破解端到端自动驾驶长时程规划难题,高通提出GeRo新范式:语言引导的生成式推演
- 2026-07-02 19:42:39

近期自动驾驶的一大趋势,未来的自动驾驶汽车可能不只是被动地“模仿”人类驾驶,而是能像我们一样,在脑中“预演”或“脑补”接下来几秒钟可能发生的各种路况,然后做出最优决策。
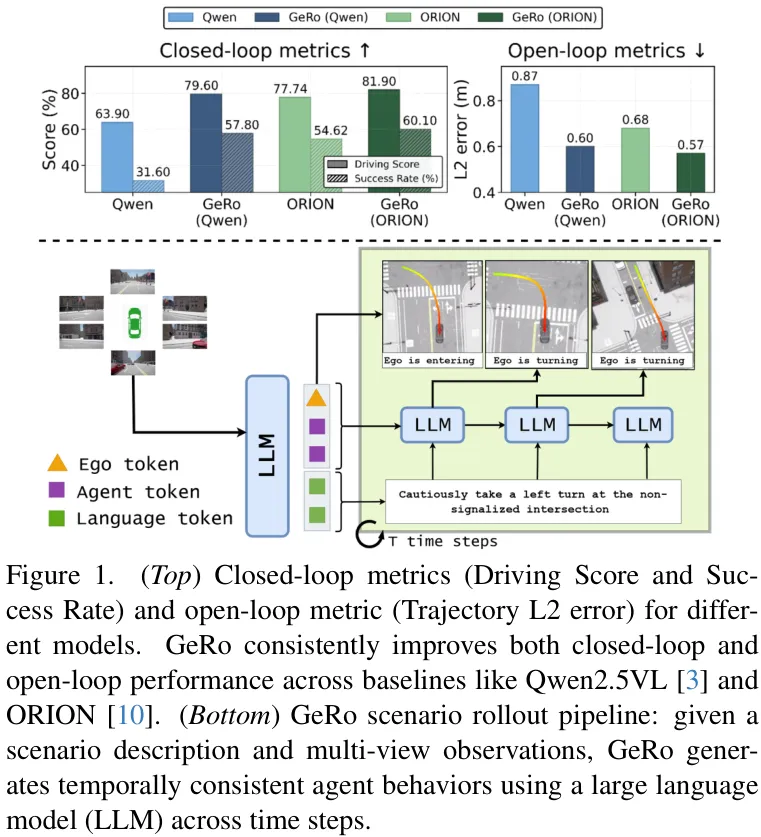
来自高通AI研究院的最新研究 GeRo (Generative Scenario Rollouts) ,就朝着这个方向又迈出了一步。他们提出了一种全新的“生成式场景推演”框架,让自动驾驶模型(特别是VLA,视觉-语言-动作大模型)不再仅仅依赖于稀疏的驾驶数据进行模仿,而是学会了主动生成和规划未来。效果非常惊人,在Bench2Drive基准测试上,驾驶得分(DS)和成功率(SR)分别实现了15.7和26.2的大幅提升!

论文名称: Generative Scenario Rollouts for End-to-End Autonomous Driving 机构: 高通 论文地址: https://arxiv.org/abs/2601.11475
背景与动机:当前VLA模型的瓶颈
近年来,以大模型为基础的视觉-语言-动作(VLA)模型在自动驾驶领域备受瞩目,它们能够理解复杂的交通场景和人类指令。然而,现有方法普遍存在几个核心痛点:
监督信号稀疏:模型训练严重依赖带有语言标注的驾驶轨迹数据,但这些数据往往是场景级别的,缺少对驾驶行为(如“超车”和“并道”)在时间维度上的细粒度描述,导致模型在面对模棱两可的场景时表现脆弱。 生成能力浪费:目前的VLA模型大多只被用作一个“规划器”,根据当前输入预测一个轨迹就完事了,其强大的自回归“生成”潜力被远远低估。 语言与动作脱节:很多数据集中的语言描述是在驾驶行为发生后标注的,导致模型可能更多地依赖视觉线索,而忽略了语言指令的真正内涵。
为了解决这些问题,GeRo被设计为一个即插即用的增强框架,其核心思想是:让模型在规划时,先在脑中(潜在空间)进行一场关于未来的“情景喜剧”排演。
方法详解:GeRo的两阶段“修炼法”
GeRo的实现分为两个关键阶段:预训练和自回归场景推演。
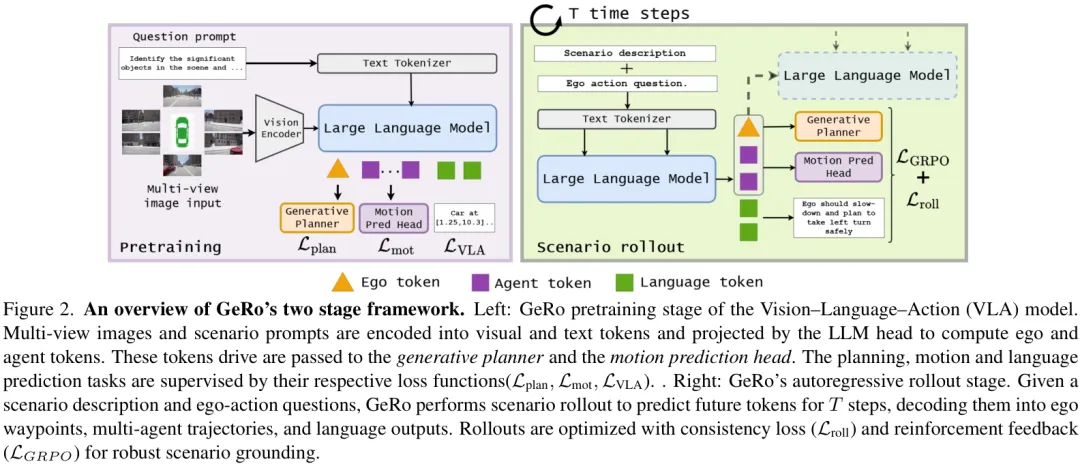
第一阶段:预训练 (Pretraining)
这就像是给演员(VLA模型)打基础。在这个阶段,模型会学习如何将复杂的外部世界(多视角图像、场景描述)压缩成简洁而信息丰富的潜在Token。
输入 (Input):多视角摄像头图像、关于场景的文本提示(Prompt)。 处理过程:图像和文本分别通过编码器转换成Token,然后送入LLM头,最终生成代表自车(ego)和周围其他交通参与者(agent)动态的潜在Token。 输出 (Output):一系列紧凑的“ego-token”和“agent-token”。 监督:这个过程受到三个任务的联合监督:规划损失( L_plan,预测的轨迹要准)、运动预测损失(L_mot,预测其他车辆的轨迹要准)和语言任务损失(L_VLA,能正确回答关于场景的问题)。
通过这个阶段,模型就学会了如何将视觉、语言和行为绑定在一个统一的、高质量的潜在空间里。
第二阶段:自回归场景推演 (Autoregressive Scenario Rollout)
这是GeRo的精髓所在,也是它被称为“生成式”的原因。模型将利用第一阶段学到的能力,在潜在空间中进行一场关于未来的“头脑风暴”。
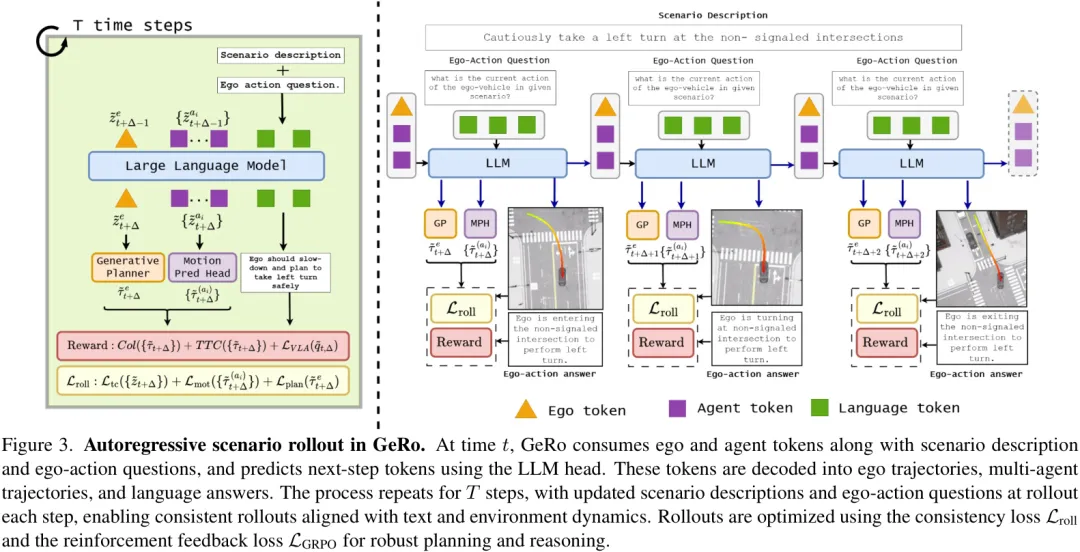
输入 (Input):当前时刻的潜在Token z_t、场景描述、以及关于自车行为的问题(例如,“我下一步应该做什么?”)。处理过程 (Autoregressive Rollout): LLM根据当前输入,预测出下一时刻( t+1)的潜在Tokenz̃_{t+1}和对应的文本回答。这个新生成的 z̃_{t+1}会被重新作为输入,送回LLM,去预测再下一时刻(t+2)的潜在Tokenz̃_{t+2}。这个过程不断重复(rollout),持续 T个步骤,从而在潜在空间中生成一整段连贯的未来场景序列。输出 (Output):一段长时程的未来预测,解码后可以得到自车未来几秒的行驶路径、周围车辆的运动轨迹,以及模型对自身行为的连续文本解释。
你可能会问,这种“脑补”不会越想越离谱,最后产生完全不切实际的规划吗?这就是GeRo最巧妙的两个设计:
推演一致性损失 ( L_roll):为了防止推演过程“放飞自我”,研究者引入了一致性损失。它通过计算KL散度,确保模型在推演时生成的潜在Token分布,与预训练阶段看到的真实Token分布保持一致。这就像一根绳子,时刻把模型的“想象”拉回到现实的轨道上。基于GRPO的强化学习 ( L_GRPO):模仿学习只能让模型达到人类驾驶员的平均水平,但要处理紧急避险等长尾场景,还需要“更优”的策略。因此,GeRo引入了强化学习。在推演过程中,如果预测的轨迹导致碰撞或危险(如TTC,碰撞时间过短),模型就会收到一个“惩罚”信号。反之,安全、高效的轨迹则会得到“奖励”。通过这种方式,模型学会在推演时主动规避风险,生成更安全的驾驶策略。
实验与结果:性能大幅提升
GeRo的强大效果在Bench2Drive和nuScenes两大自动驾驶基准上得到了验证。
闭环性能惊艳
在更考验真实能力的闭环测试中,GeRo展现了巨大的优势。
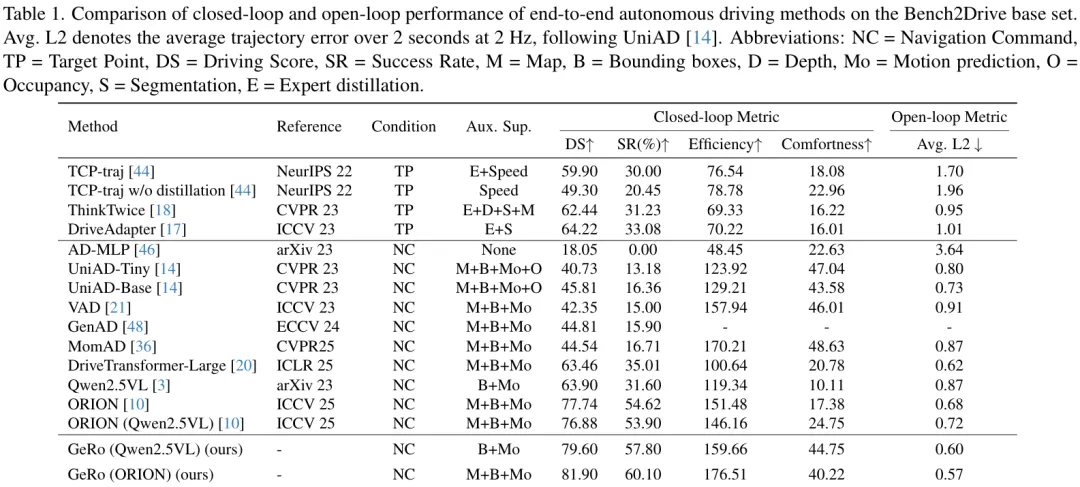
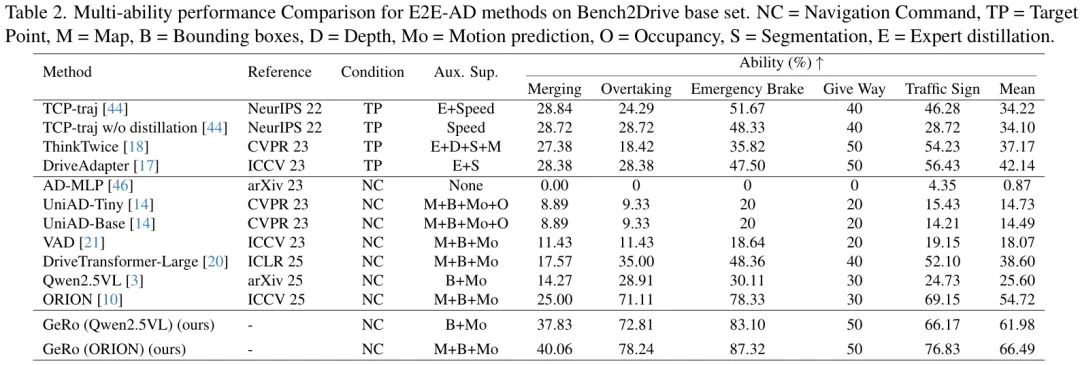
从上表中我们可以清晰地看到,GeRo作为一个“增强插件”,无论是应用在Qwen2.5VL还是ORION模型上,都带来了显著的性能提升。摘要中提到的惊人数据正来源于此:
将GeRo应用于Qwen2.5VL模型上时( GeRo (Qwen2.5VL)),相比于原始的Qwen2.5VL基线:驾驶得分 (DS) 从63.90提升到79.60,净增15.7分。 成功率 (SR) 从31.60%提升到57.80%,净增26.2个百分点。 当应用于更强的ORION模型时, GeRo (ORION)更是将驾驶得分推高到了 81.90,在所有对比方法中取得了SOTA的成绩。
在更细分的能力评估中,GeRo同样表现出色,在并道、超车、紧急制动等复杂城市场景中的平均分达到了 66.49,远超其他方法。
定性结果:更像人类的思考方式
除了冷冰冰的数字,GeRo生成的定性结果更让人印象深刻。

上图展示了两个真实的驾驶场景:
顶部场景:在有STOP标志和行人的十字路口,GeRo不仅正确地减速、让行,还生成了连贯的文本解释:“The ego vehicle is yielding to a pedestrian... then making a safe left turn.”(自车正在给行人让路...然后安全左转。) 底部场景:在恶劣天气下处理前方事故,模型能够主动检测危险、规划变道,并平稳地汇入车流,同时解释自己的行为。
这种图文并茂、时序连贯的“内心独白”,极大地增强了自动驾驶系统的可解释性和透明度,让我们能更好地理解AI的决策逻辑。
写在最后
这篇论文的结果还是蛮吸引人的,但目前还没有发现相关开源代码。

随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 新增电动汽车充电设施超1万个!高速公路服务区将迎来提质升级
- 雪佛兰科鲁泽|家用轿车的务实之选
- 案例分享:电动车闯红灯撞车,法院判全赔---非机动车没有“免罚金牌”.
- 加拿大低税进口中国电动汽车,4.9万辆配额要怎么分?
- 6座SUV零百2.8秒,当场把兰博基尼干趴下了!这波我真没看懂
- 丰田9万SUV火了!月销1.4万背后的5个秘密
- 温州大货车要命掉头!小轿车命悬一线
- 大众全新SUV即将来袭,车长超5米2,增程动力+大六座,值得期待?
- 11.98万买220km插混SUV!比亚迪宋Pro DM-i长续航版,解决你所有用车痛点
- 比亚迪全新SUV大唐曝光,尺寸看齐问界M9
