想象一下,你坐在自动驾驶汽车里。车子正在平稳行驶,突然前面出现了一个从未见过的场景。比如说,一只狗突然从路边的灌木丛里窜出来。这时候,自动驾驶系统该怎么应对呢?
这就要靠世界模型了。
什么是世界模型
世界模型:一种能够理解和预测环境状态的AI系统。在自动驾驶领域,它可以根据当前的驾驶场景,预测未来可能发生的各种情况,包括车辆自己的运动轨迹和周围其他道路使用者的行为变化。
你可以把世界模型想象成自动驾驶系统的"想象力"。就像人类司机在开车时,会不自觉地预判前方的车会不会突然刹车,旁边的行人会不会横穿马路一样,世界模型也能让AI在真正遇到危险之前就做好准备。
这听起来很神奇,但实现起来可没那么简单。
传统方法的问题
现有的自动驾驶系统有个根本性的问题:信息孤岛。
系统把感知、预测、规划分成独立的模块,每个模块只处理自己的事情。这就像一个团队里,有人只负责看路,有人只负责想辙,有人只负责开车,但彼此之间缺乏有效沟通。
端到端自动驾驶:一种让AI直接从摄像头图像学到驾驶操作的范式。就像人类司机看到路况直接转动方向盘,而不是先计算距离再查表决定转多少度。
更糟糕的是,很多基于视觉语言模型(VLM)的方法,先把看到的场景转换成文字描述,再基于文字做规划。这就像你看到一个精彩瞬间,但必须先把它写成一篇作文,再根据作文来决定下一步行动。信息在这个过程中会大量流失,误差还会不断累积。
试想一下,如果感知模块看到了前方的车,但它不知道规划模块打算怎么应对。规划模块想好了要变道,但它没有直观地看到变道后的场景会是什么样子。这就像你在打篮球,队友把球传给你了,但你不知道篮筐在哪,只能瞎扔。
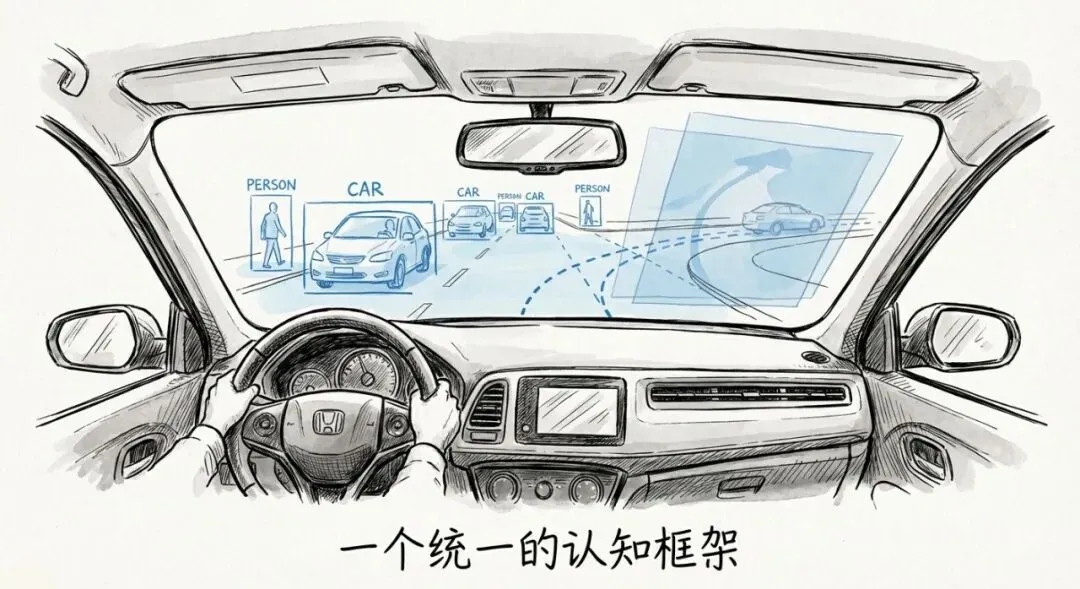
一个统一的认知框架
来自Bosch研究院和华盛顿大学的团队提出了自动驾驶世界模型UniDrive-WM,让自动驾驶系统像人类司机一样,在一个统一的框架里同时完成理解、规划和未来场景想象。
这个框架是怎么工作的呢?想象一下你正在开车:
第一,多视角观察。你的眼睛不只是盯着正前方,还会扫视左右后视镜,甚至余光会注意到路边的行人。UniDrive-WM也类似,它同时处理多个摄像头的输入,加上过去几秒的历史信息。
第二,场景理解。你的大脑会迅速判断:前面那辆车在减速吗?旁边的车道有空位吗?红绿灯还有多久变?UniDrive-WM通过QT-Former模块提取这些关键信息。
QT-Former:一种基于Transformer的视觉编码器,使用可学习的查询来从图像特征中提取有用信息。就像你在一幅画上用放大镜找重点,QT-Former就是那个智能放大镜。
第三,轨迹规划。基于对场景的理解,你会决定:减速跟车,还是变道超车。UniDrive-WM的轨迹规划器会产生一个潜在分布,预测未来几秒的最佳路径。
第四,未来想象。这是最神奇的部分。你在做决策之前,会在脑海里模拟一下:如果我变道,会是什么样子?前方的车会不会突然刹车?UniDrive-WM也会生成未来几帧的画面,而且这些画面是基于规划好的轨迹生成的。
如何预测未来
UniDrive-WM探索了两种不同的图像生成方法:
方法一:离散自回归生成
这种方法将图像量化成离散的token,就像把一幅画拆解成一堆乐高积木。模型会预测下一个token是什么,类似于我们平时打字时输入法会预测下一个字。
具体做法是扩大VLM的视觉码本,让它在语言和视觉空间里都能进行多模态的下一token预测。
方法二:连续的自回归加扩散生成
这种方法结合了两种技术的优点:先用自回归方式生成连续的潜在特征,再用扩散模型进行精细的图像重建。
流匹配:一种训练生成模型的方法,类似于教模型从一团混乱的噪声逐步"流"向有序的图像。就像你在教一个人画画,先让他随意涂鸦,然后一步步修改成一幅完整的画。
扩散模型预测速度场,通过流匹配损失进行训练。为了保持语义对齐,还加入了CLIP监督,确保生成的未来图像和真实图像在语义上保持一致。
这两种方法各有优劣。自回归方法适合实时决策的场景,比如高速公路上的快速反应。自回归加扩散方法适合复杂城市环境的精细规划,需要更详细地理解未来场景。
效果到底有多好
论文在Bench2Drive数据集上进行了全面的测试,这是自动驾驶领域一个具有挑战性的基准测试。
结果令人振奋。UniDrive-WM在驾驶评分上达到了79.22,比之前的最佳方法提高了1.48个百分点。成功率达到了56.36%,比之前提升了近2个百分点。更重要的是,碰撞率比之前最佳方法降低了9.2%。
这些提升看起来可能不大,但在自动驾驶领域,每个百分点的提升都意味着更安全的驾驶体验。
评估世界模型的难题
但这里有个问题:我们怎么知道一个世界模型到底有多好?
多伦多大学研究的DrivingGen就是要解决的这样问题。
FVD(Fréchet Video Distance):一种用来衡量生成视频和真实视频之间分布距离的指标。值越小表示生成的视频越接近真实视频的分布。就像用尺子量两幅画有多相似,FVD就是用来量两个视频集合有多相似的工具。
研究人员指出,现有的评估方法有四大问题:
第一,视觉保真度评估不够全面。大多数基准测试只使用FVD这样的指标来评估视频的真实程度,但这远远不够。
第二,轨迹合理性被忽视了。在自动驾驶场景中,生成的视频不仅要看起来真实,它背后的运动轨迹也必须符合物理规律。比如说,车子不能突然从静止加速到100公里每小时,行人也不能在一秒钟内穿过整个马路。
第三,时间一致性和智能体一致性不足。很多现有方法只关注整体场景的一致性,但忽略了个体对象的一致性。比如说,视频里的一个行人走着走着突然消失了,或者换了一个完全不同的人,这显然不符合常理。
第四,运动可控性被忽略。对于自动驾驶来说,世界模型不仅要能生成视频,还要能够按照指定的轨迹生成视频。
一个全新的评估体系
为了解决上述所有问题,研究团队提出了DrivingGen这个综合基准测试。它的创新主要体现在三个方面。
首先是一个更加多样化的数据集。DrivingGen包含了400个精心挑选的视频样本,覆盖了各种天气条件(正常、雨天、雪天、雾天、洪水、沙尘暴)、不同时间(白天、夜晚、日出日落)、全球多个地区,以及复杂的驾驶场景。
长尾场景:指那些出现频率很低但对安全性影响巨大的场景。比如暴雪天气下的驾驶、深夜在乡村道路上的行驶、或者是突然有动物冲出马路的情况。
其次是全新的评估指标体系。DrivingGen引入了四类指标:分布指标、质量指标、时间一致性指标和轨迹对齐指标。
最后是大规模的模型评估。研究团队在DrivingGen上评估了14个最先进的世界模型,包括通用的视频世界模型、基于物理的世界模型和专门的驾驶世界模型。
评估结果揭示了什么
评估结果揭示了一些有趣且重要的发现。
第一个发现:闭源模型在视觉质量和整体排名上领先。像Kling和Gen-3这样的商业闭源模型在两个轨道上都占据了领先位置。这就像花钱请的专业演员,表演技巧更加精湛,不容易出错。
第二个发现:顶级开源通用世界模型在特定指标上具有竞争力。一些开源模型在个别维度上接近或匹配闭源模型的性能。这就像业余爱好者也能在某些专业领域达到甚至超越专业人士的水平。
第三个发现:没有单一模型在视觉真实度和轨迹保真度上都表现出色。目前还没有模型能够成功将强大的照片级真实感与精确的物理一致运动结合起来。这就像有些人擅长画画但不会开车,有些人开车技术好但画技一般,很难找到两者都精通的人。
第四个发现:轨迹对齐仍然有限,揭示了巨大的差距。在自车轨迹条件下,模型显示出显著的误差,表明对指定路径的遵循性很差。
让路线和速度协调起来
说完了世界模型的构建和评估,我们再来看一个具体的问题:如何让自动驾驶更好地协调横向和纵向的规划。
西交大和地平线联合研究的AlignDrive关注的就是是这样一个问题:当你准备在路口右转,对面有车直行过来,你会怎么做。
你的大脑其实在做两件事:一是决定走哪条路线,二是决定开多快。但关键是,这两个决定不是独立的。你看到对面的车,就会想"那我得慢点让它先过",路线和速度是紧密配合的。
这听起来很简单,但对自动驾驶来说却是个大难题。
最先进的端到端模型通常把规划任务分成两个并行的分支:横向规划负责预测行驶路线,纵向规划负责预测速度轨迹。看起来挺合理的,分工明确嘛。
但问题来了。试想一下,如果横向分支预测说"前面要急转弯",但纵向分支说"保持高速行驶",这两个预测之间没有约束,最后组合起来可能就是要命的结果。
更麻烦的是,纵向分支在预测速度时,又要重新编码一遍道路几何、车道结构这些静态信息。但这些东西横向分支已经处理过了啊。这不就是重复劳动吗。
一个简单的想法
AlignDrive的核心思想其实特别朴素。既然横向路线已经确定了"走哪条路",那纵向规划为什么不直接基于这条路线来决定"开多快"呢。
一维位移预测:不直接预测车辆在每个时刻的二维坐标,而是预测沿着预定路线在固定时间间隔内前进的距离。就像高铁不告诉你每刻的经纬度,只告诉你"每小时行进300公里"。
具体来说,作者提出了一个级联框架,让纵向规划明确地依赖于预测出来的行驶路线。
这有什么好处呢?
首先,纵向推理变得简单多了。模型不需要再操心"往左还是往右"这种横向变化,只需要专注于"该加速还是减速"。
其次,这种设计天然就保证了横向和纵向的一致性。因为纵向预测本来就是基于路线的,不可能出现"路线要求急转弯但速度要求高速"这种矛盾的情况。
最重要的是,这种简化让模型能把更多注意力放在动态交互上,比如前面的车会不会突然切入,行人会不会横穿马路。
效果到底有多好
作者在Bench2Drive基准测试上进行了全面评估。AlignDrive在所有主要指标上都达到了最先进水平。驾驶分数89.07,成功率73.18%,都是最高的。
但更值得关注的是碰撞率的下降。变体A是传统的并行设计,横向和纵向独立预测,碰撞率22.7%。变体C加入了路线条件,纵向规划基于路线进行预测,碰撞率降到16.3%,下降了28.2%。
然后加上专门的数据增强策略,碰撞率进一步降到11.4%。这比原始设计降低了一半啊。
深层次的思考
这三项研究带来的最大感受是:统一认知框架比分散的模块更有力量。
传统的工程思维是把复杂问题分解成小问题,每个小问题由专门的模块解决。但真正的智能可能需要的是一种全局的、统一的认知框架。
就像一个优秀的篮球运动员,不是只会运球、传球或投篮,而是能在瞬间同时完成观察、判断和行动。UniDrive-WM试图让自动驾驶系统也达到这种境界。
从分散到统一,从单一模态到多模态联合,从被动预测到主动生成,这些论文为我们指明了一个值得探索的方向。
生成即理解
还有一个有趣的发现:生成未来图像不仅是为了好看,更重要的是它反过来帮助系统更好地理解当前场景。
这有点像我们在学习新知识时,如果能够用自己的话重新讲述一遍,理解会更深刻。生成未来图像的过程,实际上就是系统在"重新讲述"它对场景的理解。
人类最强大的能力之一是"视觉想象"——在脑海里预演可能的未来。这种能力帮助我们做出更好的决策。
比如,你在决定要不要超车之前,会先想象一下:如果我变道,旁边的车会不会也同时变道?前方会不会突然有障碍物?
UniDrive-WM、DrivingGen和AlignDrive这些工作,都在尝试让自动驾驶系统也具备这种"视觉想象"能力。这不是简单的轨迹预测,而是真正的场景级未来可视化。
***
学过车的人都知道,教练说开车要"眼观六路,耳听八方",但最重要的还是"预判"。看到前面的车减速,你就该收油了,看到路口有人,你就该备刹车了。
这种预判能力,本质上是把感知到的信息和即将采取的动作紧密联系起来。不是看到路况再查表决定怎么做,而是看到路况就知道该怎么做。
这些研究试图给AI赋予的,正是这种能力。让AI不盲目地预测,而是基于统一的认知框架,根据对场景的理解做出合理的决策。这更接近人类的驾驶直觉。
当然,这条路还很漫长。但它们让我们看到了一个正确的方向:不是让AI记住更多的驾驶规则,而是让它理解感知、预测和规划之间的内在联系,学会像人一样"看见未来"。
或许有一天,当我们坐进自动驾驶汽车,发现它能像老司机一样,在不经意间避开危险,平稳地送我们到达目的地时,我们会想起这些研究,想起那些让AI学会统一认知、看见未来的研究者们。
技术进步的步伐,就是这样一步一步走出来的。