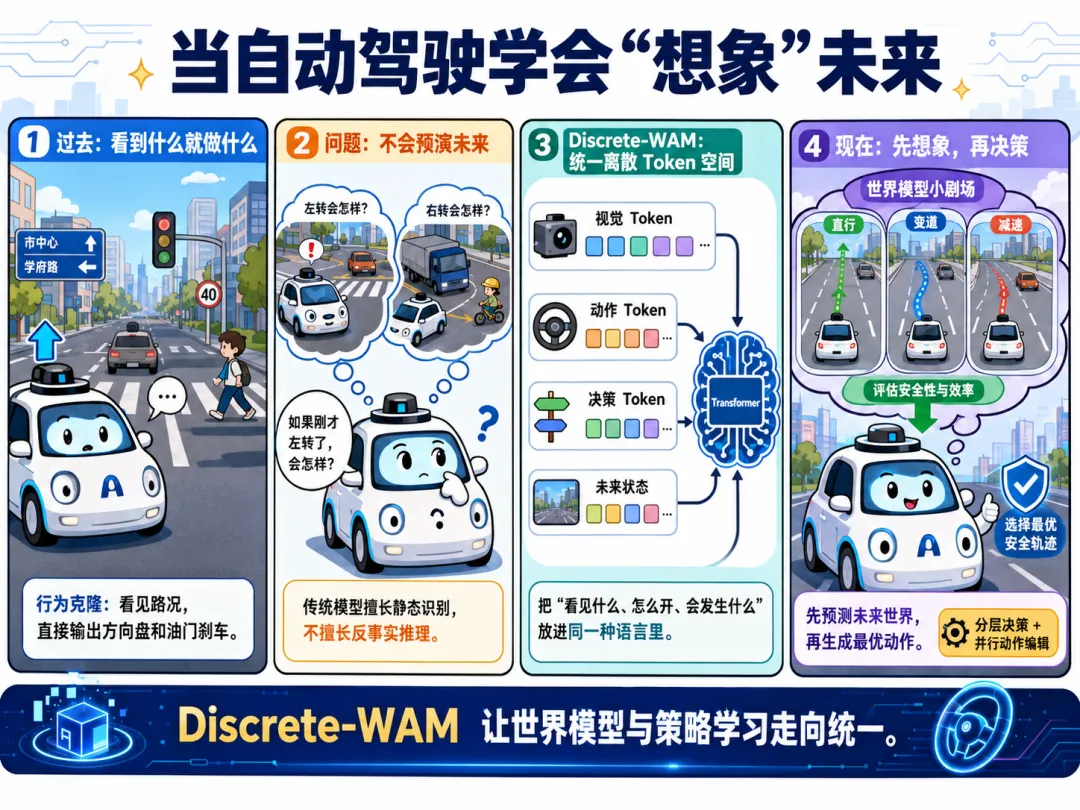
01 自动驾驶的“想象力”缺失
当前主流的端到端自动驾驶系统,本质上是一种行为克隆。
也就是说,模型看到当前路况,直接输出方向盘角度、油门和刹车。
这就像一个人开车从不看路牌、不预测前车意图,也不思考“如果我现在变道会怎样”,只是凭肌肉记忆在开。
这种方法有两个致命缺陷。
第一,它只学习表象关联,不学习因果动力学。
也就是说,它不知道“我的动作会如何改变世界”。
第二,它很难应对反事实场景。
也就是说,它无法回答:“如果刚才左转了会怎样?”
近年来,世界模型试图弥补这一空白。
它的目标不是简单地识别当前画面,而是预测未来:
如果采取某个动作,世界会变成什么样?
传统自动驾驶模型更像是在“看图做题”,而世界模型想做的是“在脑海里先开一遍”。
但问题在于,过去的世界模型和策略模型往往是分开训练的。
一个负责预测未来画面。
一个负责输出驾驶动作。
你练你的预测,我学我的开车,两者之间并没有真正打通。
这正是 Discrete-WAM 想要解决的核心问题。
02 什么是 Discrete-WAM?
Discrete-WAM 的核心想法,可以用一句话概括:
把自动驾驶中的“看见什么”“想去哪里”“怎么开”“未来会怎样”,全部放进同一个离散 Token 空间里。
这听起来有点抽象。
换个说法:
过去,视觉、动作和决策像是三种不同语言。摄像头图像是一种语言,轨迹控制是一种语言,高层规划又是另一种语言。
它们之间要不断翻译。
而 Discrete-WAM 做的事情,是给它们建立一套统一词表。
图像是 Token。
动作是 Token。
决策也是 Token。
未来状态还是 Token。
这样一来,自动驾驶就可以被看作一个统一的序列建模问题。
模型不再只是“看到画面后输出动作”,而是在同一个序列空间中同时学习:
现在是什么状态?
未来可能怎么变?
我应该做什么动作?
这个动作会带来什么后果?
真正关键的变化不是“模型更会识别”,而是它开始把感知、预测和决策放在同一个世界里思考。
03 统一离散 Token 空间
Discrete-WAM 的第一大贡献,是统一离散化。
具体来说,它把三类信息都转成 Token。
第一类是视觉 Token。
模型用 VQ-VAE 把摄像头图像编码成离散视觉 Token。
这相当于把连续的画面压缩成一组可建模的视觉词汇。
第二类是动作 Token。
自动驾驶中的动作不是简单的“左转”“右转”,而是连续的未来轨迹,例如加速度序列。
Discrete-WAM 将这些连续动作离散化为一个网格化的加速度词表。
关键创新在于,它不是简单地做硬量化。
硬量化的问题是:一个连续值一旦被强行归到某个格子里,就会损失精度。
Discrete-WAM 采用的是软标签插值。
每个连续加速度值,不是只对应一个词条,而是由周围 4 个最近邻词条加权表示。
这样训练时可以学习软标签分布,推理时再反解回连续值。
好处是:
既保留了离散 Token 的建模优势,又减少了硬量化带来的精度损失。
第三类是高层决策 Token。
比如换道意图、目标车道、速度趋势。
这些决策 Token 就像规划过程中的“骨架”。
有了它,模型不是盲目生成一串底层动作,而是先知道大方向,再生成具体控制。
离散 Token 的意义,不只是压缩数据,而是给视觉、动作和决策提供了一套共同语言。
04 三大训练模式:从预测到决策
有了统一的离散空间,Discrete-WAM 进一步设计了三种训练模式。
它不是一下子让模型学会所有事情,而是从“预测世界”逐步走向“生成策略”。
第一种模式叫 World Modeling。
输入是场景上下文和未来动作 Token。
输出是未来视觉 Token。
它学习的是:
给定某个动作,世界会怎样变化?
比如,如果车辆继续直行,前方车辆会不会靠近?行人会不会进入车道?路口场景会如何演化?
这是最典型的世界模型能力。
第二种模式叫 World-Policy Modeling。
输入只有场景上下文。
输出是未来动作 Token 和未来视觉 Token。
这一步开始把预测和决策绑在一起。
模型不仅要预测未来世界,还要预测自己可能采取的动作。
也就是说,它开始学习:
在这个场景下,我会怎么开?这样开之后,世界会怎样?
第三种模式叫 Policy Modeling。
输入仍然是场景上下文。
输出则分成两步:
先预测高层决策 Token,再生成底层动作 Token。
这一步把高层规划和底层控制解耦。
例如,模型可以先决定“向左变道”,再生成具体的加速度和轨迹序列。
世界模型的预测不是终点,而是为策略生成服务的。
这是 Discrete-WAM 最重要的思想之一。
当模型学会了:
如果这样开,世界会变成那样。
它就可以进一步反推:
如果我希望世界变成那样,我应该这样开。
05 推理阶段:先定方向,再改动作
在推理阶段,Discrete-WAM 采用了两层策略。
第一层是决策预测。
模型先预测一个高层决策 Token。
比如:
向左变道。
保持车道。
减速避让。
准备右转。
这个决策 Token 相当于整个规划过程的骨架。
它先确定大方向,避免模型在生成动作时前后矛盾。
第二层是并行动作 Token 编辑。
在高层决策的约束下,模型使用离散扩散模型,并行编辑未来所有动作 Token。
这和传统自回归生成不一样。
自回归方法是一帧一帧往后生成,前一步错了,后面可能跟着错。
而并行动作编辑更像是先画出一条粗略轨迹,再不断修改不确定的部分。
论文还引入了置信度调度机制。
模型先快速生成一条初始轨迹。
然后重点修正那些置信度较低的位置。
这带来了几个好处。
第一,高层决策保证全局一致性。
它可以避免出现“前 3 秒准备左转,后 3 秒又突然右转”这样的矛盾行为。
第二,动作层支持并行生成。
相比逐帧自回归,推理效率更高。
第三,它天然支持反事实评估。
例如,可以直接问模型:
如果我刚才右转了,世界会怎样?
这对于自动驾驶安全验证非常重要。
06 实验亮点:不只是会开车,还会预演
Discrete-WAM 在 nuScenes、OpenScene 等大规模自动驾驶数据集上进行了评估。
论文展示了几个值得关注的结果。
首先是规划性能领先。
在多种规划指标上,Discrete-WAM 超越了现有端到端自动驾驶方法。
这说明统一世界-策略建模并不只是概念好看,而是能实际提升规划效果。
其次是可控未来生成。
模型能够根据指定的高层决策,生成对应的未来视觉场景。
比如给定“变道”意图,模型可以生成与之匹配的未来道路画面。
第三是反事实推理。
给定不同动作序列,模型可以生成不同的未来世界状态。
这意味着它不只是预测“最可能发生什么”,还可以比较“如果我这样做”和“如果我那样做”的差异。
第四是意外度分析。
论文中还展示了一个很有意思的能力:
利用模型的“意外度”来检测分布外场景,也就是 OOD detection。
在自动驾驶这种安全关键场景中,这一点非常重要。
因为真正危险的,往往不是模型见过很多次的普通场景,而是那些它从未充分见过的异常情况。
一个好的自动驾驶世界模型,不仅要知道“未来会怎样”,还要知道“我是不是正在遇到一个不熟悉的未来”。
07 方法论启示:物理世界 AI 的统一范式
Discrete-WAM 的意义,不只在自动驾驶。
它更像是为物理世界 AI 提供了一套通用设计范式:
离散表示对齐。
统一世界-策略训练。
分层 Token 编辑。
这三件事合在一起,指向的是一种新的物理世界推理方式。
过去,感知、预测、规划、控制往往被拆成多个模块。
每个模块都有自己的表示空间。
视觉模型看图。
轨迹模型预测。
规划器做决策。
控制器执行动作。
问题在于,只要表示空间不统一,中间就一定会有信息损失和语义鸿沟。
而 Discrete-WAM 的核心洞察是:
如果视觉、动作和未来状态都能被表示成 Token,它们就可以在同一个 Transformer 空间中被联合建模。
这对自动驾驶之外的机器人、具身智能、工业控制等领域都有启发。
对于优化领域的研究者来说,这项工作还有一个值得关注的地方:
它把预测性世界模型和策略优化,通过共享表示与联合训练进行了对齐。
本质上,这是一种端到端的隐式模型基优化。
你不再需要一个显式的“规划器”或“优化器”。
模型在生成 Token 的过程中,其实已经完成了对未来轨迹的隐式搜索。
当“预测未来”和“选择动作”被统一到同一个生成过程里,规划本身就变成了一种序列生成。
写在最后
自动驾驶正在从“反应式驾驶”迈向“推演式驾驶”。
过去的模型更像是看到什么,就立刻做什么。
而 Discrete-WAM 代表的方向是:
先在内部世界中预演未来,再选择行动。
当然,从论文到真实道路落地,还有很长的距离。
计算效率、实时性、安全验证、极端场景泛化,仍然都是必须解决的问题。
但方向已经越来越清晰:
未来的物理世界 AI,不能只会识别现在。
它必须能想象未来。
从这个意义上说,Discrete-WAM 的价值不只是提出了一种自动驾驶方法,而是提醒我们:
真正可靠的智能体,应该先学会在脑海中开车。
论文信息
标题:Discrete-WAM: Unified Discrete Vision-Action Token Editing for World-Policy Learning
作者:Ziyang Yao, Haochen Liu, Yuncheng Jiang, et al.
发布平台:arXiv
发布时间:2026
论文编号:arXiv:2606.05645
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
