
Vision vs LiDAR
在自动驾驶领域,一直存在着“纯视觉”与“融合感知(激光雷达 + 地图)”的路线之争。许多人认为增加一种传感器(激光雷达)就是增加了一份安全冗余。然而,以特斯拉为代表的纯视觉派却坚信:激光雷达虽然让“起步”容易,但会限制系统的“上限”;只有纯视觉方案,才能通往真正的通用自动驾驶 (AGI of Driving)。
本文将从技术实现原理和理论上限两个维度,深入探讨这个问题。
一、 基于视频的纯视觉方案是怎么实现的?
早期的摄像头方案只是简单的物体检测(画框),但现代的纯视觉自动驾驶(如 Tesla FSD V14)已经进化为一套复杂的深度学习系统。
1. 感知层:从 2D 到 3D 的飞跃 (BEV + Transformer)
传统的视觉算法是在每一帧 2D 图像上画框(Object Detection),不仅无法准确判断距离,而且多个摄像头之间的数据是割裂的。现代方案引入了 BEV (Bird’s Eye View,鸟瞰图) 技术,结合 Transformer 强大的特征提取能力:
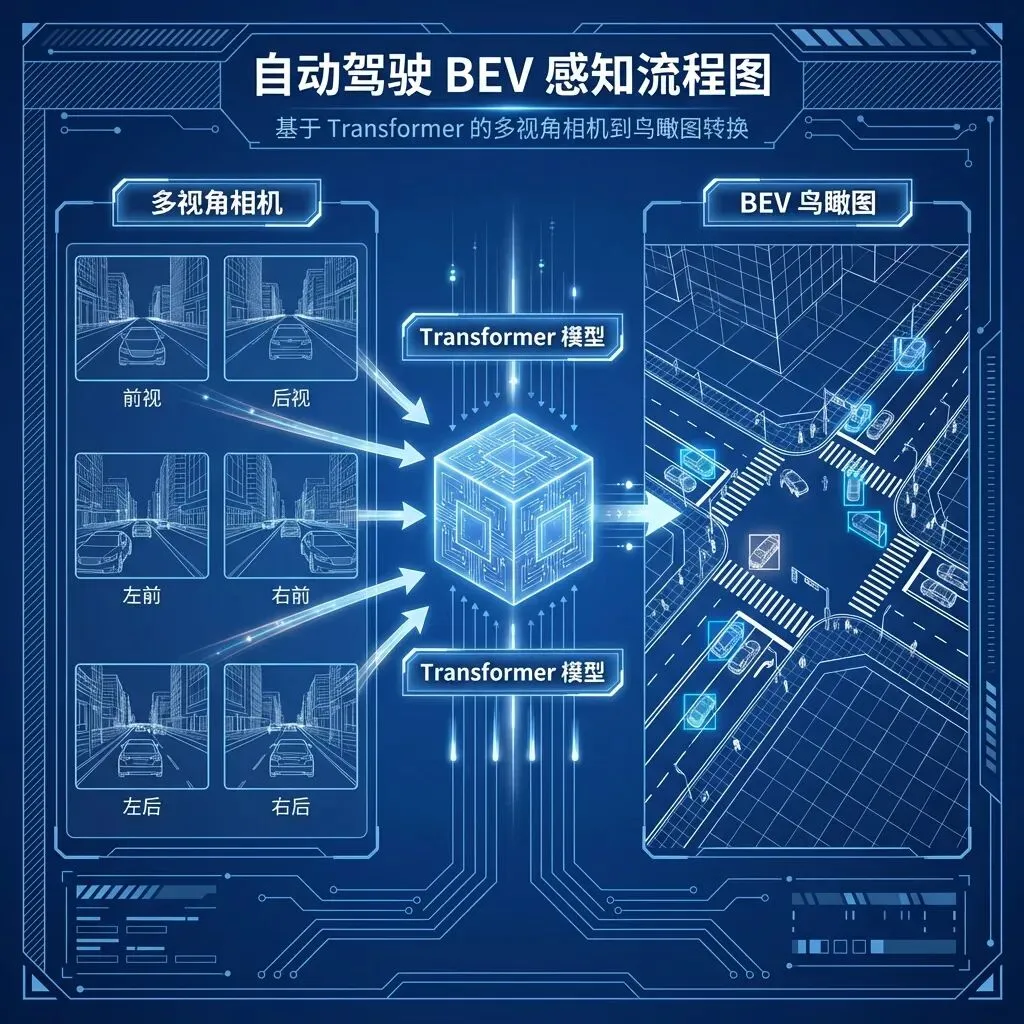
BEV Perception Diagram
•多视角融合:车辆周身 8 个摄像头的视频流被同时送入神经网络。
•空间变换 (View Transformation):利用 Transformer 的注意力机制(Attention Mechanism),系统将不同角度的 2D 图像特征投影到一个统一的 3D 向量空间(3D Vector Space)。
•上帝视角:这就像是 AI 在脑海中拼出了周围环境的 3D 模型。在这个坐标系下,车辆不再是看着一张张图片,而是拥有了像玩实况足球游戏一样的“上帝视角”。
•时序融合 (Temporal Fusion):人类开车不仅仅看“现在”,还记得“过去”。系统通过 Video Module 记忆过去几秒的特征,从而极高精度地推断物体的速度、加速度,甚至能“脑补”出被短时间遮挡的物体。
2. 世界模型:占用网络 (Occupancy Network)
激光雷达之所以受欢迎,是因为它能精确测量“这里有个东西”。纯视觉以前很难处理“未见过的障碍物”(比如路面上侧翻的白色卡车、奇怪形状的落石)。
占用网络 (Occupancy Network) 的出现彻底改变了这一局面。

Occupancy Network Visualization
•不识别,只避让:它不再试图“识别”物体具体是什么(是红色的轿车还是绿色的树),而是将 3D 世界划分为无数个微小的体素 (Voxel)——这就好比《我的世界》(Minecraft) 里的方块。
•通用障碍物检测 (GOD):系统只需要判断每个体素是“被占用 (Occupied)”还是“空闲 (Free)”。如果推算出前方空间的体素被占用,哪怕 AI 用生以来从未见过这种东西(比如一架降落的外星飞船),它也会坚决地选择避让。这直接拉齐了视觉方案与激光雷达在通用避障能力上的差距。
3. 决策层:端到端 (End-to-End)
最前沿的纯视觉方案(如 Tesla FSD V12+)正在掀起一场“软件 2.0”革命,它抛弃了人类编写的传统的“规则代码”(如:if 红灯 then 停车),转向完全由数据驱动的端到端神经网络。
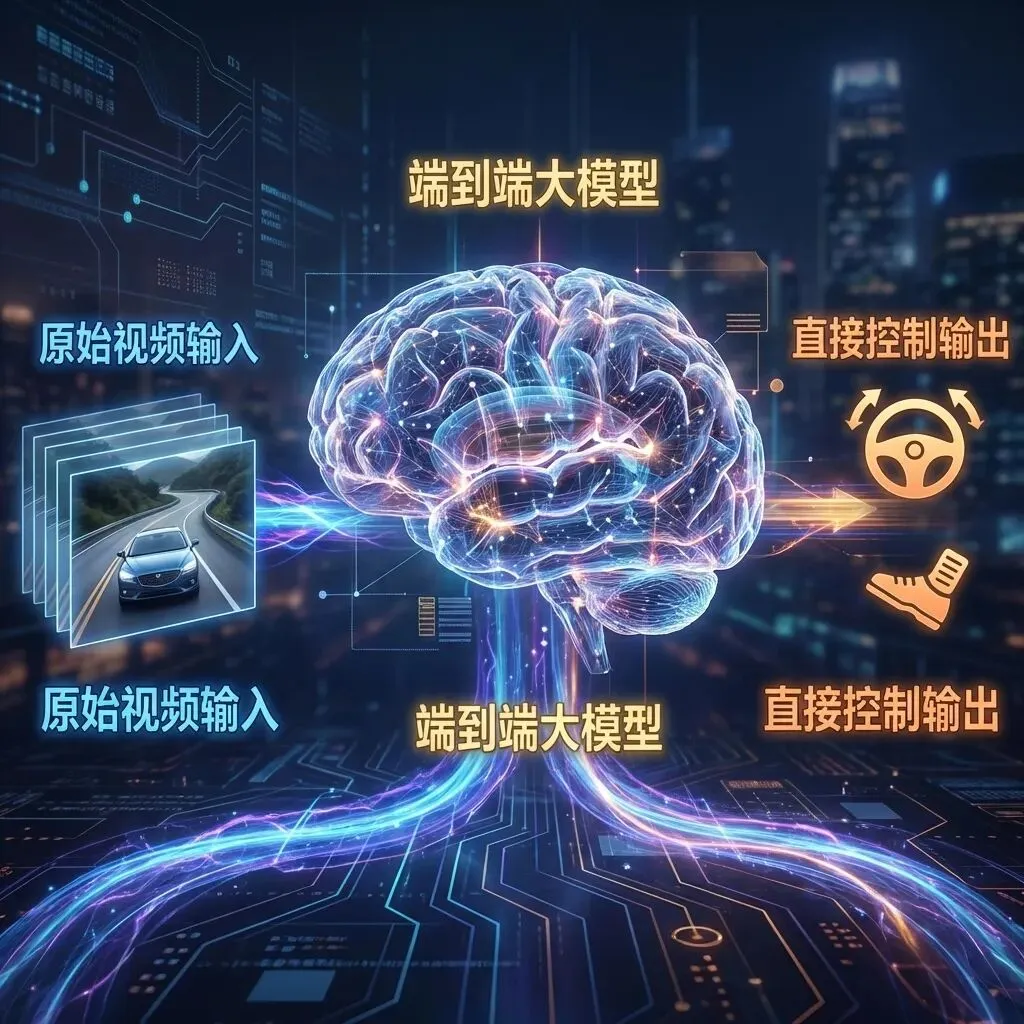
End-to-End Architecture
•光子输入 -> 控制输出:中间不再有人工设计的“感知”、“融合”、“规划”、“控制”等模块的生硬切割。整个自动驾驶软件就像一个巨大的大脑。
•视频流进,指令流出:你喂给它海量的视频数据,它输出方向盘转角和油门刹车信号。
•拟人化博弈:它通过学习数百万人类老司机的驾驶视频,不仅学会了遵守交通规则,更学会了人类细腻的“博弈”和“体感”。比如在拥堵的无保护左转路口,它不再是傻傻地等待绝对安全,而是会像人一样一点点“挤”出空间,顺滑地融入车流。这种能力是写死规则的代码永远无法实现的。

二、 为什么说纯视觉方案的“上限”更高?
激光雷达(LiDAR)方案本质上是在追求“局部最优解”,而纯视觉方案虽然早期更难,但它是在追求“全局最优解”。
1. 信息密度的降维打击
•激光雷达是“盲人摸象”:LiDAR 只能获取物体的几何形状(点云),它不仅稀疏,而且丢失了最关键的语义信息。它分不清路边的一块石头和一个黑色的塑料袋,分不清前面的红灯是圆的还是箭头的,也看不懂交警的手势。
•视觉是全量信息:摄像头捕捉的光子包含了颜色、纹理、文字、灯光等极其丰富的信息。在复杂的交通环境中,语义(Semantics)往往比几何(Geometry)更重要。
–例子:前方路面有一块深色的补丁。激光雷达会测出它是平的,认为“可通行”。但视觉可以通过纹理判断出那是由于刚下过雨的湿滑积水,或者是新铺的沥青,从而做出更细腻的减速决策。

LiDAR vs Vision Puddle
2. 数据的马太效应与 Scaling Laws
人工智能的进化依赖于数据规模。
•数据量级差异:搭载激光雷达的测试车队通常只有几千辆,成本高昂,数据采集范围有限。而特斯拉等纯视觉车型已经在全球拥有数百万辆量产车,每天通过“影子模式”收集海量的高质量驾驶数据。
•大模型的涌现能力:以 GPT 为代表的大语言模型证明了 Scaling Laws (缩放定律)——当数据量和算力达到一定阈值,模型会涌现出惊人的智能。纯视觉方案本质上是在训练一个“驾驶界的 GPT”,数据越多,它处理极端场景(Corner Cases)的能力就越强。激光雷达方案由于其数据稀缺性,很难触达这个临界点。
3. 人类世界的适配性
我们的道路系统(车道线、红绿灯、路牌、转向灯)完全是为人类的视觉系统设计的。
•如果我们要制造一个在人类世界运作的机器人,最合理的传感器就是模仿人类的眼睛。
•图灵测试:如果人类可以仅靠视觉安全驾驶,那么理论上 AI 也可以。不仅如此,AI 拥有 360 度无死角视野和永不疲劳的注意力,其视觉能力的上限远超人类。
4. 泛化能力的本质
依赖 高精地图 + 激光雷达 的方案,本质上是在跑“固定轨道”。一旦现在的路况与地图不符(例如临时修路、改道),系统就会降级甚至通过。
纯视觉方案训练的是“通用的认知能力”。就像人类司机到了一个陌生的城市,虽然不认识路,但依然可以用眼睛看清路况安全驾驶。这种泛化能力 (Generalization) 才是自动驾驶皇冠上的明珠,是通往 L4/L5 的必经之路。
结语
激光雷达像是一根精密的“导盲杖”,它能让自动驾驶系统在初期快速达到 99% 的安全性。但要解决最后那 1% 的极端难题(Long-tail cases),要让车真正像人一样理解复杂的物理世界,我们最终还得扔掉拐杖,睁开慧眼。
纯视觉不仅是降本的手段,更是通向通用人工智能 (AGI) 的信仰。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
