长安汽车自动驾驶数据分析实战:从场景识别到风险评估
- 2026-06-21 22:47:56


作者简介:梁理智,Fintech 行业解决方案专家,主攻深度学习。和大多数程序员一样,他是个乐观主义者,大量的时间都在调试代码,在调试中满怀希望,克服遇到的无数挫折。
摘要:随着自动驾驶技术的飞速发展,如何利用海量驾驶数据理解和评估复杂的交通场景,成为保障行车安全的核心挑战。本文将以长安汽车“全球华人大学生数据应用创新赛”的真实赛题为例,完整复现实战项目,深入探讨如何利用Python对智能驾驶数据进行处理、分析与可视化,最终实现驾驶场景的自动识别、复杂度建模与风险评估。
一、项目背景与赛题解读
自动驾驶系统需要在千变万化的道路环境中做出精准决策,而这一切的基础是对当前驾驶场景的深刻理解。本次实战项目的数据与课题来源于“2022全球华人大学生数据应用创新赛”,该赛题聚焦于如何利用车辆的传感器数据和高精度地图信息,对复杂的驾驶场景进行分析。
 图1:赛题核心任务——可视化、分类、复杂度和交通事故概率预测
图1:赛题核心任务——可视化、分类、复杂度和交通事故概率预测
根据赛题要求,核心任务主要包含以下三个层面:
驾驶场景分类:对超过10种典型的驾驶场景进行有效分类,例如区分“城市道路”与“高速公路”,并进一步识别出“变道”、“超车”、“路口”等具体行为。 场景复杂度建模:基于场景内的动态(行人、车辆)和静态(道路曲率、坡度)信息,构建一个能够量化场景复杂程度的数学模型。 场景危险程度评估:结合场景复杂度和驾驶行为数据,最终评估在不同场景下发生交通事故的潜在概率,并找出影响驾驶性能的关键因素。
这些任务共同构成了一个从数据感知到风险决策的完整闭环,是实现L3/L4级别自动驾驶的关键技术之一。
二、数据探索与预处理
项目的起点是理解和处理原始数据。本次使用的数据是一系列CSV文件,每个文件记录了一段连续驾驶过程中的多维度信息。数据字段繁多,关键信息主要包括自车状态、目标物体信息、车道线信息和高精度地图(HD Map)等。
数据处理过程中最大的挑战在于,许多关键字段是以JSON格式的字符串嵌套在CSV单元格中的,需要进行复杂的解析才能提取出结构化信息。以下是使用Pandas库读取并初步解析数据的Python代码示例:
import pandas as pdimport json# 读取包含驾驶数据的CSV文件file_path = '1659428125.53_1659428167.45.csv'df = pd.read_csv(file_path)# 数据解析函数示例:处理高精度地图信息defparse_hdmap_data(row):try:# 将字符串转换为Python对象 hdmap_str = row['link_list/hdmap']# 此处仅为示意,实际解析过程更复杂 hdmap_data = json.loads(cleaned_hdmap_str) road_type = hdmap_data['links_0']['type']return road_typeexcept (TypeError, json.JSONDecodeError):returnNone# df['road_type'] = df.apply(parse_hdmap_data, axis=1)这个预处理步骤是整个项目中最耗时但也是最关键的一环。通过对原始数据的结构化提取,我们将非结构化的数据转化为了可供分析的特征矩阵。
三、驾驶场景识别与分类
完成数据预处理后,便可以开始进行场景识别。根据项目报告中的分类体系,驾驶场景首先被划分为城区道路和高速公路两大类,再通过具体的特征组合来识别更细分的子场景。
 图2:驾驶场景分类——城区道路与高速公路下的子场景划分
图2:驾驶场景分类——城区道路与高速公路下的子场景划分
实现分类的核心思路是基于规则和关键字识别。例如,通过高精度地图中的type字段和车辆的speed_limit_value来区分高速公路和城区道路。下图展示了详细的技术路线。
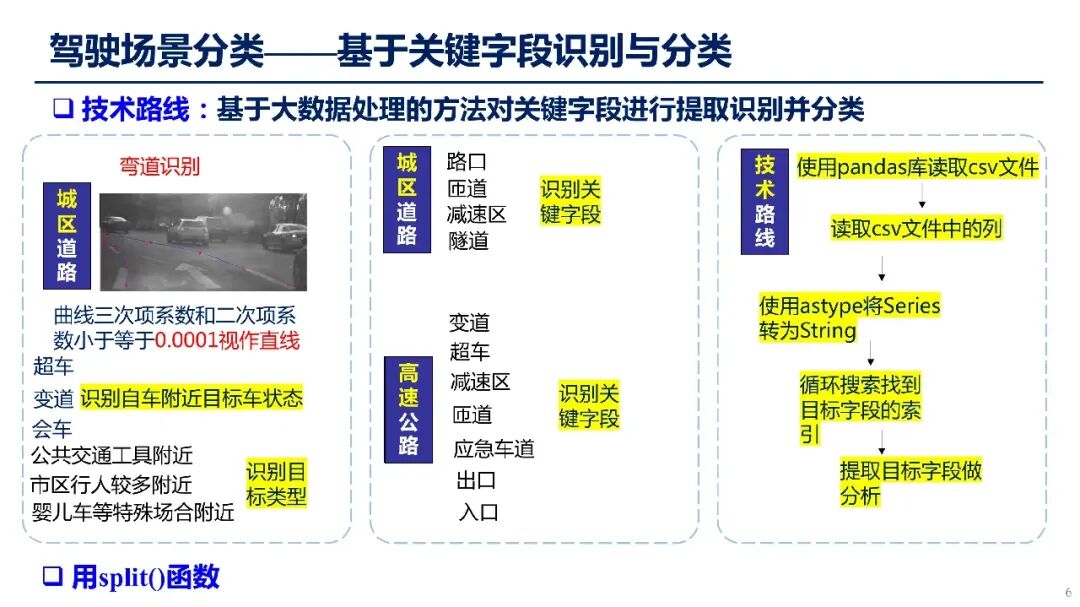 图3:基于关键字识别的场景分类技术路线
图3:基于关键字识别的场景分类技术路线
以下是一个简化的场景分类逻辑示例:
defclassify_driving_scene(row): speed = row['velocity'] road_type = row['road_type'] # 假设已从HD Map解析if road_type in ['highway', 'expressway'] or speed > 80: primary_scene = '高速公路'else: primary_scene = '城区道路'if row.get('is_at_intersection'):returnf"{primary_scene} - 路口"if row.get('is_changing_lanes'):returnf"{primary_scene} - 变道"return primary_scene四、场景复杂度与风险评估
场景识别之后,我们需要量化每个场景的“复杂”与“危险”程度。这通常通过构建一个综合评分模型来实现。
1. 场景复杂度模型
场景复杂度由多个维度的指标加权构成。根据项目报告的思路,场景总复杂度fc(S)是车辆状态复杂度fc(I)、道路复杂度fk(K)和环境复杂度fo(D)的加权和。
 图4:场景复杂度模型的数学定义与指标构成
图4:场景复杂度模型的数学定义与指标构成
复杂度C的计算公式为:
C = w_i * f_c(I) + w_k * f_k(K) + w_d * f_o(D)
其中 w 是权重,f 是归一化后的各项复杂度指标。
2. 场景复杂度计算
具体的计算流程如下图所示,通过对目标字段的提取、归一化处理,并结合时间序列分析,最终得到每个时刻的场景复杂度得分。
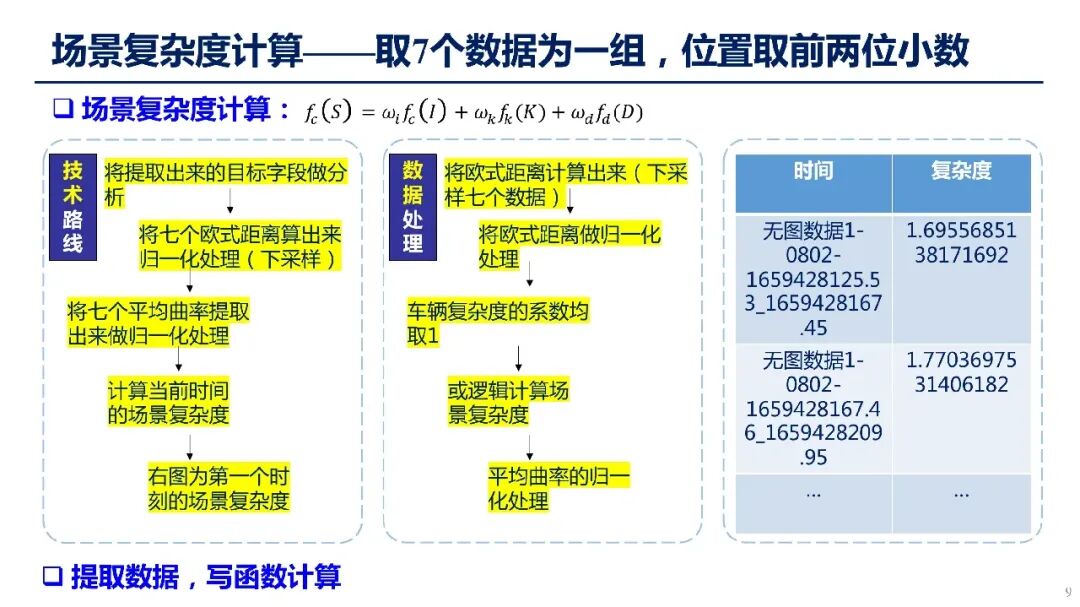 图5:场景复杂度的具体计算流程与技术路线
图5:场景复杂度的具体计算流程与技术路线
五、可视化分析与结论
数据分析的价值最终需要通过清晰的可视化来呈现。我们可以利用Matplotlib和Seaborn等库,从多个维度进行可视化探索。
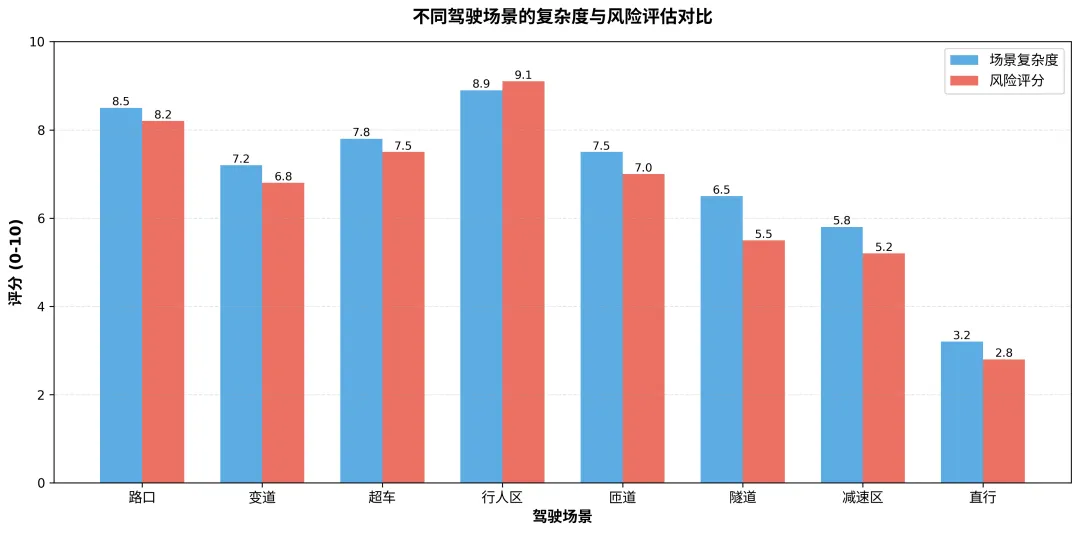 图6:不同驾驶场景的复杂度与风险评分对比,可以看出“行人区”和“路口”是挑战最大的场景
图6:不同驾驶场景的复杂度与风险评分对比,可以看出“行人区”和“路口”是挑战最大的场景
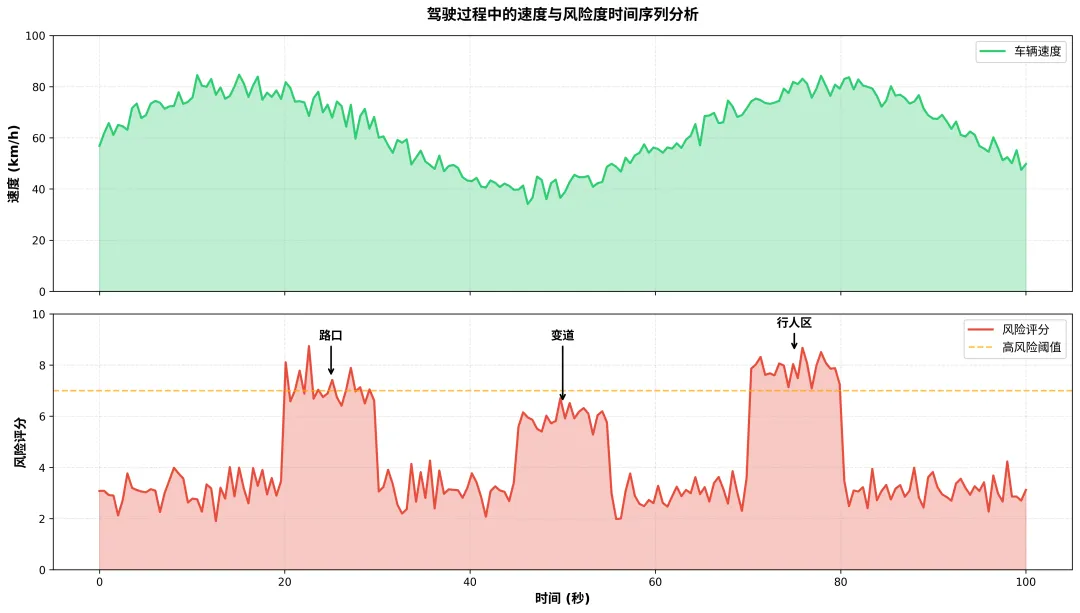 图7:将速度与风险度在时间轴上对齐,可以清晰地看到车辆在进入“路口”、“变道”等高风险场景时风险指数的显著变化
图7:将速度与风险度在时间轴上对齐,可以清晰地看到车辆在进入“路口”、“变道”等高风险场景时风险指数的显著变化
通过这些可视化图表,我们可以得出结论:
关键场景识别:高速公路的“匝道”区域、城市道路的“路口”和“行人密集区”是复杂度和风险度最高的场景。 关键影响因素:影响驾驶风险的关键因素不仅包括自车速度,还包括周围目标的数量、动态变化以及道路的几何特征。 模型应用价值:本研究构建的场景识别与风险评估模型,可以为自动驾驶系统的决策规划模块提供关键输入,从而有效提升行车安全。
六、总结与展望
本文通过一个完整的实战案例,展示了如何从原始的智能驾驶数据出发,经过数据处理、特征工程、场景分类、模型构建和可视化分析,最终提炼出对自动驾驶安全有价值的洞见。这个流程不仅体现了数据科学在汽车行业的核心应用,也为处理类似的多维时序数据问题提供了一套行之有效的方法论。
如果需要完整数据及代码,请后台回复【data】后联系云朵君即可获取!

🏴☠️宝藏级🏴☠️ 原创公众号『数据STUDIO』内容超级硬核。公众号以Python为核心语言,垂直于数据科学领域,包括可戳👉Python|MySQL|数据分析|数据可视化|机器学习与数据挖掘|爬虫等,从入门到进阶!
长按👇关注- 数据STUDIO -设为星标,干货速递

随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 智能驾驶王炸!上海印发高级别自动驾驶模速智行行动计划名单更新
- 8万韩系合资轿车!比德日系配置高,比国产车更可靠
- 从L2到L4:自动驾驶技术到底靠不靠谱?一文看懂分级与核心原理!
- 2025年自动驾驶十大关键标准
- 全球第一!公认的豪华轿车,外观更像红旗H9,拥有30万档次仅售13万多
- 代码掌舵,雨雾迷途︱当方向盘交给算法:自动驾驶是更安全,还是更危险 (两则)
- 5万起开大厂轿车!高保值好保养,买了不后悔的刚需神车
- 文献研读 | 自动驾驶汽车异常驾驶行为引发的驾驶愤怒效应
- 一句话点评12月及全年紧凑型轿车:轩逸再次夺冠,大众坚守阵地
- KONI车型案例分享:轿车系列 MINI F56
