自动驾驶(AD)技术已逐渐成熟,但用户对自动驾驶的信任度和接受度不足,限制了其普及与推广。本文旨在通过探索合理的交互式输出模态来应对这些挑战并缓解信任危机。首先,我们提出了一种包含9个不同反馈层级的多模态交互式输出方案。随后,采用驾驶信任体验问卷(DTEQ)、眼动追踪和接管意愿记录三种方法针对该方案开展了模拟驾驶实验。最后,分析了不同交互输出层级下结果的趋势和相关性。结果表明,用户信任体验与交互输出模态的层级高度正相关。在合理设计下,多模态和高层级交互式输出有助于提供更全面的反馈信息,减轻用户的视觉负荷,并增强信任。本研究为用户信任体验的提升奠定了基础,并有助于推动自动驾驶的应用与普及。
自动驾驶技术虽日趋成熟,但用户信任度低限制了其推广应用
现有研究多聚焦于单一模态或紧急情况下的警报设计,忽视了正常高度自动驾驶(L4+)状态下多模态交互的重要性
研究核心问题:在正常高度自动驾驶状态下,交互模态输出的类型和强度如何影响用户信任体验?
设计了9个层级的多模态交互输出方案,基于视觉、听觉、触觉三种模态的不同强度组合
构建静态驾驶模拟器平台,选取4种典型道路场景进行实验
驾驶信任体验问卷(DTEQ)- 获取主观评价
眼动追踪 - 测量视觉负荷与注意力分配
接管意愿记录 – 评估用户行为反应
用户信任体验与交互输出模态的层级高度正相关
合理设计下,多模态、高层级的交互输出能:
提供更全面的反馈信息
降低用户视觉工作负荷
显著提升信任水平
为高度自动驾驶的多模态交互设计提供了系统化框架和实证依据
提出9级交互输出方案可作为设计参考标准
验证了多模态交互在增强用户信任、促进自动驾驶普及方面的重要作用
H1:在高度自动驾驶(L4+)正常驾驶状态下,不同层级的交互输出模态对用户信任具有差异化影响
H2:增加交互输出模态的类型与强度可提升用户信任水平
样本量:30名持有驾照驾驶员(滚雪球抽样)
年龄结构:18-35岁占90%,符合智能网联汽车主力消费群体特征
筛选标准:身体健康,视力正常或矫正正常
伦理审批:通过同济大学科技伦理委员会审批(No: tjdxsr053)
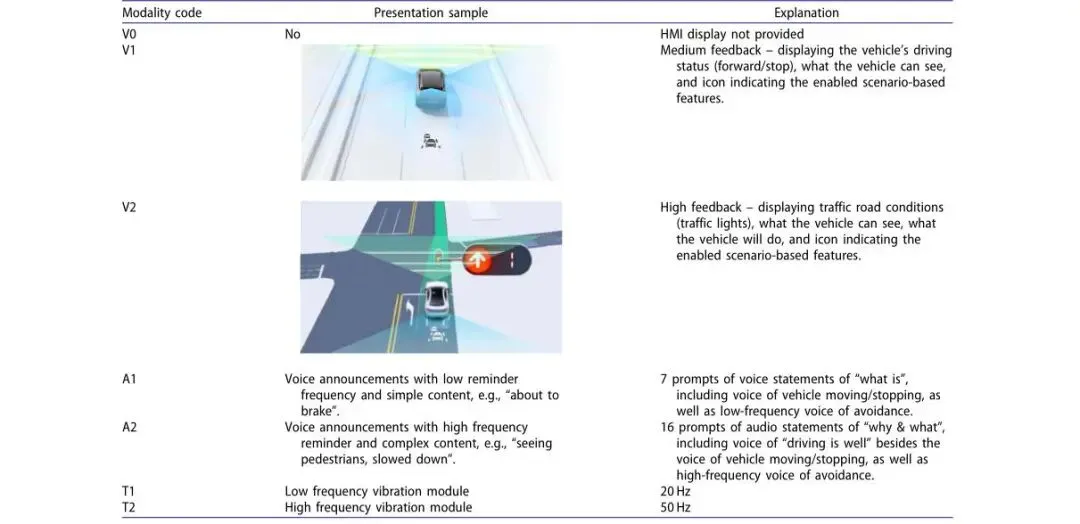
使用GoPro预录制4种典型道路场景(各1分钟)
场景涵盖:城市拥堵、高速巡航、交叉路口、复杂路况
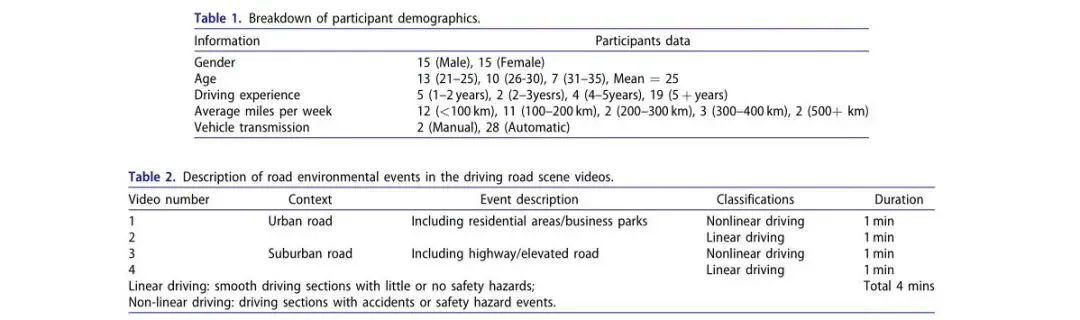
9级分层体系:L0-L8,分为4个强度类别(无/低/中/高)
设计依据:文献理论+量产车交互实践+设计团队经验
遵循可用性原则进行预实验,排除误解与不信任风险
对4名资深驾驶员进行一对一访谈(平衡性别/年龄/职业)
访谈4大主题:视觉/听觉/触觉输出形式及其高低强度界定、多模态同步反馈的认知
根据反馈修订方案(如V2增加信号灯/路线信息,V1增加车辆动画;听觉由警报改为分级语音)
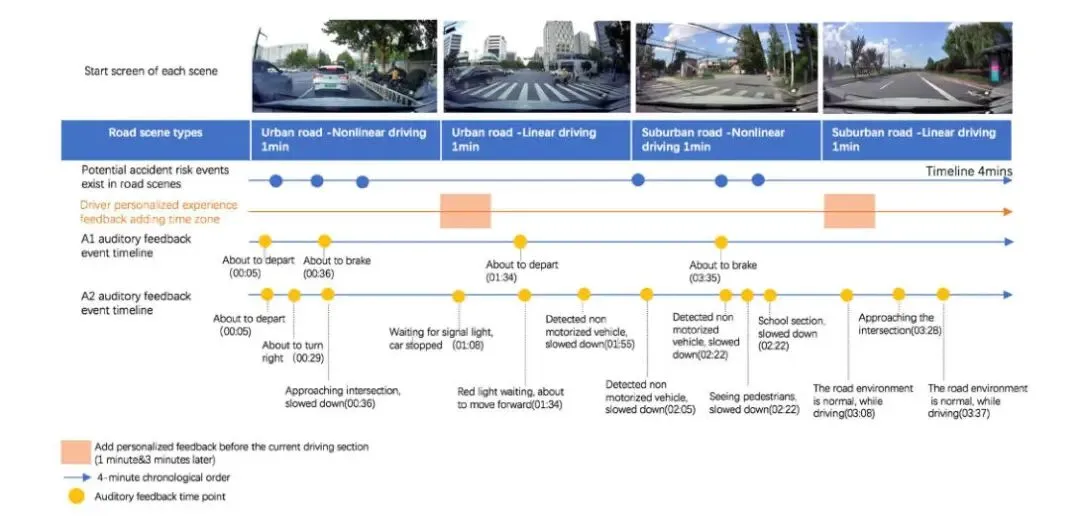
构建"人-车-环境"驾驶需求场景库,通过用户旅程法收集要素
对30名被试进行问卷调研,生成个性化需求特征库(功能激活偏好、娱乐、监控等)
结合情境感知(CA)理论实现高语境化体验
视觉:功能激活图标显示(2秒)
听觉:基于不同激活指令的语音内容
触觉:与听觉同步的座椅振动,强度分级
包含基础层级(A1/A2)和个性化需求反馈
采用女声普通话语音,语速/音量恒定
明确语音内容、时机与序列
混合设计:组内+组间设计,平衡练习效应与个体差异
分组依据:年龄、驾龄、信息偏好问卷确保组间同质
3组×3层级:每组仅体验3个非连续层级(避免疲劳)
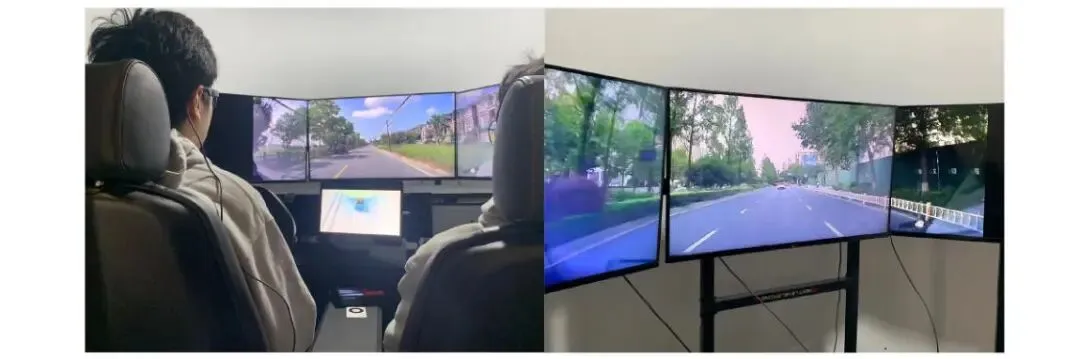
平台:同济大学设计与创新学院静态驾驶模拟器
视觉:3台Sony 42" 4K液晶屏(前方道路)+ iPad Pro 2022(中控信息)
听觉:驾驶座两侧扬声器(播放道路/引擎音)
眼动:Tobii Glasses 3(50Hz采样率,连接ThinkPad)
触觉:座椅靠背振动模块
软件:Adobe Premiere/Illustrator制作动画,Text-to-Speech生成语音,秒表记录接管意愿
基于Jian等(2000)信任问卷,增加人车交互行为、技术可接受度、场景感知维度
7点李克特量表(1=极不同意,7=极同意)
AOI划分:AOI1=道路环境(LCD屏),AOI2=车载视觉显示(iPad)
指标:总注视时长、平均注视时长、注视次数
处理:Tobii Pro Lab软件,采用I-VT滤波器(剔除<60ms短注视)
被试手持秒表,实时记录感知到危险或不信任的时刻
基于行为主义理论,捕捉对界面刺激的真实行为反应
知情同意:提供信息表并签署同意书
前测问卷:收集人口学、驾驶习惯、偏好数据
设备校准:佩戴眼动仪并完成验证,调整舒适坐姿
任务说明:告知AD系统定义,要求注意车内反馈,忽略仪表干扰,可随时终止
正式实验:每组体验3个层级,每层级结束后填写DTEQ
全程记录:眼动数据+接管意愿次数/时间
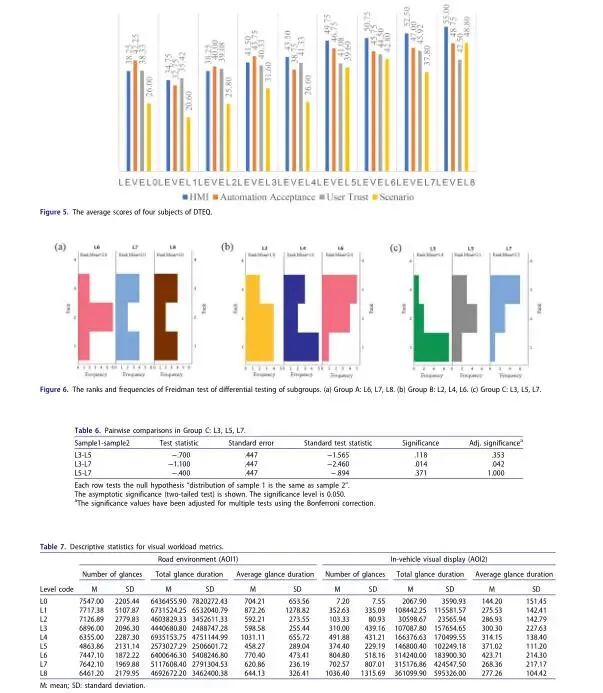
1) 总体趋势:L8层级信任体验得分最高,L1最低,Friedman检验显示9个层级间存在显著差异(p=0.001),验证了分层设计的合理性
2) 数据特征:L5-L8层级中位数水平相近,L2、L3、L7层级数据离散度较高
3) 分项指标:场景接受度、信任度、HMI评价、自动化接受度四项指标均随交互水平提升呈整体上升趋势
a) 高反馈组(L6/L7/L8):触觉反馈有无/强弱对问卷得分无显著影响(p=1.00)
b) 低中高水平组(L2/L4/L6):听觉反馈有无对得分无显著影响(p=0.301)
c) 中高反馈组(L3/L5/L7):L3(低视觉/低听觉)与L7(高视觉/高听觉)差异显著(p=0.042),但L3-L5和L5-L7差异不显著
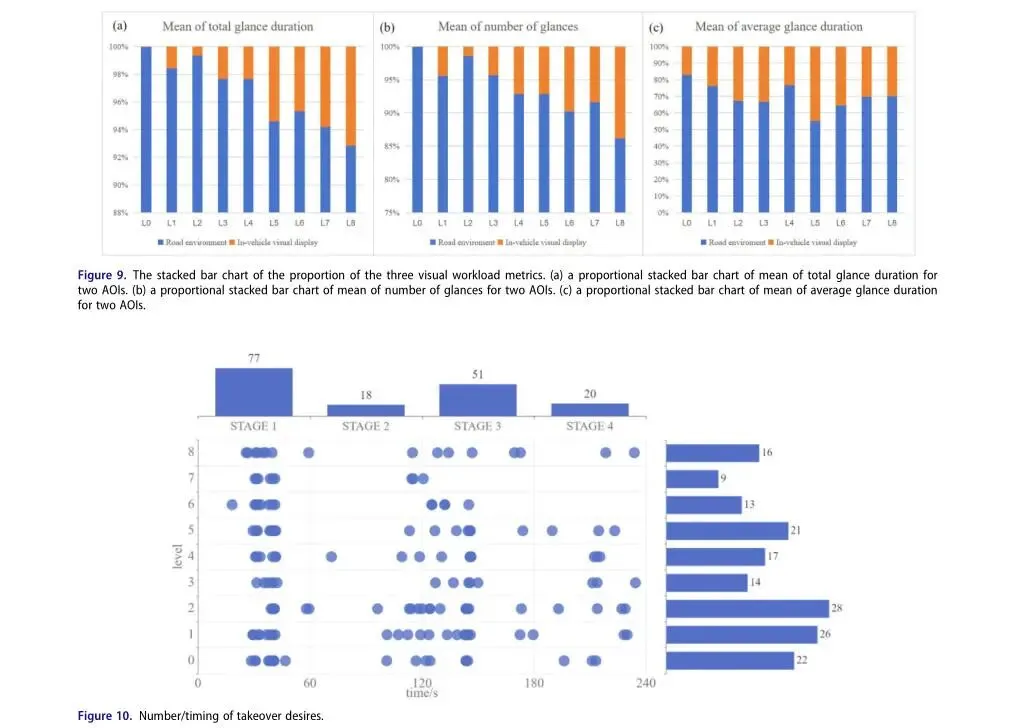
显著性检验:道路环境注视(AOI1)和车内显示注视(AOI2)在所有指标上均存在显著主效应(p<0.001)
a) AOI1(道路环境):总注视时长占比、注视次数占比随交互层级提升呈下降趋势
b) AOI2(车内显示):上述指标呈相反上升趋势
c) 平均注视时长:未呈现显著变化趋势
结论:交互输出水平越高,用户视觉注意力从道路环境向车内信息转移越明显,表明认知负荷降低
1) 驾驶状态差异:线性驾驶(直线行驶)接管意愿次数显著少于非线性驾驶(变道/转弯)
2) 道路类型差异:城市道路场景的总接管意愿次数(95次)明显高于郊区道路(71次)
3) 总体规律:随交互层级提升,接管意愿次数呈下降趋势
核心负相关(客观-主观数据):
道路环境总注视时长占比(TGD-AOI1)与DTEQ总分呈强负相关(r=-0.916, p<0.001)
道路环境注视次数占比(NOG-AOI1)与DTEQ总分呈负相关(r=-0.833, p<0.001)
核心正相关(客观数据间):
车内显示注视占比与接管意愿次数呈正相关(但p>0.05,未达显著水平)
综合结论:交互层级提升→用户信任问卷得分提高→对道路环境的视觉监控需求降低,形成 "信任增强-监控减负" 的验证闭环
H1验证:不同交互输出层级对高度自动驾驶正常状态下的用户信任体验存在显著差异,得到数据支持
问卷、眼动、接管记录三项结果均证实层级间的差异化影响
H2验证:交互模态的类型增加与强度提升能改善用户信任,结论成立
与Verberne等(2012)关于ACC系统的"信息+行动"反馈研究结论一致
与Ma等(2021)关于高视觉反馈提升信任的研究相呼应
与Yun & Yang(2020)关于视觉-听觉-触觉组合最优的结论一致
冗余关系:在高反馈水平下,触觉反馈的有无/强弱不显著影响信任得分(Group A/B),说明其他模态已充分满足信息需求
增量关系:Group C中L3(低视觉/低听觉)与L7(高视觉/高听觉)差异显著,说明模态组合强度变化能传递差异化信息,符合Martin(1995)的增量关系理论
眼动-信任负相关:高信任→减少对道路环境的注视,与前人研究(Barnard & Lai, 2010; de Winter et al., 2014)结论一致,形成"信任增强-监控减负"闭环
Koo等(2015)发现"为什么"信息(如"前方有行人,减速")比"做什么"信息(如"即将刹车")更受偏好但会增加负面情绪
本研究A2类提示(解释原因)的信任体验优于A1类(仅描述行为),但因问卷结构差异未测量负面情绪变化
Reeves & Nass(1996)强调机器礼貌的重要性;本研究设计中,A2类语音通过解释行为原因体现了"礼貌"原则
Yang等(2017)指出信任随时间发展;本研究采用混合设计减少时间因素干扰,但长期追踪(1个月后)显示23/30的被试希望降低反馈强度,说明初期信任建立与长期使用需求存在动态变化
参考Ranjbar等(2022)关于视障/听障群体独立出行的研究,本研究在问卷中增加了无障碍接受度测量项,呼应了包容性设计的必要
模态局限:仅覆盖视觉/听觉/触觉,未纳入嗅觉、味觉
场景局限:仅晴朗天气、无事故场景,缺乏雨雪天气与突发事故情境
实验效应:研究者现场观察可能导致"霍桑效应",被试行为或受观察影响
样本局限:被试均为年轻人(18-35岁占90%),年龄范围过窄
拓展老年等特殊群体研究,提升自动驾驶普适性
探索恶劣天气与事故场景下的信任机制
开发动态自适应反馈系统,根据交通状况调整交互强度
长期追踪研究,建立信任发展模型
完善无障碍设计,满足功能损伤用户需求
总之,我们通过静态驾驶模拟器研究,设置了九个反馈层级,以探索AD车辆中多模态反馈的用户信任体验。驾驶需求场景数据库已整合到实验设计中,以实现用户的个性化体验,为AD的智能与场景化输出反馈提供基础和依据。通过显著性分析验证了多模态与多层设计的有效性。研究结果表明,不同层级的多模态输出反馈对AD系统中的驾驶信任体验和视觉注意力具有不同影响。输出模态的多样性可提升参与者的驾驶信任体验,并减少驾驶员对道路环境的关注。更高反馈层级的多模态输出能够增强参与者对自动驾驶车辆的信任体验。在研究设计中,通过多模态与多层设计验证了反馈输出的效度和意义。未来研究可探索使用频率与经验对自动驾驶反馈多模态性的影响,以及用户需求场景如何持续迭代以满足每位驾驶员的信任体验要求。除自动驾驶车辆外,本研究也为其他座舱(飞机座舱、高速列车驾驶舱)的多模态输出反馈提供了启示。