「三个技术主线」
2026年的进展比想象中要快。
本文从三个维度梳理2026年以来具有代表性的开源工作:认知与规划的融合、高效端到端架构的探索,以及世界模型的最新进展。
所有收录工作均经过 GitHub 仓库真实性核查,确保代码可用。
说明:本文主要以 GitHub 上已公开的项目为线索进行整理,筛选标准以代码可获取性和项目活跃度为主(具有一定Star数量),难免存在遗漏。未被提及的相关工作同样具有参考价值,读者可结合自身研究方向进一步查阅和补充。
随着大语言模型在常识推理上的持续进展,如何将语言模型的认知能力引入自动驾驶,以应对长尾场景,成为了2026年的重要研究方向。
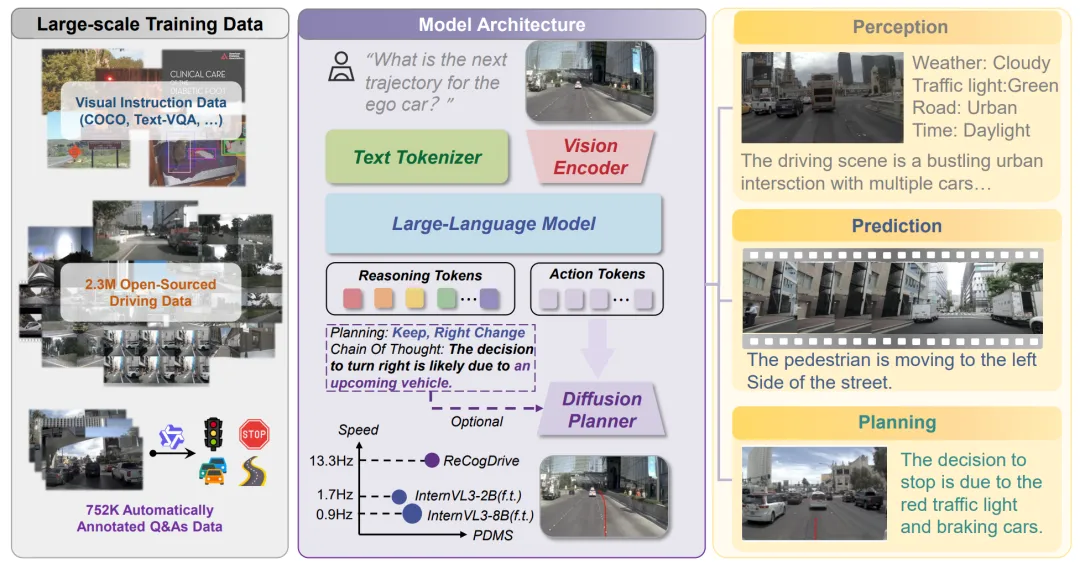
图1 | ReCogDrive 框架概览。左侧为大规模训练数据构建流程,中间为模型架构(VLM + 扩散规划器),右侧为感知与规划可视化示例。©【深蓝 AI】编译
论文标题:ReCogDrive: A Reinforced Cognitive Framework for End-to-End Autonomous Driving
发表机构:华中科技大学、小米汽车
GitHub:xiaomi-research/recogdrive(545+ Stars)
成果亮点:在端到端自动驾驶中,直接让视觉语言模型(VLM)输出物理动作往往会导致格式错误或动作不可行。由华中科技大学和小米汽车联合提出的 ReCogDrive 针对这一问题,提出了一种将驾驶理解与规划统一起来的强化认知框架。
该工作的核心思路是将VLM的认知能力与扩散规划器结合。首先,通过"生成-细化-质量控制"三阶段的层次化数据流水线,将人类驾驶认知注入VLM;随后,通过将VLM学习到的驾驶先验注入扩散规划器,高效生成连续且稳定的轨迹。为了进一步提升安全性,ReCogDrive还引入了扩散组相对策略优化(DiffGRPO)阶段,对规划器进行强化学习微调。在NAVSIM和Bench2Drive等基准测试上,ReCogDrive均取得了当前SOTA成绩。
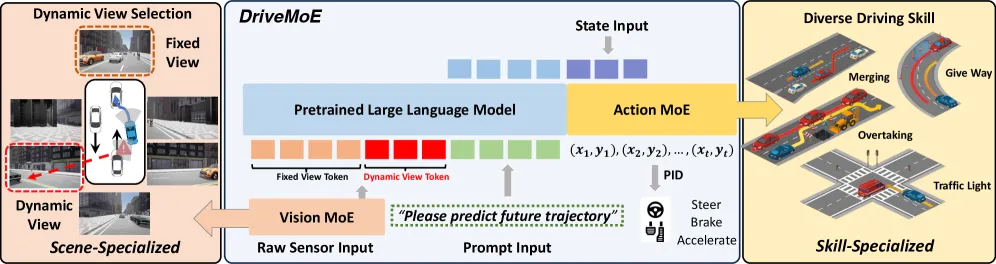
图2 | DriveMoE 整体架构。左侧为场景特化的视觉MoE(根据驾驶场景动态选择摄像头),右侧为技能特化的动作MoE(根据驾驶行为激活不同专家)。©【深蓝 AI】编译
论文标题:DriveMoE: Mixture-of-Experts for Vision-Language-Action Model in End-to-End Autonomous Driving
发表机构:上海交通大学 Thinklab
GitHub:Thinklab-SJTU/DriveMoE(211+ Stars)
成果亮点:自动驾驶需要处理来自多个摄像头的视频数据,同时应对各种复杂的驾驶场景。上海交通大学Thinklab团队提出的 DriveMoE 将混合专家(MoE)架构引入了端到端驾驶,以具身AI领域的 π₀ VLA 模型为基础底座。
DriveMoE包含两个核心模块:其一是"场景特化的视觉MoE",通过训练一个路由器,根据当前驾驶场景动态选择最相关的摄像头视角,避免对所有视觉信息进行冗余处理;其二是"技能特化的动作MoE",通过另一个路由器为不同的驾驶行为激活专门的专家模块,通过显式的行为专业化,使模型能够处理多样化场景,缓解现有模型中常见的"模式平均"问题。在Bench2Drive闭环评测中,DriveMoE取得了SOTA性能。
在追求性能的同时,如何让端到端架构更加轻量、高效,也是研究者持续关注的方向。
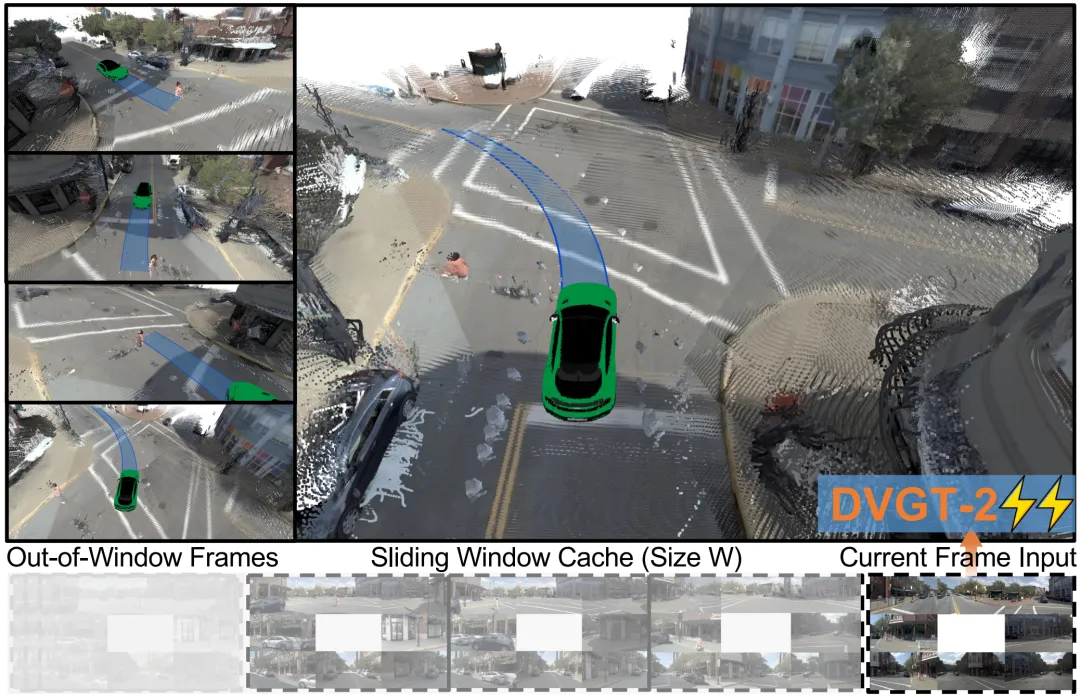
3. DVGT-2:视觉-几何-动作(VGA)在线联合范式图3 | DVGT-2 方法示意。通过流式架构和历史特征缓存,实现了高效的在线联合重建与规划,支持不同相机配置下的直接部署。©【深蓝 AI】编译
论文标题:DVGT-2: Vision-Geometry-Action Model for Autonomous Driving at Scale
发表机构:清华大学等
GitHub:wzzheng/DVGT(305+ Stars)
成果亮点:传统的端到端模型大多基于稀疏感知,或转向以语言描述为辅助任务的VLA模型。DVGT-2 则提出了一种替代的视觉-几何-动作(VGA)范式,认为密集的3D几何结构是自动驾驶决策的重要依据。
由于现有的几何重建方法(如 DVGT-1)依赖于计算成本较高的多帧批处理,难以直接应用于在线规划。DVGT-2 引入了一种流式驾驶视觉几何Transformer,能够以在线方式处理输入,并联合输出当前帧的密集几何结构和轨迹规划。它采用时间因果注意力并缓存历史特征,以支持即时推理;同时通过滑动窗口流式策略,避免了重复计算。值得注意的是,同一个训练好的 DVGT-2 模型,无需微调即可直接应用于具有不同相机配置的闭环 NAVSIM 和开环 nuScenes 基准测试,在几何重建与规划性能上均取得了有竞争力的结果。
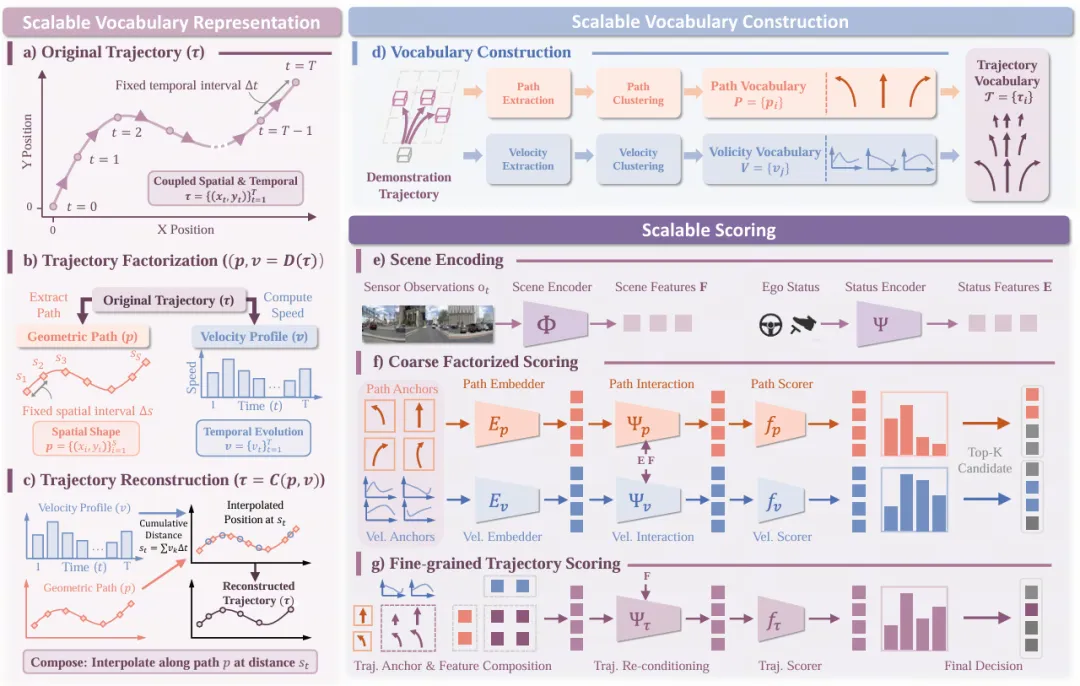
4. SparseDriveV2:基于评分的端到端规划图4 | SparseDriveV2 整体框架。通过将轨迹分解为路径和速度的因子化结构,构建超密集词表,并采用分层评分策略,以较低的计算代价实现具有竞争力的规划性能。©【深蓝 AI】编译
论文标题:SparseDriveV2: Scoring is All You Need for End-to-End Autonomous Driving
发表机构:清华大学等
GitHub:swc-17/SparseDriveV2(179+ Stars)
成果亮点:端到端规划通常面临一个权衡:静态词表(Static Vocabulary)离散化粒度粗,而动态生成(Dynamic Generation)虽然精度高,但计算量大。SparseDriveV2 对此提出了一个具体的研究问题:当静态词表足够密集时,是否可以在不依赖动态生成的前提下达到相当的性能?
该工作首先通过对代表性评分方法 Hydra-MDP 进行系统性的缩放研究,发现性能随着轨迹锚点的增密而持续提升,且在计算约束到来之前并未出现饱和。受此启发,SparseDriveV2 提出了两项互补创新:一是将轨迹分解为几何路径和速度配置的因子化词表表示,实现对动作空间的组合覆盖;二是先对路径和速度进行粗粒度因子化评分,再对少量组合轨迹进行细粒度评分的可扩展评分策略。最终,仅使用轻量级 ResNet-34 骨干网络,SparseDriveV2 在 NAVSIM 上取得了 92.0 PDMS 和 90.1 EPDMS,在 Bench2Drive 上取得了 89.15 驾驶分和 70.00 成功率。
世界模型通过预测未来的环境变化,为自动驾驶系统提供前瞻性信息。2026年,世界模型在自动驾驶领域的应用更加务实,针对若干实际问题提出了具体的解决方案。
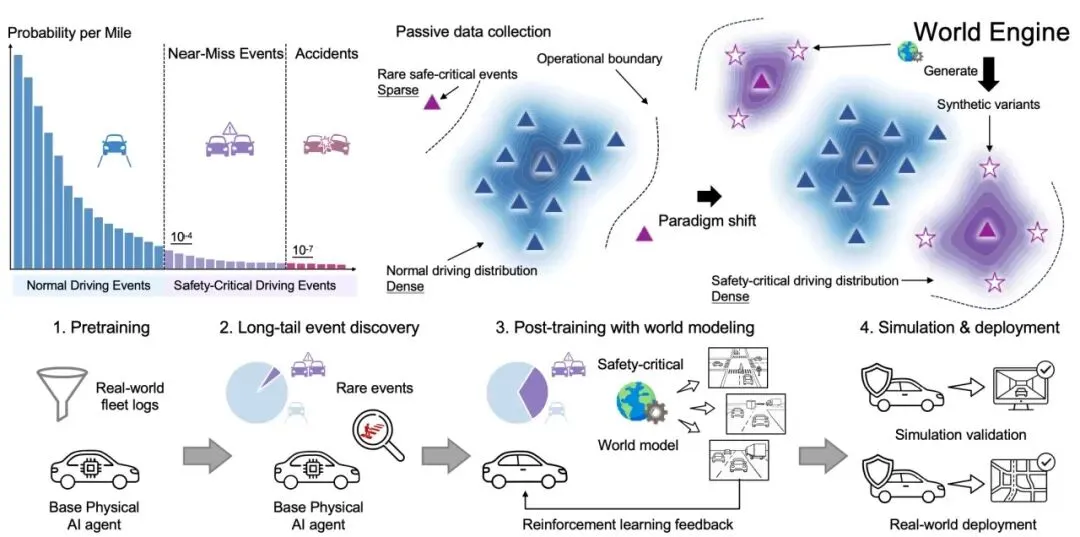
5. WorldEngine:面向物理AI的后训练框架图5 | WorldEngine 系统概览。从真实驾驶日志出发,发现长尾事件,重建为可交互的神经环境,生成多样化的对抗场景,最终通过强化学习后训练提升模型安全性。©【深蓝 AI】编译
论文标题:Towards the Era of Post-Training for Physical AI
发表机构:香港大学 OpenDriveLab、华为、NVIDIA Research 等
GitHub:OpenDriveLab/WorldEngine(338+ Stars)
成果亮点:自动驾驶行业长期面临一个数据分布问题:真正导致事故的危险边缘场景在真实数据中极其罕见,单纯增加数据量难以有效覆盖这些场景。WorldEngine 针对这一问题,提出了一套专为物理AI设计的"后训练"闭环框架。
该框架共分四个阶段:首先定位模型在真实世界中的失败场景;其次利用3D高斯溅射(3DGS)技术将这些场景重建为高保真神经环境;然后在这个可编辑的环境中生成更困难、更多样的对抗性交通变化;最后通过强化学习对模型进行后训练。在基于超过8万小时真实驾驶日志的工业级闭环仿真中,WorldEngine 使碰撞率下降了 45.5%,并在上海200公里的真实道路测试中实现了零接管。
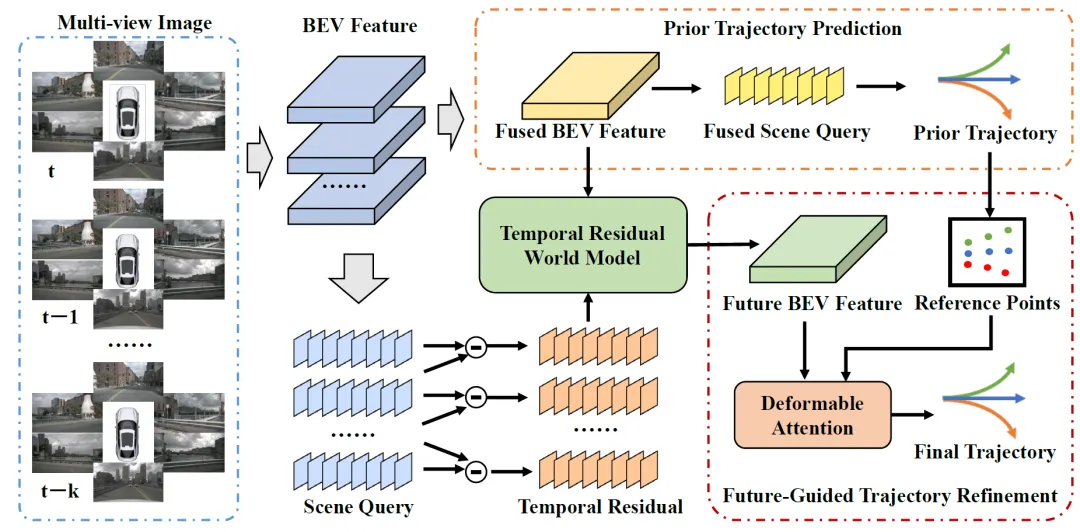
图6 | ResWorld 框架。通过计算相邻帧的BEV特征残差,提取动态物体信息,预测未来场景,并通过FGTR模块进行轨迹细化。©【深蓝 AI】编译
论文标题:ResWorld: Temporal Residual World Model for End-to-End Autonomous Driving
发表机构:北京航空航天大学、中关村实验室
GitHub:mengtan00/ResWorld(52+ Stars)
成果亮点:传统的世界模型往往对整个场景(包括地面、建筑等静态背景)进行未来预测,这不仅带来额外的计算开销,还可能引入不必要的噪声。ResWorld 的核心思路是:只对"变化"进行建模。
它通过计算不同时间戳场景表示的"时序残差(Temporal Residuals)",提取动态物体的信息,而无需依赖传统的检测和跟踪模块。ResWorld 以这些残差为输入,预测动态物体未来的空间分布,再结合当前的BEV(鸟瞰图)特征,得到未来场景表示。此外,它还提出了未来引导的轨迹细化(FGTR)模块,利用预测的未来路况来修正先验轨迹,有效缓解了世界模型的退化问题。在 nuScenes 和 NAVSIM 数据集上,ResWorld 均取得了当前最优的规划性能。
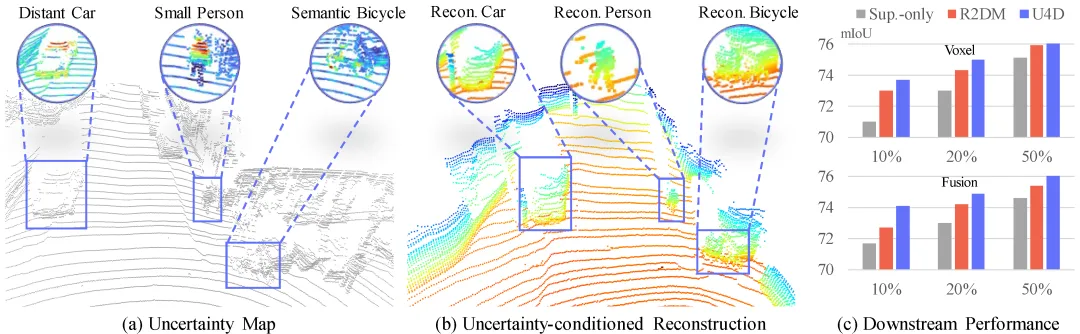
7. U4D:不确定性感知的4D LiDAR世界模型(CVPR 2026 Highlight)图7 | U4D 方法示意。左侧为不同类别的不确定性可视化(小行人、自行车等高不确定性目标),右侧为U4D与基线方法在体素级别的定量对比。©【深蓝 AI】编译
论文标题:U4D: Uncertainty-Aware 4D World Modeling from LiDAR Sequences
发表机构:南京理工大学、南洋理工大学等
GitHub:worldbench/U4D(24+ Stars)
成果亮点:对于构建自动驾驶仿真环境,4D LiDAR序列(即带时间维度的3D点云)的生成具有重要意义。现有的生成框架通常对所有空间区域采用相同的处理方式,导致在语义复杂的区域(如行人密集区、路口)出现几何伪影,影响真实感和时间一致性。
U4D 提出了一种不确定性感知的4D LiDAR世界建模框架,核心设计是"由难到易"的生成策略。它首先利用预训练的分割模型估计空间不确定性地图,定位语义上具有挑战性的高熵区域;然后优先重建这些高不确定性区域以保证几何保真度;最后在学习到的结构先验下补全剩余区域。为了保证时间连贯性,U4D 还引入了时空混合(MoST)块,在扩散过程中自适应地融合空间和时间表示。实验表明,U4D 在几何保真度和时间一致性方面均优于现有基线方法。
ReCogDrive的认知-规划闭环、DriveMoE的多专家分工、SparseDriveV2的因子化规划、DVGT-2的在线几何重建——它们在架构思路上各有侧重,但共性很明确:
不再依赖单一端到端黑箱,而是尝试把可解释的认知、可验证的几何、可独立优化的模块重新引入系统。
世界模型的方向更务实了。
WorldEngine用3DGS重建真实失败场景做强化后训练,ResWorld只预测动态变化避免冗余,U4D针对LiDAR生成中的几何伪影做针对性优化。这些工作不再兜售“端到端万能”,而是老老实实解决具体问题。
以上代码已全部开源,链接附在文末,欢迎收藏转发。
参考资料:
[1] Li, Y., et al. ReCogDrive: A Reinforced Cognitive Framework for End-to-End Autonomous Driving. arXiv:2506.08052. [[GitHub]](https://github.com/xiaomi-research/recogdrive )
[2] Yang, Z., et al. DriveMoE: Mixture-of-Experts for Vision-Language-Action Model in End-to-End Autonomous Driving. CVPR 2026. arXiv:2505.16278. [[GitHub]](https://github.com/Thinklab-SJTU/DriveMoE )
[3] Sun, W., et al. SparseDriveV2: Scoring is All You Need for End-to-End Autonomous Driving. arXiv:2603.29163. [[GitHub]](https://github.com/swc-17/SparseDriveV2 )
[4] Zuo, S., et al. DVGT-2: Vision-Geometry-Action Model for Autonomous Driving at Scale. arXiv:2604.00813. [[GitHub]](https://github.com/wzzheng/DVGT )
[5] OpenDriveLab. Towards the Era of Post-Training for Physical AI (WorldEngine). 2026. [[GitHub]](https://github.com/OpenDriveLab/WorldEngine )
[6] Zhang, J., et al. ResWorld: Temporal Residual World Model for End-to-End Autonomous Driving. ICLR 2026. arXiv:2602.10884. [[GitHub]](https://github.com/mengtan00/ResWorld )
[7] Xu, X., et al. U4D: Uncertainty-Aware 4D World Modeling from LiDAR Sequences. CVPR 2026 Highlight. arXiv:2512.02982. [[GitHub]](https://github.com/worldbench/U4D )
前时间账号迁移,很多老粉表示咋刷不到我们文章了,的确全靠运气。既有缘相遇此文,不妨把我们星标收藏,慢慢聊车、无人机、机器人、聊技术。