辞旧迎新,知识续航!🎆龙哥读论文陪你跨元旦,知识星球会员优惠券限时放送!
🐉 龙哥读论文知识星球:让你看论文像刷视频一样简单!元旦星球优惠券限时放送,每次发券少10元,现在是最优选!元旦假期专属,有效期截止26年1月16日,扫码立减,解锁一整年的论文干货+技术资源!手慢则无,冲就对了!

龙哥推荐理由:
这篇论文直击了自动驾驶仿真领域最头疼的两个“老大难”问题:新视角渲染模糊和车辆编辑光影不自然。SymDrive用一个统一的扩散模型框架,巧妙地通过“对称视图”和“自回归”策略,不仅把画面修得更清晰,还能让插入的车辆光影与背景无缝融合,而且无需额外训练!这种“一鱼两吃”的高效设计,对于需要大量生成逼真、可控驾驶场景的自动驾驶研发来说,简直是福音。😏
原论文信息如下:
论文标题:
SymDrive: Realistic and Controllable Driving Simulator via Symmetric Auto-regressive Online Restoration
发表日期:
2025年12月
作者:
Zhiyuan Liu, Daocheng Fu, Pinlong Cai, Lening Wang, Ying Liu, Yilong Ren, Botian Shi, Jianqiang Wang
发表单位:
未明确标注
原文链接:
https://arxiv.org/pdf/2512.21618v1.pdf
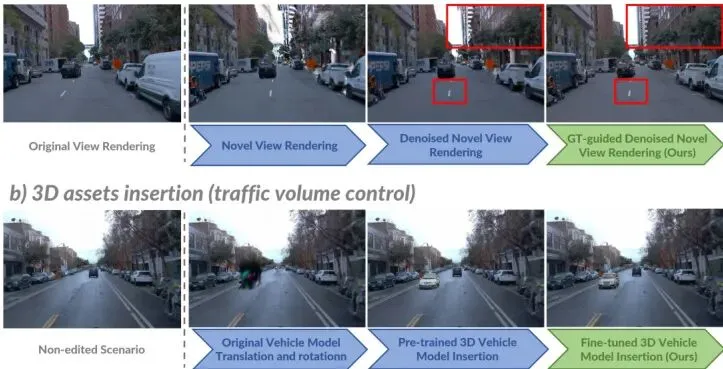
想象一下,你正在训练一个自动驾驶“老司机”。为了让它应对各种突发状况——比如突然窜出的行人、违规变道的车辆——你需要海量的、包含各种“奇葩”场景的驾驶数据。但现实世界的数据往往只覆盖常见情况,那些危险的“长尾”边缘案例可遇不可求。这时候,高保真、可控制的3D驾驶仿真器就成了救命稻草。然而,现有的仿真技术就像一部有瑕疵的特效大片:要么画面精美但场景固定死板(难以编辑交通),要么可以随意摆放车辆但光影假得像贴图。图1:现有视觉仿真方法面临的挑战。(a) 新视角合成质量差,远处物体模糊。(b) 车辆编辑(移动或插入)导致光影不自然、出现重影或接缝。就在大家为此头疼时,一篇名为《SymDrive》的论文号称用一个统一的模型,就能同时搞定“拍得真”和“随便改”这两大难题。它到底是怎么做到的?背后又藏着哪些精妙的设计?今天,龙哥就带你扒一扒这篇让科技圈兴奋的论文。SymDrive:如何用统一模型搞定自动驾驶仿真两大难题?
在深入细节前,我们先看看SymDrive要解决的这两个“老大难”问题到底有多棘手。难题一:新视角渲染模糊。自动驾驶仿真需要从任意角度观察场景。主流技术3D高斯泼溅(3D Gaussian Splatting, 3DGS)能实时渲染,但在摄像头大幅横向移动(比如看旁边车道)时,渲染质量会急剧下降,物体变得模糊甚至畸形。这是因为原始数据缺失了那些角度的细节。难题二:车辆编辑穿帮。为了创造新场景,我们经常需要移动或插入车辆。但直接操作3D模型会导致光影、阴影与背景严重不符,像是P图没P好,一眼假。要么就是车辆本身几何不完整,出现“鬼影”。以往的方案往往是“单打一”:用扩散模型(Diffusion Model)来修图(提升渲染质量),或者用专门的编辑工具来P车。SymDrive的核心思路非常巧妙:我能不能训练一个超级修图师(扩散模型),它既擅长把模糊的新视角照片修清晰,又擅长把插入的车辆P得毫无违和感?它做到了。而且,这个“超级修图师”学会这两项技能的秘诀,源于一套名为“对称自回归在线修复”的训练和推理范式。核心揭秘:对称自回归在线修复如何工作?
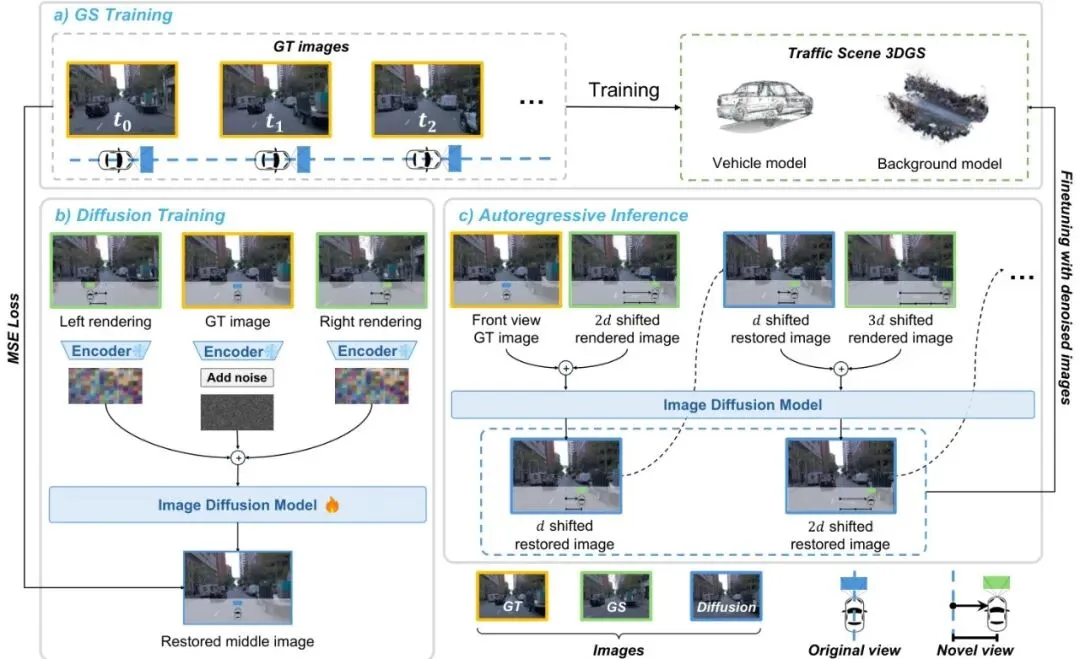
这个名字听起来有点唬人,我们拆开来看:“对称”指的是数据准备方式,“自回归”指的是推理生成策略,“在线修复”指的是它边生成边优化3D模型的能力。图2:新视角修复流程概览。a) 用真实图像分别训练前景车辆和背景场景的3DGS模型。b) 以真实视角为中心,生成对称的GS渲染图作为训练数据。c) 通过自回归迭代过程逐步生成去噪的新视角图像,并用这些图像微调GS模型。要训练一个修图模型,你得先有“模糊原图”和“清晰目标图”的配对数据。以前的方法要么用随机掩码,要么加人工扰动来制造模糊图,但这和真实新视角的模糊模式不太一样。SymDrive想了个聪明办法:它先有一个用真实视角照片训练好的3DGS模型(这个模型渲染新视角会模糊)。然后,对于一张真实(Ground Truth, GT)照片I₀,把摄像头向左移d米渲染一张图I₋d,再向右移d米渲染一张图Id。这两张模糊的渲染图,加上中间那张清晰的GT图I₀,就构成了一组完美的训练数据对。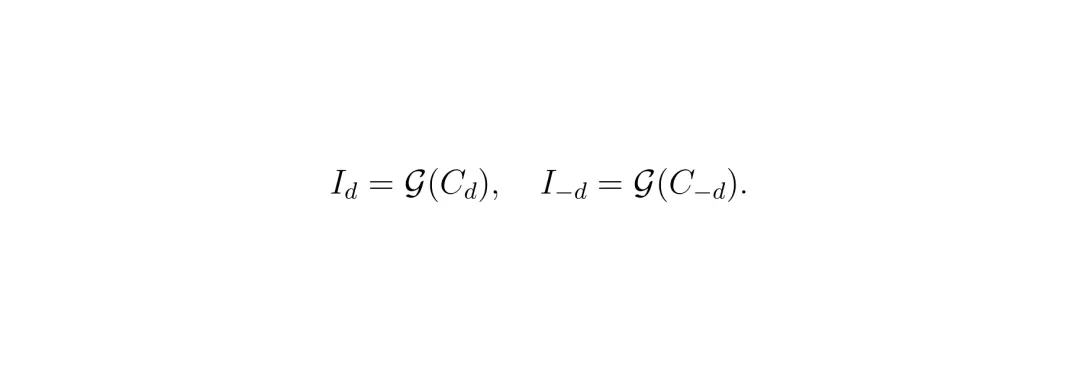 这就像一个老师拿着正确答案(GT),同时给你看两个角度略有错误的解题步骤(左右模糊视图),让你推测出中间的正确步骤。这种“对称双视图”输入,给了模型更丰富的几何线索来推理缺失的细节。有了数据,就开始训练扩散模型vθ。模型的学习目标很直接:给定左右模糊视图的编码z-d, zd和加了噪声的中间GT编码z0,t,要学会预测出清晰的信号。
这就像一个老师拿着正确答案(GT),同时给你看两个角度略有错误的解题步骤(左右模糊视图),让你推测出中间的正确步骤。这种“对称双视图”输入,给了模型更丰富的几何线索来推理缺失的细节。有了数据,就开始训练扩散模型vθ。模型的学习目标很直接:给定左右模糊视图的编码z-d, zd和加了噪声的中间GT编码z0,t,要学会预测出清晰的信号。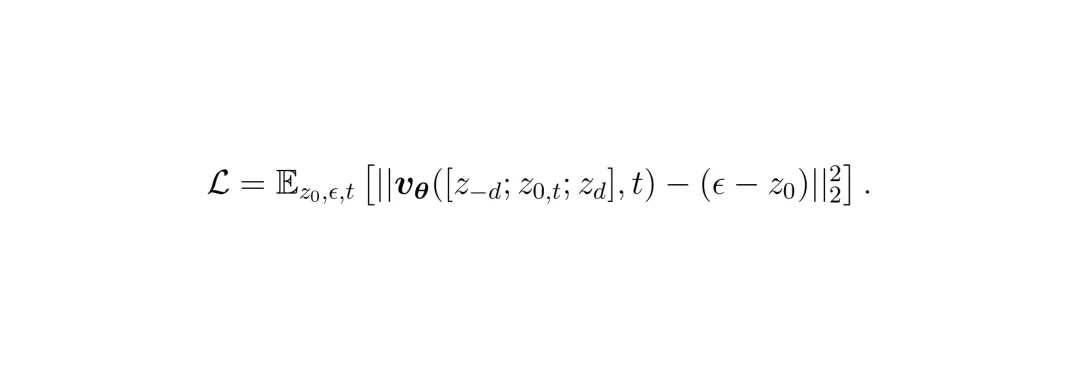 通过大量这样的训练,模型逐渐掌握了“看图补全”的魔法:只要看到某个视角左右两侧的样子,它就能脑补出中间视角应有的丰富细节。模型训练好了,怎么用来生成一整串连续的新视角呢?这里用到了“自回归”策略,就像我们走路,一步一步来。1. 从真实(GT)视角I₀开始。这是我们的坚实起点。 2. 要生成右边0.5米处的视图Îd:模型会同时看I₀(左边)和右边1米处原始的模糊渲染I2d(右边),然后“脑补”出中间的Îd。 3. 把新生成的Îd当作已知。现在要生成右边1米处的视图Î2d:模型看Îd(左边)和右边1.5米处的模糊渲染I3d(右边),再脑补出Î2d。 4. 如此链式反应下去,就像多米诺骨牌,高质量的细节从GT开始,一步步向外传播,保证了生成的连续视图既清晰又一致。直接让扩散模型从纯噪声开始生成,有时位置会对不准。SymDrive玩了个花招:它让生成过程从一个“半成品”噪声开始。这个半成品是用GT图加了一点噪声构成的,这样就保留了GT的大致结构和位置,模型只需要在“骨架”上“画”出细节和填补遮挡部分,既准确又真实。
通过大量这样的训练,模型逐渐掌握了“看图补全”的魔法:只要看到某个视角左右两侧的样子,它就能脑补出中间视角应有的丰富细节。模型训练好了,怎么用来生成一整串连续的新视角呢?这里用到了“自回归”策略,就像我们走路,一步一步来。1. 从真实(GT)视角I₀开始。这是我们的坚实起点。 2. 要生成右边0.5米处的视图Îd:模型会同时看I₀(左边)和右边1米处原始的模糊渲染I2d(右边),然后“脑补”出中间的Îd。 3. 把新生成的Îd当作已知。现在要生成右边1米处的视图Î2d:模型看Îd(左边)和右边1.5米处的模糊渲染I3d(右边),再脑补出Î2d。 4. 如此链式反应下去,就像多米诺骨牌,高质量的细节从GT开始,一步步向外传播,保证了生成的连续视图既清晰又一致。直接让扩散模型从纯噪声开始生成,有时位置会对不准。SymDrive玩了个花招:它让生成过程从一个“半成品”噪声开始。这个半成品是用GT图加了一点噪声构成的,这样就保留了GT的大致结构和位置,模型只需要在“骨架”上“画”出细节和填补遮挡部分,既准确又真实。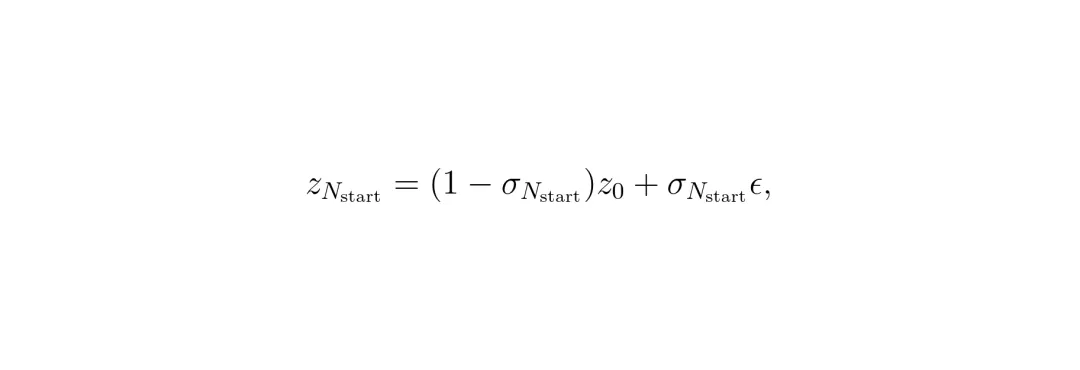 生成了高质量的新视角图像后,SymDrive并没有停手。它把这些“修好”的图当作额外的真值,回头去微调(Fine-tune)最初那个3DGS模型。这样,3DGS模型本身也学到了如何更好地渲染新视角,形成了一个“渲染-修复-优化”的增强闭环。下次再用这个优化后的3DGS模型生成训练数据时,起点质量就更高了。
生成了高质量的新视角图像后,SymDrive并没有停手。它把这些“修好”的图当作额外的真值,回头去微调(Fine-tune)最初那个3DGS模型。这样,3DGS模型本身也学到了如何更好地渲染新视角,形成了一个“渲染-修复-优化”的增强闭环。下次再用这个优化后的3DGS模型生成训练数据时,起点质量就更高了。无需训练!车辆插入如何实现光影自然融合?
这是SymDrive最令人叫绝的地方之一:它用来做车辆插入光影融合的,就是上面那个训练好的、用于新视角修复的同一个扩散模型,完全不需要额外训练!思路非常巧妙:把车辆插入看作一个特殊的“图像修复(Inpainting)”问题。1. 准备“待P图”:把一个完整的3D车辆模型(来自3DRealCar数据集)放到场景里,用3DGS渲染出一张带车的图。这张图里,车的光影和背景是脱节的。 2. 调用“修图师”:把这张图输入我们训练好的扩散模型。但这里有个关键操作——告诉模型只修改车辆区域。技术上,这是在扩散去噪的每一步,把车辆区域外的像素都重置回原始渲染图的状态(借鉴了RePaint策略)。 3. 魔法发生:这个模型本来就很擅长根据上下文(背景)来生成合理的图像内容。现在,它看到车辆区域需要“修复”,而周围的背景(天空、路面、其他车辆)提供了强大的光照、颜色和风格线索。于是,在迭代去噪过程中,模型自然地将车辆的色调、明暗、阴影调整得与背景浑然一体。 4. 反过来优化车辆模型:用生成的多张和谐图像,去微调这个3D车辆模型的颜色和透明度属性(保持几何不变)。这样一来,这个车辆模型就“学会”了在这个特定场景下该怎么呈现自己,以后放到这个场景的任何位置,渲染出来都是和谐的。你看,新视角修复和车辆插入,在模型眼里都是“根据已知上下文,生成未知区域合理内容”的问题。SymDrive用一个统一的框架和模型优雅地解决了,这设计真是有点东西!实验结果:新视角渲染与车辆编辑双双达到SOTA
光说不练假把式,SymDrive在Waymo Open Dataset上进行了全面测试,回答了三个关键研究问题。能,而且是全面领先。下表对比了在横向移动3米的新视角渲染任务上,各方法的表现。SymDrive在NTA-IoU(前景物体重建质量)和NTL-IoU(车道线重建质量)两个关键指标上均取得最佳,FID(图像真实感)也位列前茅。更重要的是,它不需要像一些对比方法那样依赖高清地图或车辆包围框作为额外条件,仅凭图像本身就能达到更高精度。| Method | Extracondition | NTA-IoU↑ | NTL-IoU↑ | FID√ |
| Street Gaussians[5] | | 0.498 | 53.19 | 130.75 |
| FreeVS [44] | | 0.505 | 53.26 | 104.23 |
| DriveDreamer4D [31] | bbox&map | 0.457 | 53.30 | 113.45 |
| ReconDreamer[12] | bbox&map | 0.539 | 54.58 | 93.56 |
| ReconDreamer++*[27] | bbox&map | 0.566 | 56.89 | 75.22 |
| Difix3D+ [10] | | 0.578 | 56.94 | 84.12 |
| ReconDreamer++f [27] | bbox&map | 0.572 | 57.06 | 72.02 |
| Ours | | 0.582 | 57.91 | 74.82 |
视觉对比更是碾压。从下面两图可以看出,SymDrive生成的画面细节最丰富,车道线、路面纹理、交通灯、周边车辆都更清晰、更准确,远超其他方法。图3:与ReconDreamer [12]和ReconDreamer++ [27]的定性对比。图4:与Street Gaussians [5]和StreetCrafter [11]的定性对比。RQ2:SymDrive在车辆插入任务上也是SOTA吗?是的,大幅领先。下表展示了插入车辆并进行和谐化处理后的FID分数(越低越好)。SymDrive以显著优势排名第一。值得注意的是,专门用于新视角修复的Difix3D+在这个任务上反而使FID变差了,因为它会不加区分地修改整个图像。而SymDrive的针对性修复策略优势尽显。| Method | ModelCapability | FID√ |
| 3DRealCarInsert | | 41.27 |
| Difix3D | novelviewrestoration | 53.64 |
| CosXL-Edit | pixel to pixel image edit | 46.54 |
| Ours | | 32.60 |
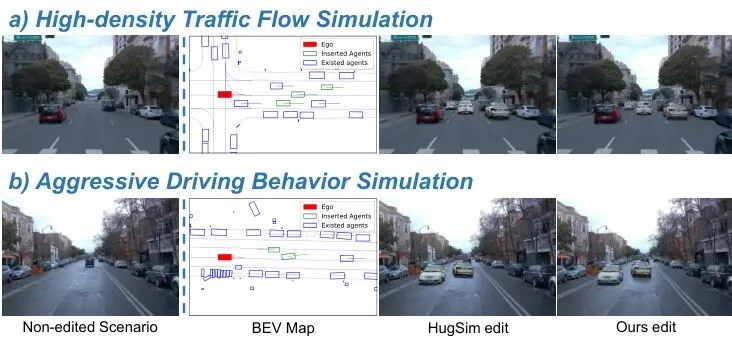
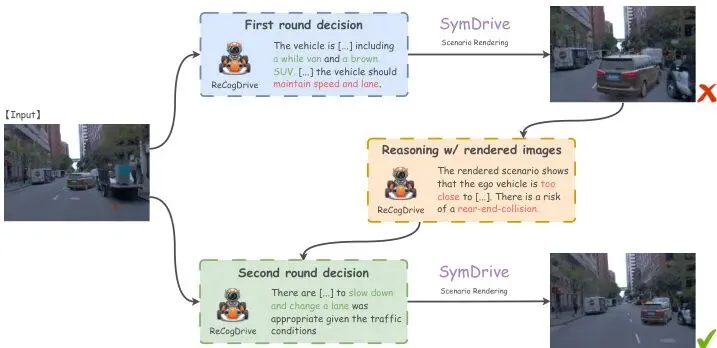
视觉上,插入的车辆光影自然,与背景完美融合,纹理细节也更逼真。初步验证显示潜力巨大。SymDrive可以生成高保真的闭环仿真序列。如图6所示,它可以模拟正常车流,也可以生成激进变道、超车等高危场景。更重要的是,论文尝试将生成的仿真场景输入给一个端到端的视觉语言驾驶模型进行测试,模型能够基于仿真的危险场景调整其初始决策,这证明了SymDrive生成的数据对于评估和提升自动驾驶系统具有实用价值。图7:在我们的仿真环境中进行VLM规划与推理的示例。局限与展望:远距离物体与物理约束仍是挑战
当然,SymDrive并非完美。论文也坦诚指出了两点主要局限:1. 远距离物体处理不佳:对于非常遥远的物体,它们在图像中像素稀少,基于图像的扩散先验难以有效工作,可能导致时间上的不一致(比如远处车辆闪烁)。 2. 缺乏硬物理约束:目前的系统可以控制车辆运动轨迹,但没有集成真正的物理引擎,无法模拟车辆碰撞、复杂的物理交互等。未来,作者们计划探索视频扩散模型来提升长距离一致性,并集成物理引擎来进一步提升仿真的真实性和安全性验证能力。龙迷三问
1. 文中的3DGS和SOTA是什么意思?3DGS是“3D Gaussian Splatting”的缩写,中文可称“3D高斯泼溅”,是一种新颖的3D场景表示和实时渲染技术,用很多个带颜色和透明度的3D高斯椭球体来表示场景,渲染速度极快。SOTA是“State-Of-The-Art”的缩写,即“最先进的”,指在当前某个研究任务上性能最好的方法。
2. 为什么对称视图训练比单视图训练更好?单视图修复就像只给你看一道错题,让你猜正确答案,歧义很大。对称双视图则像同时给你看这道题在左、右两个相关但不同的版本(都是错的),你通过对比这两个错误版本,能更准确地推断出它们之间那个“缺失”的正确版本应该是什么样子。这提供了更强的几何约束,减少了模糊性。
3. 车辆插入的“无需训练”是指什么?这里的“无需训练”特指不需要为车辆插入这个新任务重新训练一个专门的扩散模型。SymDrive利用已经为“新视角修复”任务训练好的那个扩散模型,通过改变输入(添加掩码控制修复区域)和推理策略,直接让它完成车辆光影融合的任务。这是一种巧妙的“一模型多用”,省去了额外的训练成本和数据准备。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~龙哥点评
论文创新性分数:★★★★☆
核心创新点“对称自回归在线修复”及将其用于统一处理新视角渲染和车辆编辑的思路非常巧妙且有洞察力,并非简单堆砌现有技术。实验合理度:★★★★☆
在主流数据集上与多类SOTA方法进行了充分对比,定量指标和定性可视化都很详实。消融实验也验证了关键组件的有效性。对比公平。学术研究价值:★★★★★
为自动驾驶仿真这一关键应用领域提供了一个高效、统一的框架新范式。其“对称视图”、“一模型多用”的思想对3D生成、图像修复等相关领域也有启发意义。稳定性:★★★☆☆
方法依赖于预训练的3DGS模型和扩散模型的质量。在训练数据覆盖不到的场景或极端视角下,扩散模型的“脑补”可能产生不合理内容。闭环中的迭代优化也可能积累误差。适应性以及泛化能力:★★★☆☆
主要针对城市道路驾驶场景。其数据生成和模型训练方式与场景结构紧密相关,直接迁移到非结构化环境(如越野、室内)可能需要调整。硬件需求及成本:★★☆☆☆
训练需要多张A100 GPU。推理时,3DGS渲染部分极快,但扩散模型去噪过程(50步)较为耗时,难以达到高帧率实时仿真,是性能瓶颈。复现难度:★★★☆☆
论文方法描述清晰,但涉及多个技术栈(3DGS、扩散模型、闭环优化)。预训练的基础模型(Flux.1-dev)和3D车辆资产(3DRealCar)的获取与处理有一定门槛。产品化成熟度:★★☆☆☆
目前更偏向一个强大的研究原型。要产品化为稳定的工业级仿真工具,需要在推理速度、极端案例鲁棒性、易用性以及与传统仿真软件(如CARLA)的集成方面做大量工程化工作。可能的问题:本文在方法设计和实验验证上都很扎实。主要问题在于对“自回归链式传播可能积累误差”以及“扩散模型推理慢”的讨论尚浅,未来工作中如何量化并缓解这些问题是关键。[1] Kerbl, B., et al. “3D Gaussian splatting for real-time radiance field rendering.” ACM TOG 2023. (3DGS原始论文)[2] Yan, Y., et al. “Street Gaussians: Modeling dynamic urban scenes with Gaussian splatting.” ECCV 2024. (动态场景3DGS基线)[12] Ni, C., et al. “ReconDreamer: Crafting world models for driving scene reconstruction via online restoration.” arXiv:2411.19548, 2024. (重要的对比方法)[27] Zhao, G., et al. “ReconDreamer++: Harmonizing generative and reconstructive models for driving scene representation.” arXiv:2503.18438, 2025. (重要的对比方法)[30] Black Forest Labs. “Flux.1-dev.” GitHub, 2024. (使用的扩散模型基础)论文原文:https://arxiv.org/pdf/2512.21618v1.pdf
*本文仅代表个人理解及观点,不构成任何论文审核意见,具体以同行评议结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的"阅读原文",查看更多原论文细节哦!

加入【龙哥读论文】知识星球,助你高效突破科研瓶颈,前沿研究一手掌握!
元旦福利暴击!!🐉 龙哥读论文知识星球:让你看论文像刷视频一样简单!元旦星球优惠券限时放送,每次发券少10元,现在是最优选!元旦假期专属,有效期截止26年1月16日,下方扫码立减,解锁一整年的论文干货+技术资源!手慢则无,冲就对了!

欢迎加入龙哥读论文粉丝群,
添加龙哥助手微信号加群:kangjinlonghelper。
一定要备注:研究方向+地点+学校/公司+昵称(如 图像处理+上海+清华+龙哥),根据格式备注,可更快被通过且邀请进群。