关注本公众号并设星🌟标,不错过最新精彩内容
在端到端自动驾驶领域,论文数量早已爆炸,但真正能“跑起来、复现快、改得动”的开源项目却凤毛麟角。
2025年,一批兼具工程完整性、技术前瞻性与社区活跃度的高质量仓库悄然崛起——它们不靠顶会光环吸睛,而是凭可复现性、模块清晰度和闭环评测能力赢得开发者口碑。
这些项目覆盖了从数据生成、规划决策到多模态对齐的全链路,不是玩具Demo,而是可直接作为基线或模块集成的工业级参考。
DiffusionDrive:扩散模型也能45 FPS?实时规划新标杆
来自华中科技大学与地平线的 DiffusionDrive,直面扩散模型在自动驾驶中的最大痛点:多步去噪太慢,难以实时。
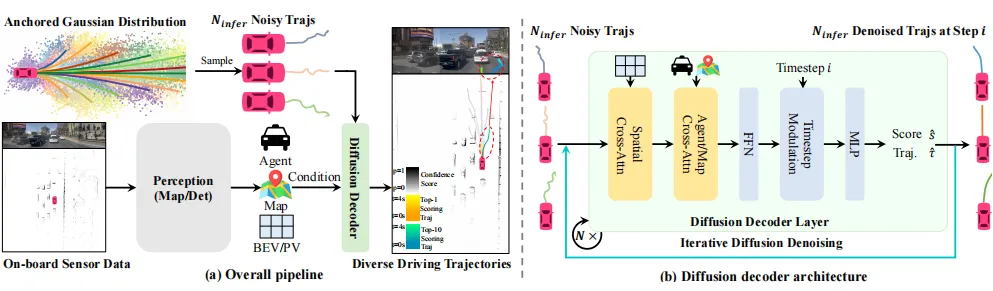
团队提出两大创新:
一是引入多模态驾驶锚点作为结构化先验,引导生成方向;
二是设计截断扩散日程,将传统50+步去噪压缩至仅需2–4步。
结果令人惊叹:在RTX 4090上实现45 FPS实时推理,同时在NAVSIM基准上取得88.1 PDMS的高分。
更难得的是,项目完整开源了训练代码、推理脚本与预训练模型,为行业提供了一个高性能、低延迟的扩散规划标准实现。
如果你正探索生成式模型在实时系统中的落地,DiffusionDrive 是必看范本。
OpenEMMA:让大模型“边想边开”,无需重训千亿参数
由德克萨斯农工大学等多校联合推出的 OpenEMMA,巧妙绕开了大模型微调的算力黑洞。
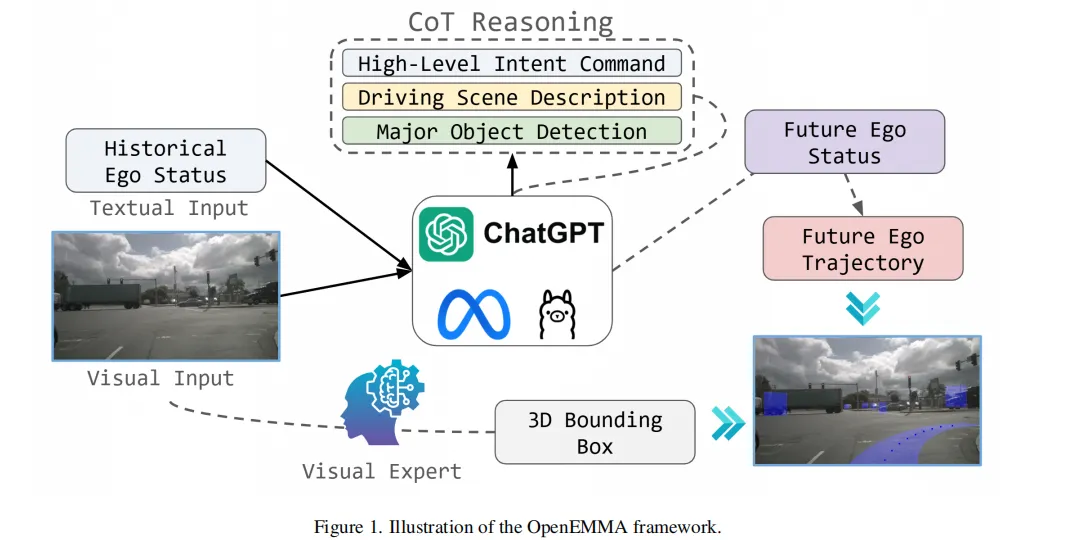
它不重新训练MLLM,而是通过Chain-of-Thought(CoT)推理机制,引导现有模型(如LLaVA、Qwen-VL)在输出驾驶动作前,先生成一段逻辑链条。
例如:“前方有行人 → 需减速 → 当前车速30km/h → 目标速度15km/h”。
这种显式推理不仅提升了决策可解释性,更显著增强了模型在复杂交叉口、施工区等场景的泛化能力。
项目最大价值在于:提供了一套轻量级适配框架,研究者只需接入自己的VLA模型,即可快速获得带推理能力的驾驶智能体。
对于资源有限的团队,这是低成本验证MLLM驾驶潜力的最佳入口。
Diffusion-Planner:告别“平均轨迹”,生成多样合理行为
清华、自动化所与毫末智行合作的 Diffusion-Planner,从根本上挑战了模仿学习的局限——传统方法只能输出“最平均”的轨迹,缺乏应对突发状况的灵活性。
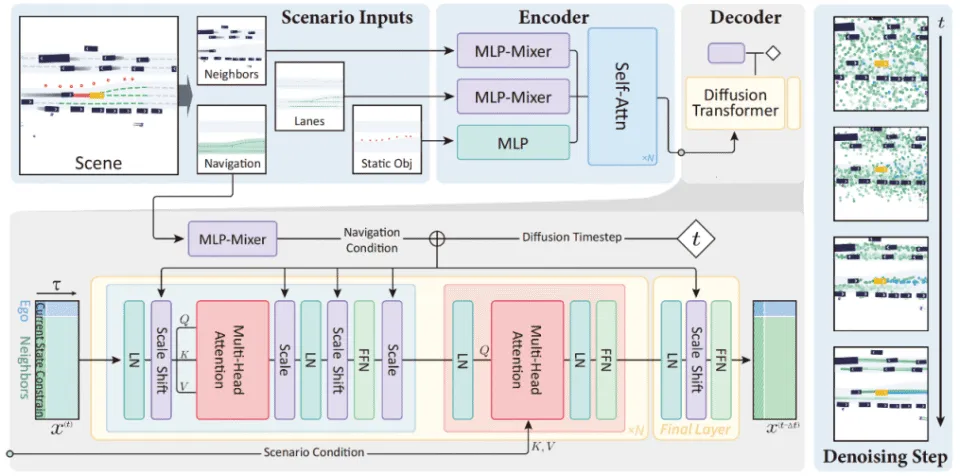
该模型采用扩散过程生成多模态轨迹,同一场景可输出左绕、右避、刹停等多种合理方案。
关键技术在于学习型打分函数引导,确保生成轨迹既多样又安全。更妙的是,它将自车规划与他车预测统一建模,使交互更自然。
在nuPlan闭环评测中表现领先,并在200小时实车配送数据上验证了对不同驾驶风格的适应性。
如果你想构建具备“人类式应变能力”的规划器,Diffusion-Planner 提供了完整技术路径。
UniScene:用一张图生成视频+点云+占据,数据合成革命
上海交大与旷视等机构推出的 UniScene,瞄准了自动驾驶最大的隐性成本:高质量标注数据获取难。

其核心思想是:以语义占据(occupancy)为统一中间表示。
用户只需输入道路布局,系统先生成BEV占据图(含几何与语义),再以此为条件同步生成多视角视频与LiDAR点云。三者天然对齐,且占据图自带像素级标注。
这意味着,一套流程即可产出感知、预测、规划所需的所有模态数据,大幅降低数据制备的重复投入。
实验表明,合成数据能有效提升下游任务性能。对缺乏实车采集能力的团队,UniScene 是构建仿真训练闭环的利器。
ORION:让语言模型真正“指挥”轨迹生成
华中科大与小米汽车联合开发的 ORION,解决了VLA模型中“说一套、做一套”的割裂问题。
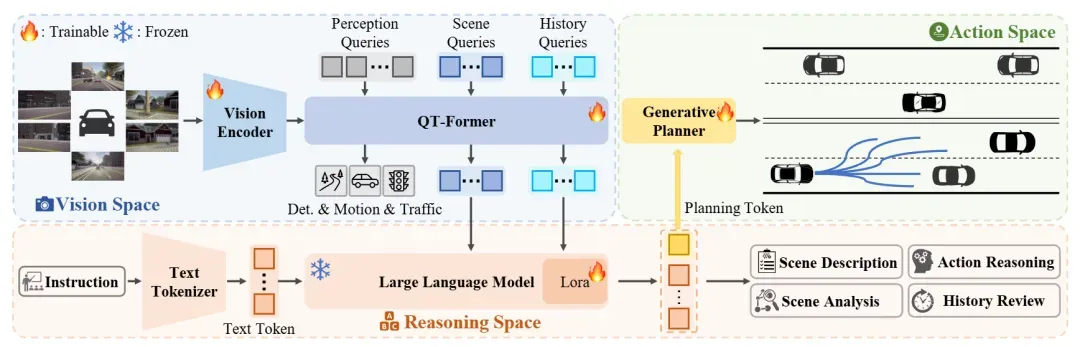
它通过QT-Former聚合历史状态,让LLM输出高层“规划token”(如“缓速右转”),再由专用解码器将其转化为精确轨迹。
关键突破在于端到端联合优化:语言推理与轨迹生成共享梯度,确保语义意图能稳定驱动物理动作。
在Bench2Drive评测中,其驾驶得分达77.74,成功率54.62%,大幅领先同类方法。
项目完整开源了训练、推理与评测代码,为构建“可解释、可控制”的端到端系统提供了清晰范式。
FSDrive:用“画面思考”,弥合视觉与规划的鸿沟
西安交大与阿里达摩院提出的 FSDrive,开创了“视觉化CoT”新范式。
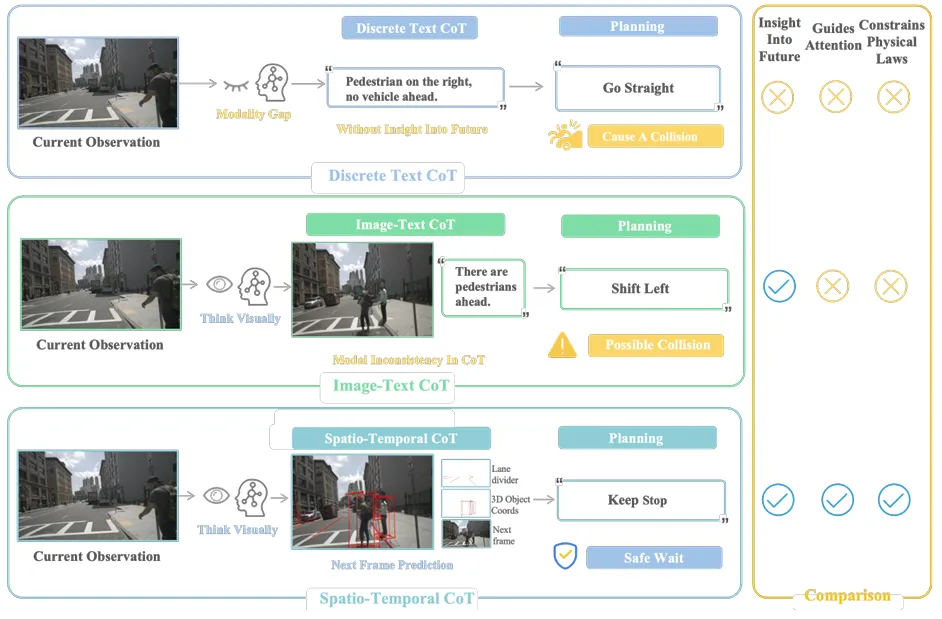
传统CoT依赖文字推理,易丢失空间细节;而FSDrive训练VLA模型先预测未来场景画面(含车道线、3D框等),再基于这幅“心理预演图”逆向生成轨迹。
这种以视觉为中间表示的推理链,显著提升了对物理规律的遵从性。
项目通过将视觉token纳入词表统一训练,并采用课程学习策略,实现了高精度与高安全性的统一。在nuScenes与NAVSIM上均取得SOTA结果。
AutoVLA:动作Token化,让语言模型直接“开车”
UCLA的 AutoVLA 提出一个大胆设想:把连续轨迹离散成“动作词”,让语言模型像写句子一样输出驾驶指令。
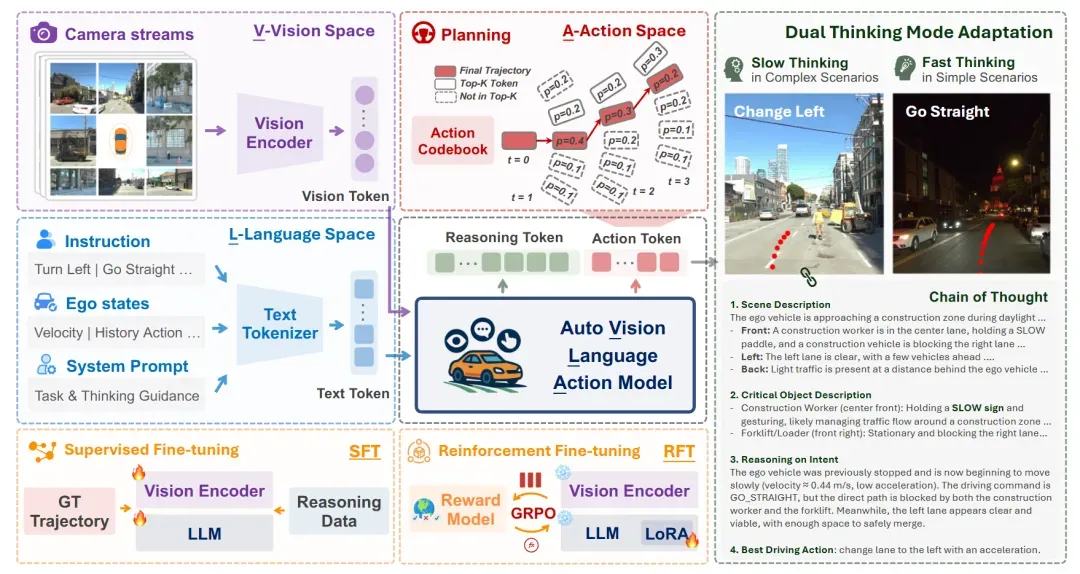
例如,“加速→左转→刹车”被编码为一串token,由自回归模型直接生成。这从架构上保证了动作的物理可行性。
更聪明的是,模型具备快慢双模式:简单路段直接规划(快思考),复杂路口启动CoT推理(慢思考),并通过强化学习微调抑制冗余。
在nuPlan、Waymo等多基准验证有效,其动作Token设计与训练配方极具参考价值。
OpenDriveVLA:纯视觉输入,统一生成动作与问答
慕尼黑高校团队的 OpenDriveVLA 展示了纯视觉端到端系统的潜力。
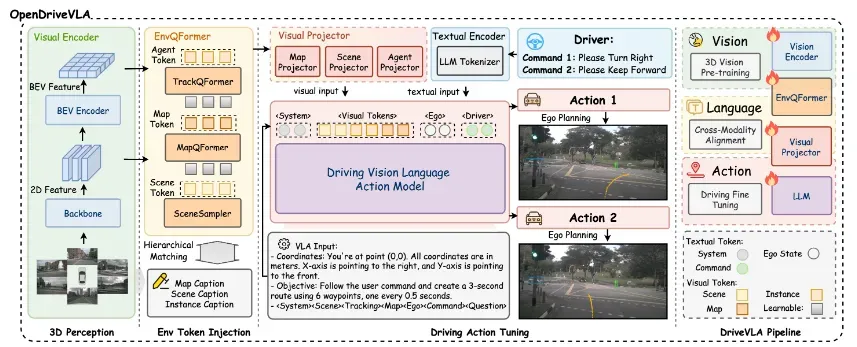
它仅依赖摄像头输入,通过分层对齐机制将2D/3D视觉特征映射到统一语义空间,再自回归解码出动作序列。
模型不仅能完成闭环驾驶,还能回答“前方是否有施工?”等问题,证明单一网络可兼顾行为与理解。
开源代码结构清晰,是学习VLA系统集成的优质模板。
SimLingo:言行一致,才是可信的AI司机
Wayve与图宾根大学的 SimLingo(CarLLaVA)聚焦“一致性”:确保语言描述与驾驶行为逻辑统一。
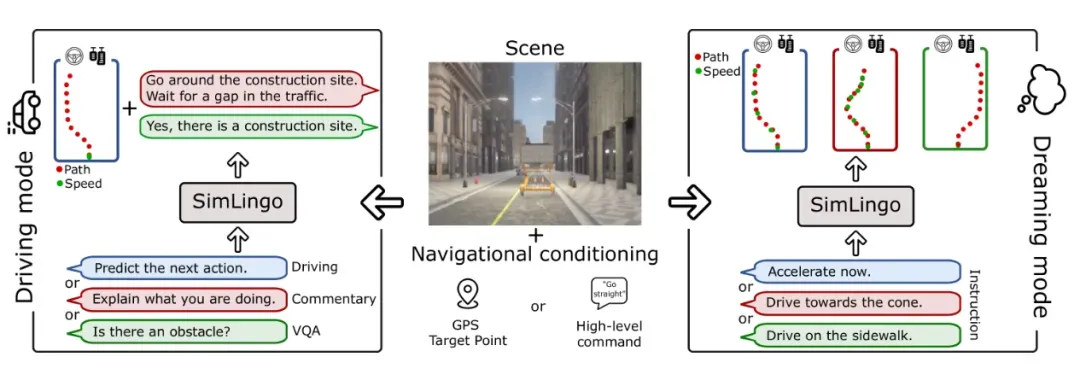
例如,当模型说“正在避让左侧车辆”,其轨迹必须真实体现左偏。
通过多任务联合训练,它在CARLA Challenge 2024中夺冠,验证了纯视觉架构下可同时实现高性能驾驶与可靠语言交互。
跑通Demo,比精读论文更重要
这些项目的价值,远不止于Star数或论文引用。
它们是经过真实数据验证的工程积木,包含数据预处理、训练调度、指标计算、可视化等完整流水线。
建议开发者:不要只看README,直接Clone下来跑通Demo。
修改一个超参、替换一个模块、观察指标变化——这种动手实践,才能真正构建你的自动驾驶技术直觉。
毕竟,在这个快速迭代的领域,能跑起来的代码,永远比完美的理论更有力量。
如需转载,请注明出处
#端到端自动驾驶#开源项目#VLA模型#具身智能#才创科技#才创机器人+

