复旦&清华OccLLaMA:首个自动驾驶具身世界模型!全面增强Occ、规划等一切任务!
- 2026-07-04 11:49:46
👇 关注公众号,并选择星标,最新干货每日送达
导读
复旦与清华联合提出OccLLaMA:首个占用-语言-动作生成式世界模型,用自回归统一3D占用、语言与动作,实现4D占用预测、运动规划与问答,多任务SOTA,为自动驾驶奠定VLA基础。
整理丨具身智能前沿
转载自丨计算机视觉工坊
0. 这篇文章干了啥?
近年来,我们见证了多模态大型语言模型(MLLMs)的重大突破,这些模型能够整合语言、图像、音频等多种模态,从而加速了具身人工智能(Embodied AI)的发展。然而,能够处理现实世界多项任务的通用智能体尚未出现。这本质上是因为现有的MLLMs通过学习从感知到动作的直接映射来执行动作,忽略了世界的动态性以及动作与世界动态之间的关系。相比之下,人类拥有世界模型,能够基于三维内部视觉表征模拟未来状态并据此规划动作。因此,探索如何构建智能体的世界模型对于具身智能的发展至关重要。
自动驾驶作为具身AI的一个代表性应用,在世界模型方面已经进行了广泛的研究。然而,自动驾驶世界模型的精确定义仍然是一个开放性问题。当前自动驾驶的世界模型主要关注传感器预测任务,如视频预测、点云预测和占用率预测。然而,它们无法同时实现场景演变预测、语言推理以及与现实世界的交互。因此,我们提出,一个能够统一视觉、语言和动作(VLA)建模的模型,类似于人类的能力,将是自动驾驶世界模型的一个有前景的候选者。
然而,构建VLA世界模型面临两个关键挑战需要解决。首先是构建一个既便于理解又便于生成的通用三维视觉表征;其次是开发一个能够容纳VLA模态的多模态框架。近年来,语义占用率(Occ)作为一种通用三维视觉表征受到了广泛关注。它既能描述细粒度的三维结构,又包含高级语义信息,非常适合于空间和语义的对齐。同时,基于自回归语言模型的视觉生成可行性已经得到了充分验证,其性能可与专注于视觉生成的扩散模型相媲美。这些为应对挑战并基于具有Occ视觉表征的自回归模型构建VLA世界模型提供了有价值的见解。
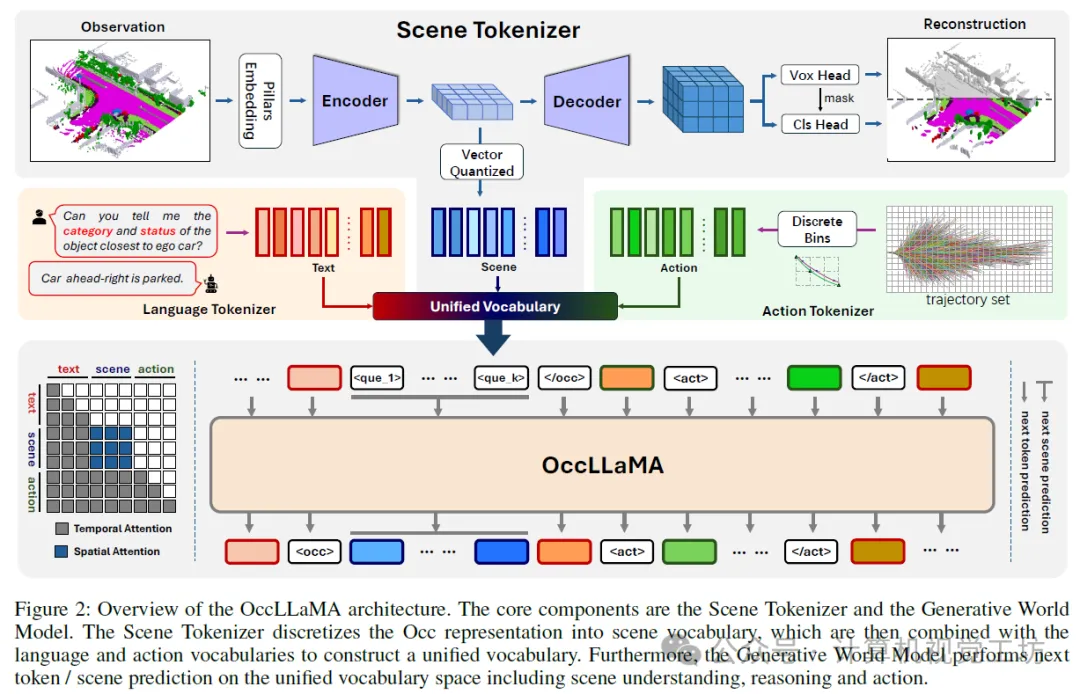
基于上述观察,我们提出了OccLLaMA,一个统一的三维占用率-语言-动作生成式世界模型,它统一了与VLA相关的任务,包括但不限于场景理解、规划和四维占用率预测,如图1所示。为了使OccLLaMA具备理解和生成视觉模态的能力,我们选择Occ作为通用视觉表征,并引入了一种新颖的场景分词器,以有效构建离散场景词汇,同时考虑稀疏性和类别不平衡问题。然后,通过结合场景词汇、语言词汇和动作词汇,我们为VLA任务构建了一个统一的多模态词汇表,为在单个模型中集成VLA奠定了基础。此外,我们增强了大型语言模型(特别是LLaMA),以实现在统一多模态词汇表上的下一个标记/场景预测,从而构建了一个类似于人类的世界模型。
下面一起来阅读一下这项工作~
1. 论文信息
标题:OccLLaMA: An Occupancy-Language-Action Generative World Model for Autonomous Driving
作者:Julong Wei, Shanshuai Yuan, Pengfei Li, Qingda Hu, Zhongxue Gan, Wenchao Ding
机构:复旦大学、清华大学
原文链接:https://arxiv.org/abs/2409.03272
2. 摘要
多模态大语言模型的兴起刺激了其在自动驾驶中的应用。最近基于MLLM的方法通过学习从感知到动作的直接映射来执行动作,忽略了世界的动态以及动作和世界动态之间的关系。相比之下,人类拥有世界模型,使他们能够基于3D内部视觉表示来模拟未来状态,并相应地计划行动。为此,我们提出OccLLaMA,一个占据-语言-动作生成世界模型,它使用语义占据作为一般的视觉表示,并通过自回归模型统一视觉-语言-动作(VLA)模态。具体来说,考虑到场景的稀疏性和类别的不平衡性,我们引入了一种新的类VQVAE场景标记器来有效地离散和重建语义占据场景。然后,我们为视觉、语言和动作建立一个统一的多模态词汇。此外,我们增强了LLM,特别是LLaMA,以在统一的词汇上执行下一个令牌/场景预测,以完成自动驾驶中的多个任务。大量实验表明,OccLLaMA在多项任务中取得了具有竞争力的性能,包括4D占用预测、运动规划和视觉问题回答,展示了其作为自动驾驶基础模型的潜力。
3. 效果展示
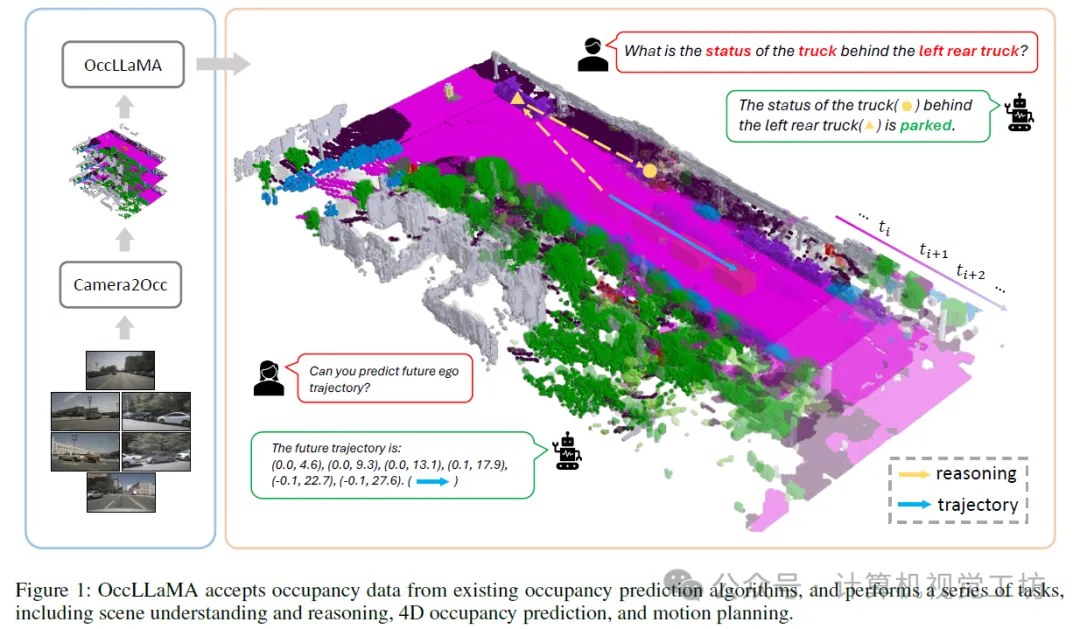
4. 主要贡献
我们的贡献总结如下:
• 提出了一个占用率-语言-动作生成式世界模型OccLLaMA,该模型使用Occ作为视觉表征,并通过统一的多模态词汇表和基于LLaMA增强的自回归模型涉及多个任务。推荐课程:Transformer如何在自动驾驶领域一统江湖!
• 设计了一种新颖的场景分词器,该分词器在考虑稀疏性和类别不平衡的情况下,能够高效地离散化和重构Occ场景。
• 与最先进的方法进行了广泛的实验比较,在包括四维占用率预测、运动规划和视觉问答在内的多个任务上取得了具有竞争力的性能。
5. 基本原理是啥?
我们提出了OccLLaMA,一个统一的占用-语言-动作框架。如图2所示,OccLLaMA的核心组件包括场景分词器和占用-语言-动作生成式世界模型。为了处理多任务,我们为场景分词器训练、占用-语言-动作预训练和指令调优引入了一个三阶段训练方案。
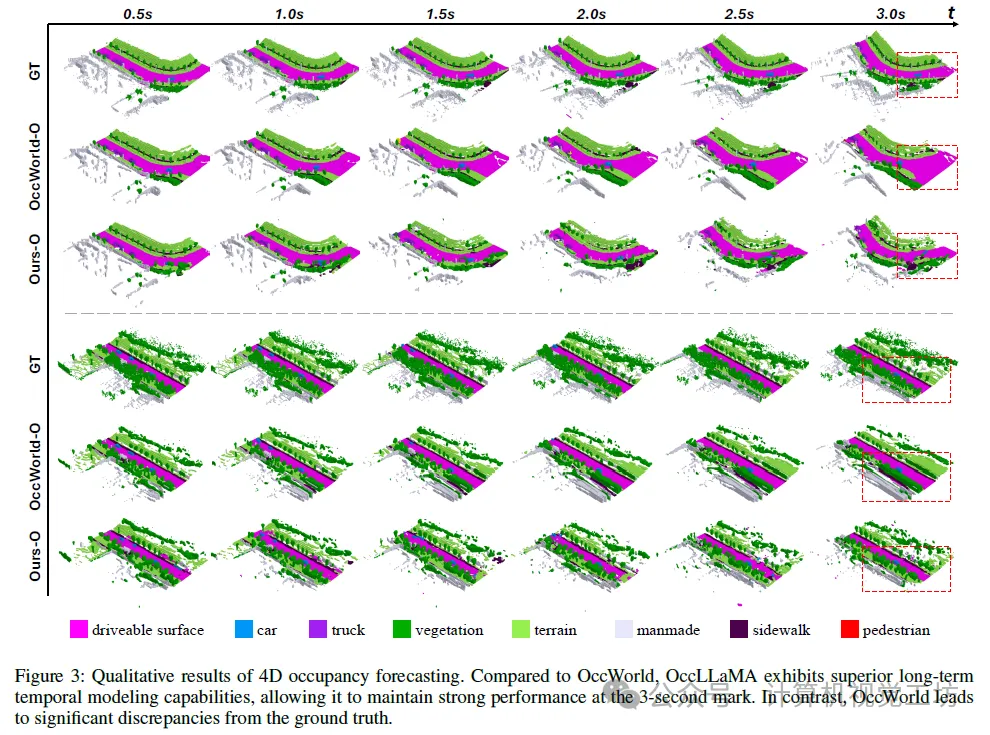
6. 实验结果

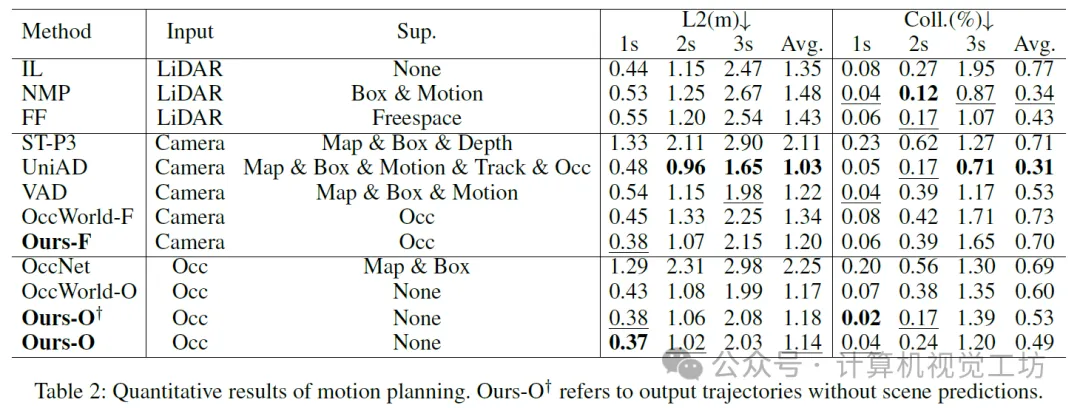

7. 总结 & 未来工作
在本文中,我们提出了OccLLaMA,一个用于自动驾驶多任务的三维占用-语言-动作生成式世界模型。我们引入了一种新颖的场景分词器,用于离散化和重建占用场景。此外,我们构建了一个统一的多模态词汇表,涵盖了占用、语言和动作模态。基于该词汇表,我们使大型语言模型(LLM)适应于执行下一个标记/场景预测,以完成多任务。通过在4D占用预测、运动规划和视觉问答(VQA)上的广泛实验,我们证明了OccLLaMA的多任务有效性。在未来,我们将增加数据多样性,以进一步增强OccLLaMA的能力。我们还将探索模型量化和蒸馏,以解决由大量参数引起的推理延迟问题。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~

公众号后台回复「加群」加入互助群。
文章仅做学术分享,如有侵权请联系删除,非常感谢!
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Dig速递 | 前奔驰北美自动驾驶研究负责人袁汀创业,天海行智慧聚焦多传感信息融合
- 辅助驾驶到自动驾驶分六级
- 特斯拉自主车辆召唤专利:对未来自动驾驶产业的影响与供应链机遇
- 麦肯锡关于自动驾驶的八大预测,你信几个?
- 2026新能源决战开幕:全固态电池与自动驾驶技术将重构千亿市场格局
- 轿车托运 全国二手车往返物流 北京轿车托运 商品车物流 越野车托运 专业笼车运输
- 拆解电动汽车“心脏”与“神经”:三电系统核心技术全解析
- 300万的SUV到底有多变态?开完兰博基尼Urus,我彻底服了
- 行业震撼!北汽联手小马智行突破L4自动驾驶,无人出租车时代真的来了
- 自动驾驶如何“看懂”红绿灯?核心技术全揭秘,安全通行的关键在这里
