大家好,我是绚丽。
今天这个话题有点不一样,咱不聊.车外观,也.不.聊驾驶感受。
我们聊聊一个最近被各大车企挂在.嘴边的词——Transformer。
不是.变形.金刚那.个啊,是AI世.界里的一个狠角色。它现在正在让自.动驾驶变得更聪明、更.像人.在开车那种感觉。
我今天就想用咱普通人的理解方式,聊一聊这玩意到底改变了啥。

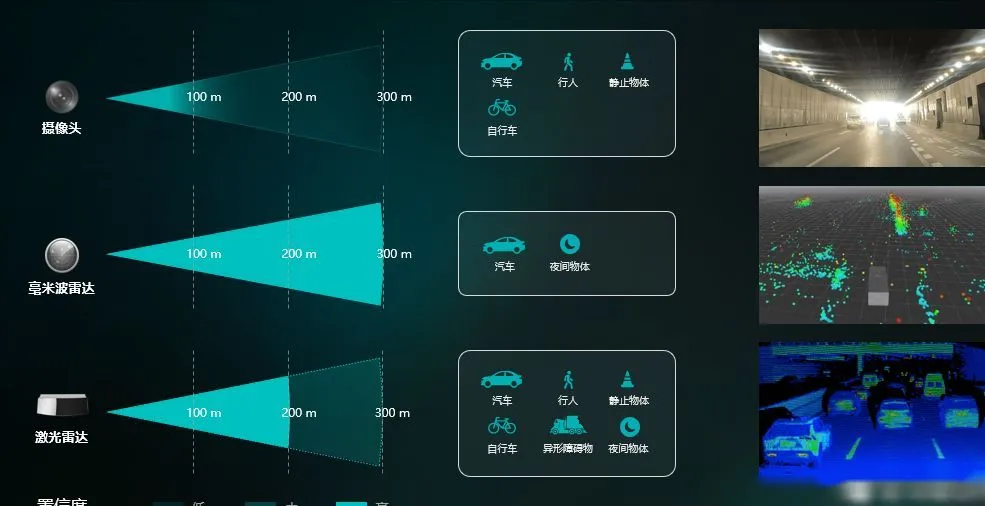
先说最直观.的变.化,就是车.变.得更“会看”了。
以前的自动驾驶更多靠摄像头和雷达“各扫各的门前雪”,识.别的东西.都挺.碎片化。
现.在加上Transformer之后,它能把这些信号“串”起来理解.整.个场.景。
比如前.面.那个.电动车突然变道,它能联想之前几秒的动作,而不是傻傻.地看一帧画面。
这个我试过,有次试.驾理想的城.市NOA,感受特别明显。
你能感觉到它提前“预判”了拥堵车流.的节奏,那种顺滑感.就出来了。
然后.就是BEV+Transformer这.个.组合拳。BEV是鸟瞰.图视.角,Transformer主要干的是“理解.关系”。
以前算法容易漏判,比如电动车旁边有行.人但.被.遮挡。
现在它能“脑补”出那个.人还在,还在走路。这就是那种从一个点.看全.局的.感觉。
其.实这事就像开车.过.丁字路口,如果你只盯前面,肯定会紧张,但要能脑子里“构图”,你就能判断哪边安全。
说到这.儿,得聊.聊另.一个我觉得挺酷的——端.到端大模型。啥.意思.呢?
以前那一套自.动驾.驶系统分好多个模块,感知、预测、规划,全靠“接力棒”传.递。
可.每一.棒之间信息.都要压缩一次,带来.延迟。
Transformer的思路不.一样,它直接一锅炒,把所有.信息放在一张大图里学习,这样反.应.就快多了。
特斯拉.那套世界.模型就是这么干.的,他们在去年CVPR上展示的成果,真有点意.思。
我看过.那种实时视频,它能自动理.解红绿灯、路.标、行人甚至阴影。
这种语义层理解,真的是靠Transformer的“全局注意力”搞出来的。
不过Transformer也不.是完.美的,这.东.西对数据的依赖太大。
你想想它要吃多少.视频、多少路况样本才有今天这水平,光算力就.是天文数.字。
特.斯拉、小鹏、华为.这些厂在烧的.都是GPU的钱。
我个人还是挺希望国产能早日降本的,现在城市NOA能下放.到十来万的.车上,已经说明一个趋势:
智驾平.权,真.的在到来。

再有.一点特别关键,Transformer在处理时序信息这块.太强.了。
举个例子,以前那种跟踪算法,一旦被遮挡几帧就挂.球了。
现在.它能“想起来”这个.目标之前在干什么、现在可能去哪,等于实现了那.种人脑式预测。
就好比你开.车在西.安二环,看到前方那.辆面包车往右探头了,你潜意识就知道它要并线。
这其实.就是Transformer在模仿的东西——时间上的连续推理。
最后简单总结一下吧,我觉得Transformer这波.真.的彻底改变了自动驾驶的逻辑。
从“看得见”变成了“看得懂”,再往后可能.就是“会判断”。
当然现.在它还只是聪明.助手,离完.全放手还早。
要真.达到.那种你在手机上选个目的地.然后车自己带你去哪的阶段,还得再磨几年。
但趋势已经.很明显了——算法.越来越.像人、决策越来越自然。
行,今.天就聊.到这.儿。这个话题我感觉.咱可以后面再开一期,说.说现在端到端.智驾的体验和落地细节,还有不少坑可以挖。
一如.既往,文章写作不易,还.望大家多多支持,点赞评论收藏一下,感谢大.家!
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
