
🚗 自动驾驶模型“瘦身”成功!想让大VLM的驾驶智慧跑进小芯片?「龙哥读论文」知识星球每日速递AI前沿,模型压缩、自动驾驶、机器人……你想看的硬核干货这里都有!👇扫码加入「龙哥读论文」知识星球,前沿干货、实用资源一站式拿捏~

龙哥推荐理由:
这篇论文为解决自动驾驶大模型“又大又慢”的落地难题,提供了一个非常系统且有效的思路。它没有停留在简单的知识蒸馏,而是深入剖析了驾驶任务的本质,将“感知-推理-规划”能力分解,并找到了最合适的蒸馏信号和层。更妙的是,它用多教师蒸馏和非对称梯度投影解决了能力间的冲突。最终,一个1B的小模型在规划能力上超越了GPT-5.1,整体性能还超过了同家族78B的庞然大物,效率提升几十倍。这不仅是技术上的精妙设计,更是工程落地的实用指南,强烈推荐给所有关注模型压缩和自动驾驶落地的同学!
原论文信息如下:
论文标题:
Drive-KD: Multi-Teacher Distillation for VLMs in Autonomous Driving
发表日期:
2026年01月
发表单位:
未明确标注
原文链接:
https://arxiv.org/pdf/2601.21288v1.pdf
开源代码链接:
计划在论文发表后发布
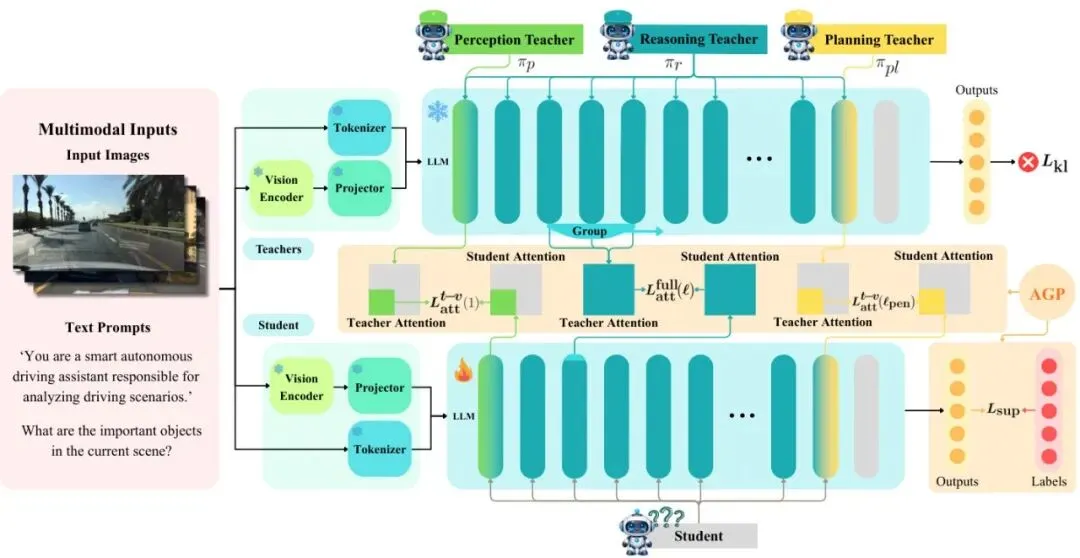
朋友们,想象一下这个场景:未来的自动驾驶汽车,需要很多超大的“大脑”(GPU)来理解路况、做决策,这现实吗?🤨 目前顶尖的视觉-语言大模型(VLM)动辄几十亿、几百亿参数,推理慢、耗电高,想在汽车这种资源受限的边缘设备上实时跑起来,实在是挑战重重。但别急,今天龙哥要聊的这篇论文,就带来了一剂“瘦身猛药”——Drive-KD。它通过一套精妙的知识蒸馏(Knowledge Distillation)方法,竟然让一个仅有10亿参数的小模型,在自动驾驶核心任务上,整体表现超过了同家族780亿参数的庞然大物,甚至在“规划”能力上还超越了GPT-5.1!内存省了42倍,推理速度快了11.4倍!😱这可不是简单的“抄作业”,背后是一套对自动驾驶能力本质的深刻洞察和一套“外科手术”般精准的蒸馏技术。走,跟龙哥一起,看看他们是怎么做到的!图1:Drive-KD多教师蒸馏框架。三个“老师”在不同层指导学生:感知和规划分别使用第一层和倒数第二层的跨模态注意力;推理使用中间层的全注意力。学生也接受输出层的硬标签监督。应用了非对称梯度投影(AGP)来缓解能力间的梯度冲突。自动驾驶大模型太笨重?Drive-KD让1B小模型超越78B巨头
首先,咱们得搞明白什么是知识蒸馏(KD)。你可以把它想象成一位经验丰富的“老教授”(大模型,也叫教师模型)在培养一个“小学霸”(小模型,也叫学生模型)。老教授不直接告诉小学霸每道题的答案,而是传授自己的“解题思路”、“思考方式”甚至“直觉”。这样,小学霸即使自身“脑容量”不大,也能学到精髓,表现得像个小专家。传统蒸馏往往只让学生模仿老师输出的最终答案分布。但Drive-KD的作者们认为,对于自动驾驶这种复杂、安全第一的任务,这远远不够。你学开车时,教练不仅教你“现在该刹车”,更要教你“为什么看到前方有行人要提前减速”、“如何判断旁车意图”、“在复杂路口如何规划路径”。这些分层次、递进式的思考能力,才是关键。所以,Drive-KD的第一步,就是把自动驾驶这个“超级任务”,拆解成人脑也容易理解的“感知-推理-规划”三部曲:
感知:“我看见什么了?”识别环境中的关键语义线索,比如车辆、行人、信号灯、车道线。
推理:“这意味着什么?”基于感知到的线索,推断物体间的关系、交通规则的约束、以及未来可能的行为。比如,“那辆车打转向灯了,它可能要并线”。
规划:“那我该怎么做?”综合所有信息,做出安全、舒适的驾驶决策,比如“减速让行”或“保持车道匀速行驶”。
拆解之后,问题就变成了:如何把大模型在“感知”、“推理”、“规划”这三方面的“内功心法”,精准地灌顶给小学霸?“感知-推理-规划”三步走,蒸馏如何精准传递驾驶能力?
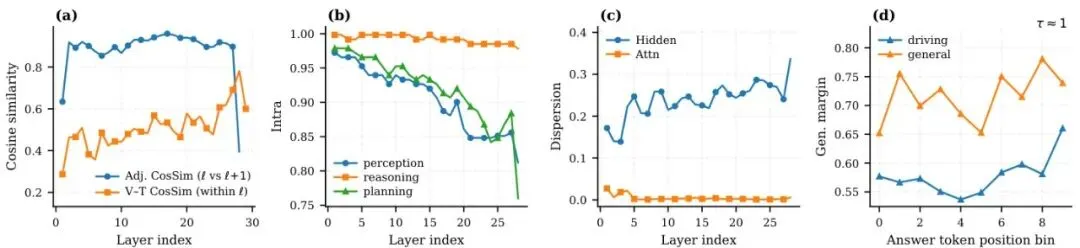
要传功,先得知道“内力”藏在模型的哪个“穴位”(网络层)里。总不能让学生把老师每一层的状态都模仿一遍,那样负担太重,还可能学杂了。Drive-KD的作者们做了一件非常扎实的工作:系统性预研究。他们像做CT扫描一样,深入剖析了大模型在处理驾驶问题时,内部发生了什么。图2:InternVL3-8B模型的预研究总结:(a) 用余弦相似度衡量的层间蒸馏对齐度(相邻层和层内视觉-文本),(b) 跨层的、按能力划分的组内相似度,(c) 隐藏状态和注意力图的层间离散度(1-余弦相似度),(d) 在τ≈1.0时,比较驾驶数据和通用数据在答案段上的位置归一化广义间隔。他们主要研究了两个核心问题:1. 在哪儿蒸馏?(选哪一层?) 2. 蒸馏什么?(模仿老师的什么内部信号?)注意力信号是关键:早期层管感知,中间层管推理,末期层管规划
作者从两个视角找“穴位”:
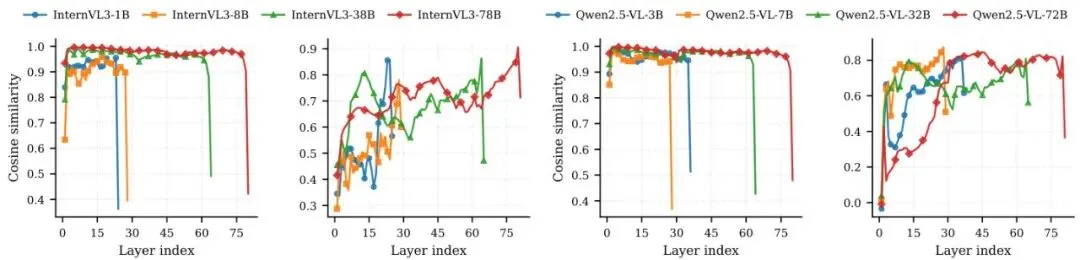
观察模型各层表示变化和视觉-文本融合的程度。他们发现,第一层(Layer 1)和倒数第二层(Penultimate Layer)是信息发生剧烈变化和深度融合的关键位置。图4:跨模型家族和规模的层间相似度曲线。展示了InternVL3 (1B/8B/38B/78B) 和 Qwen2.5-VL (3B/7B/32B/72B) 的相邻层余弦相似度(Adj. CosSim)和层内视觉-文本余弦相似度(V–T CosSim)。
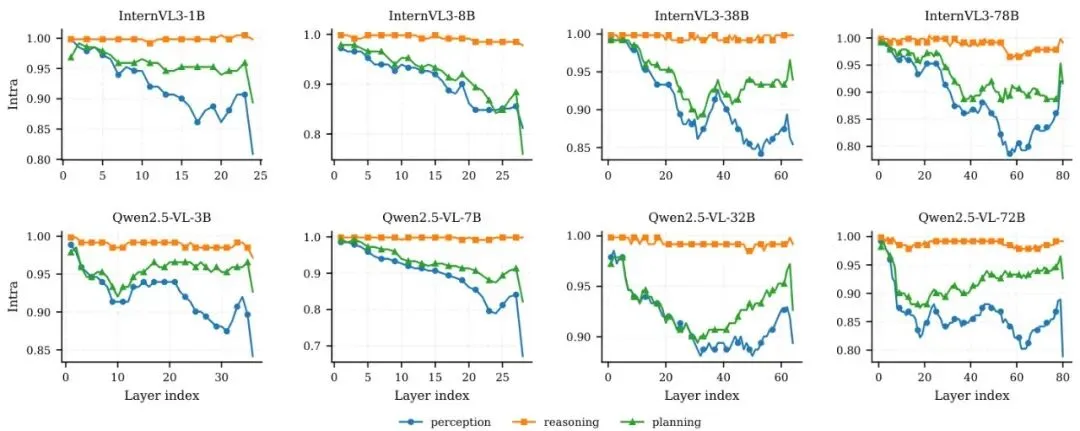
他们计算了能力组内相似度,看看处理同一类能力(如所有感知问题)时,不同图片在哪个层的特征最稳定、最一致。结果非常有趣(见图2b和下图):图5:跨Transformer层的、按能力划分的组内一致性(平均成对余弦相似度)。展示了InternVL3(上行)和Qwen2.5-VL(下行)在感知、推理、规划三种任务类型下的表现。
感知:在第一层最稳定,然后随着网络变深而下降。这说明早期层主要负责捕捉和稳定原始的视觉语义信息。
推理:在各个中间层都保持着较高的稳定性。这说明关系理解和逻辑推断是一个贯穿模型中部、需要广泛信息融合的过程。
规划:在倒数第二层附近有一个明显的峰值。这意味着在做最终决策前,模型在这个位置综合了所有上游信息,形成了专门的规划特征。
综合两个视角,结论呼之欲出:
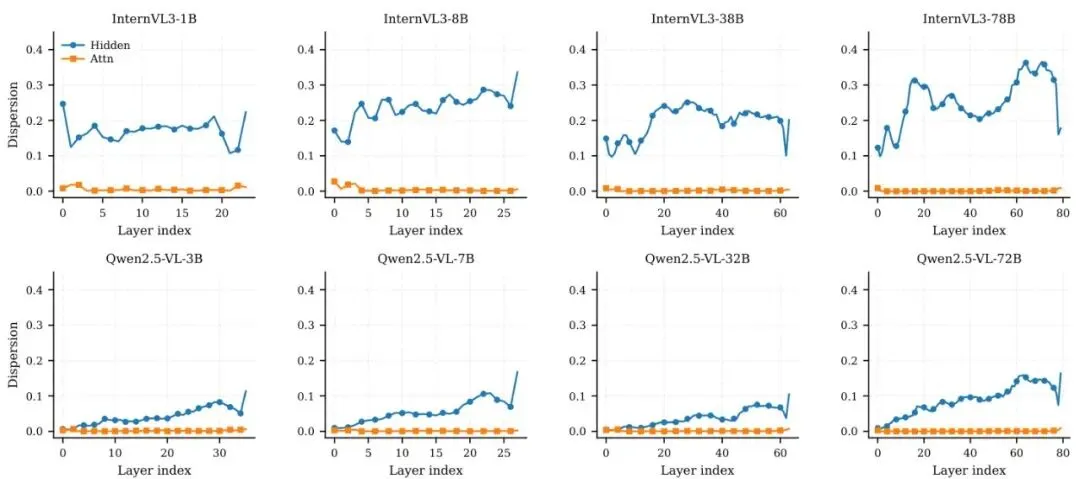
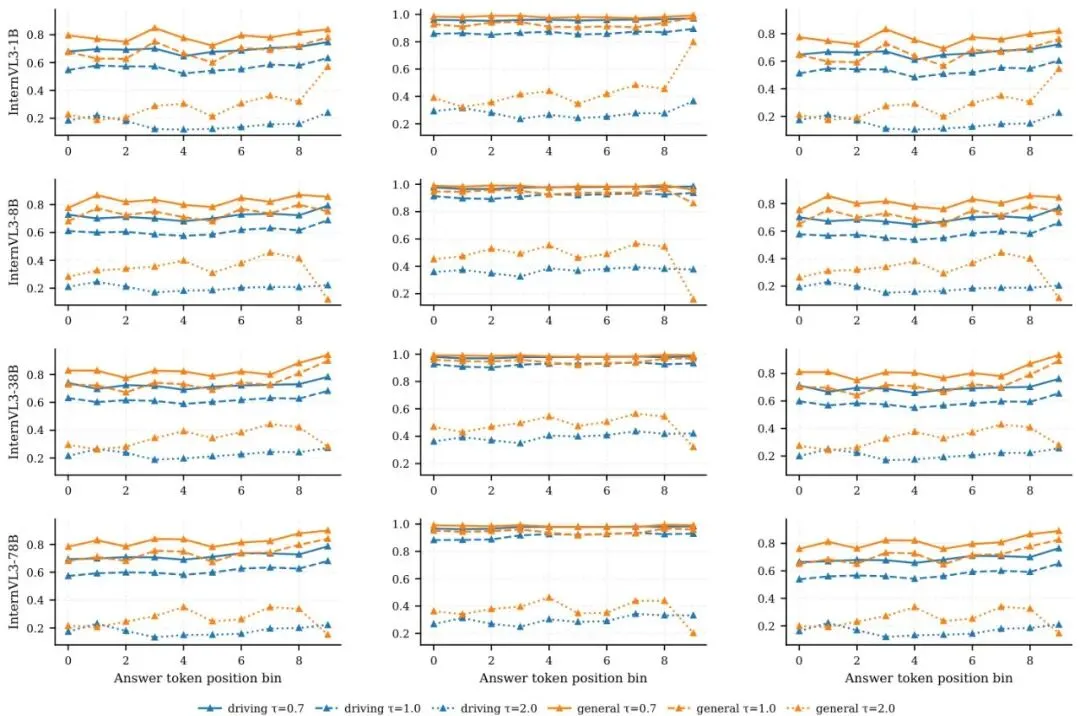
用第一层来蒸馏“感知”能力,用一系列中间层来蒸馏“推理”能力,用倒数第二层来蒸馏“规划”能力。 这和我们的直觉完美契合!👍确定了穴位,下一步是确定传递什么“内力”。常见的候选有:隐藏状态(神经元激活值)和注意力图(Attention Map)。注意力图可以理解为模型在处理信息时,对输入不同部分的“关注程度”。图6:InternVL3和Qwen2.5-VL模型家族在问题重述下的隐藏状态 vs 注意力离散度对比。每个子图对应一个模型;X轴是Transformer层索引,y轴是离散度,以1-余弦相似度衡量。报告了最后词元隐藏表示(Hidden)和平均头注意力图(Attn)的曲线。数值越低表示信号在不同问题表述下越稳定。作者比较了这两种信号在面对同一张图片、不同问法(比如“前面有什么车?”和“前方车辆情况如何?”)时的稳定性。他们发现,注意力图比隐藏状态稳定得多!这意味着,无论问题怎么问,模型“看”图的方式(注意力)是更本质、更能力相关的。因此,Drive-KD选择蒸馏注意力图作为核心信号。他们还重新审视了传统的输出分布对齐(即KL散度蒸馏),发现对于自动驾驶任务,老师的输出分布往往不够自信、比较分散(见图7,8),直接模仿这个“模糊”的答案反而会引入噪声,因此Drive-KD没有使用这种蒸馏方式。图7:InternVL3家族在答案词元位置分箱上的输出分布对齐(KL)分析。行对应模型(1B/8B/38B/78B),列报告三个置信度指标:top-1概率 m,top-10概率和 S,以及广义间隔。每个子图在三个温度(τ∈{0.7, 1.0, 2.0})下比较驾驶答案与通用答案。多教师协作遇冲突?非对称梯度投影巧化解
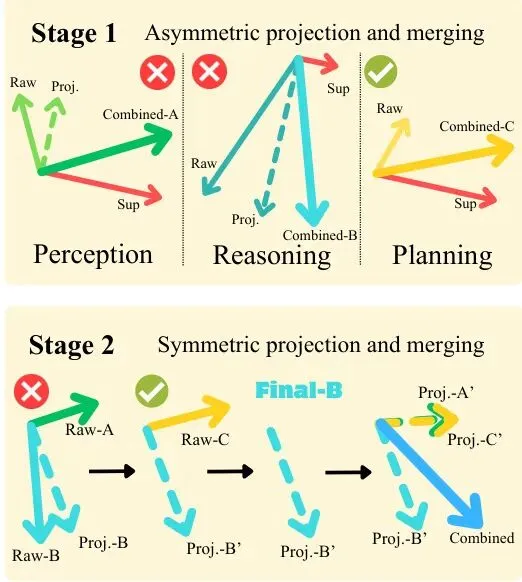
有了单能力蒸馏的“配方”,最理想的情况是训练一个“全能小学霸”,同时掌握三种能力。这就需要多教师蒸馏:感知老师、推理老师、规划老师一起上阵,在每个训练批次中都指导学生。但问题来了:三个老师教的“内功”万一互相冲突怎么办?比如,规划老师说“注意前方”,感知老师说“注意左侧”,模型参数更新时该听谁的?这种梯度冲突会导致训练不稳定,可能提升一个能力而损害另一个。图3:非对称梯度投影(AGP)示意图。阶段1在每个能力内部使用非对称的锚点-跟随者投影并合并结果更新。阶段2跨能力应用洗牌对称成对投影以获得最终梯度方向(以梯度B为例展示)。Drive-KD提出了一个巧妙的解决方案:非对称梯度投影(Asymmetric Gradient Projection, AGP)。这个方法的精髓在于分清主次、化解矛盾:
对于每个能力(如感知),将硬标签损失(即标准答案监督)的梯度作为“锚点”,将多个教师蒸馏损失的合并梯度作为“跟随者”。只消除“跟随者”中与“锚点”冲突的部分,然后合并。这确保了基础答案的正确性不被教师的“软指导”带偏。
得到了感知、推理、规划三个“能力级”合并梯度后,它们之间也可能冲突。AGP采用随机顺序的成对投影:随机排个序,让后面的梯度消除与前面梯度冲突的部分。这样避免了总是牺牲某个固定能力,最终求和得到一个和谐的总更新方向。这个方法的设计非常精巧,相当于给三个老师的教学意见安排了一个“会议主持人”,确保大家的指导方向大体一致,最终让学生受益。实验验证:小模型实现性能飞跃,规划能力甚至超越GPT-5.1
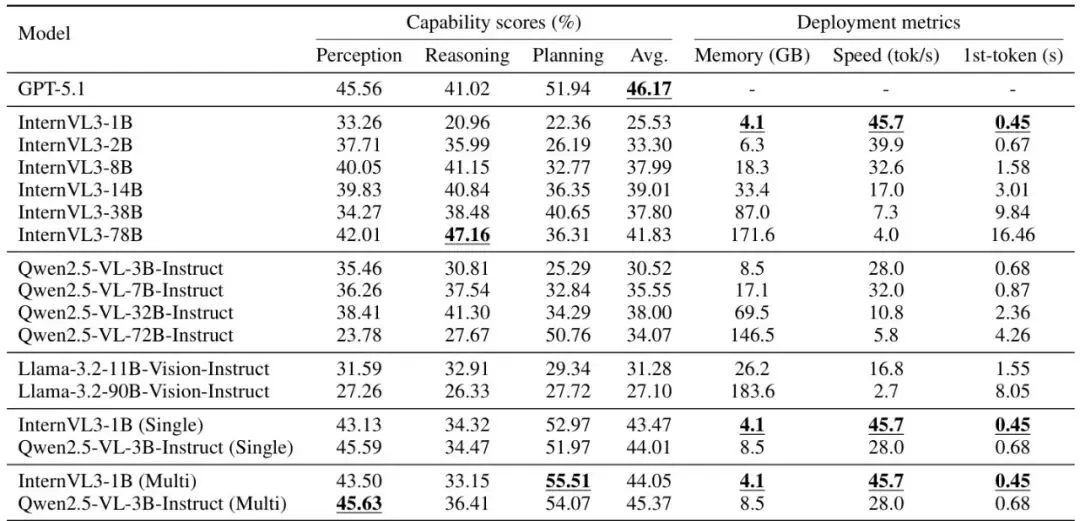
理论说得再好,还得看疗效。作者在权威的自动驾驶基准DriveBench上进行了全面测试,并使用DeepSeek-V3.2作为评估器打分。结果令人震惊!表1:代表性VLM在DriveBench上的能力性能及面向部署的推理效率。报告了能力得分(%)和推理指标,包括最低可行GPU数量下的峰值GPU内存(GB)、平均GPU端生成吞吐量(tokens/s)和中位数GPU端首词元时间(s)。
1. 单教师蒸馏已显神威:经过单能力蒸馏后的InternVL3-1B(Single),平均得分从25.53飙升至43.47!规划得分达到52.97,已经超过了GPT-5.1的51.94!这说明他们找到的“穴位”和“内力”(注意力)确实有效。
2. 多教师蒸馏更上一层楼:使用Drive-KD完整框架(Multi)后,InternVL3-1B的规划能力进一步提升到55.51,平均分也达到44.05。整体表现(Avg.)超越了同家族预训练的78B模型(41.83)!而它的内存占用(4.1 GB)仅为78B模型(171.6 GB)的1/42,吞吐量(45.7 tok/s)是后者的11.4倍!
更妙的是,Drive-KD模型不仅规划分数高,其推理和规划能力在同一场景下表现出正相关性(见表2),这意味着它的决策更连贯、更基于理解,而不仅仅是“蒙对”了答案。
3. 消融实验证明设计有效性:表4的消融实验清晰地证明了每一步设计的必要性:输出KL蒸馏有害;隐藏状态蒸馏不如注意力蒸馏;而在多教师训练中,不使用梯度处理会严重损害推理能力,AGP方案效果最好。
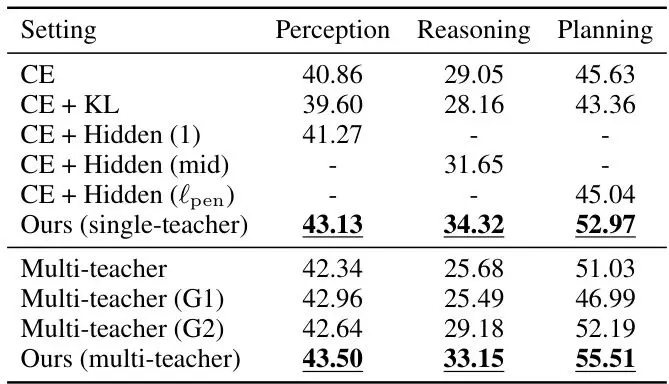
表4:InternVL3-1B在DriveBench上的消融实验:蒸馏目标与梯度冲突处理。效率与性能兼得,为车载边缘AI部署铺平道路
Drive-KD的成功,不仅仅是刷高了一个榜单分数。它的核心价值在于为高级自动驾驶AI功能的实际落地扫清了一个关键障碍——计算资源。通过将大模型的“驾驶智慧”压缩到一个小巧、高效的模型中,Drive-KD使得:
更低的延迟和更高的吞吐量意味着车辆能更快地理解和决策。
不需要顶级车载计算芯片,在中端甚至更经济的硬件上也能运行强大的VLM驾驶助手。
“感知-推理-规划”的分解式设计,相比黑盒式的端到端模型,更能让我们理解模型为何做出某个决策,这对安全至关重要。当然,论文作者也清醒地指出,目前所有测试都是在开环评估(只回答问题,不实际控制车辆)下进行的。要将这样的模型真正用于控制物理车辆,还必须经过极其严格的闭环仿真和长尾/边缘案例测试。但无论如何,Drive-KD已经为我们指明了一条通往高效、实用自动驾驶AI的清晰路径。龙迷三问
这篇论文主要解决了什么问题?解决了大型视觉-语言模型(VLM)在自动驾驶领域因模型太大、推理太慢而难以在实际车辆上部署的问题。它通过一套新颖的知识蒸馏方法(Drive-KD),将大模型的“驾驶能力”高效压缩到小模型里,让小模型在性能接近甚至超越大模型的同时,内存和计算需求大幅降低。
知识蒸馏中的“注意力”具体指什么?为什么它比模仿最终输出更好?这里的“注意力”指的是Transformer模型中的注意力机制(Attention Mechanism)产生的权重图。它反映了模型在处理输入时,对序列中不同部分(如图像块、文字词)的“关注”程度。模仿注意力,就是让学生学习老师的“思考焦点”。论文发现,对于驾驶任务,老师的注意力模式比其最终输出的答案分布更稳定、更本质,因此是更好的知识传递信号。
非对称梯度投影(AGP)听起来很复杂,能用更简单的例子解释吗?可以想象你在同时学数学、语文、英语三门课。数学老师(硬标签监督)教的是最基础的定理和公式(锚点)。另外三位专家老师(感知、推理、规划蒸馏)分别教你更巧妙的解题思路、阅读理解方法和写作技巧(跟随者)。AGP的作用是:首先确保你学到的专家技巧不会和基础数学定理冲突(阶段1)。然后,协调三位专家老师的教学,如果他们教的方法在深层原理上有矛盾,就调整一下,确保你最终学到的是一套和谐、不自我矛盾的知识体系(阶段2),而不是学得精神分裂。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~龙哥点评
论文创新性分数:★★★★★
将自动驾驶任务系统性地分解为“感知-推理-规划”,并首次针对该领域进行深入的蒸馏信号(层、注意力)预研究,思路清晰且富有洞察力。多教师蒸馏结合非对称梯度投影(AGP)解决冲突的构思巧妙。实验合理度:★★★★☆
实验设计全面,涵盖了单教师、多教师、消融、跨模型家族和规模验证。使用DriveBench基准和LLM评估器符合当前趋势。消融实验有力地支撑了各个技术组件的必要性。略微扣分在于评估仍依赖于LLM打分,存在一定随机性,但作者报告了多次运行的标准差。学术研究价值:★★★★★
为特定垂直领域(自动驾驶)的知识蒸馏提供了首个系统性的研究范本。其“能力分解-信号选择-冲突协调”的方法论,对机器人、医疗影像分析等其他需要复杂、序列化决策的AI应用具有很高的启发和借鉴价值。稳定性:★★★☆☆
方法在开环问答评估上表现稳定且显著超越基线。但由于是VLM模型,其输出可能仍存在幻觉或不一致。论文本身也强调,该方法产出的模型必须经过严格的闭环测试才能考虑部署,距离直接产品化尚有距离。适应性以及泛化能力:★★★★☆
论文在InternVL3和Qwen2.5-VL两个不同家族的模型上验证了有效性,并探索了不同教师-学生规模组合,证明了其泛化能力。理论上该方法可迁移到其他VLM架构和类似序列决策任务。硬件需求及成本:★★★★★
核心目标就是降低部署成本。蒸馏后的小模型本身硬件需求极低(如1B模型仅需4GB显存),适合边缘部署。但蒸馏训练过程仍需使用大模型作为教师,有一定训练成本。复现难度:★★★☆☆
方法描述详细,包含了预研究分析和具体训练配置。但论文依赖一个10K的高质量人工标注驾驶蒸馏数据集,该数据集未公开。代码计划开源但尚未发布,这给完全复现带来一定困难。产品化成熟度:★★☆☆☆
目前仅为研究阶段,在开环问答任务上证明概念。要用于实际车辆控制,需要与底层控制模块集成,并经历海量的闭环仿真和实车路测以验证其安全性、鲁棒性,处理长尾极端情况。这是从研究到产品最漫长、最艰难的一步。可能的问题:本论文的评估完全基于静态问答(开环),未测试其在动态交互环境或与控制器闭环连接时的表现。推理能力仍然是三个能力中最难提升的短板。此外,其效果高度依赖用于蒸馏的标注数据集质量。
[1] Weitong Lian, Zecong Tang, Haoran Li, et al. Drive-KD: Multi-Teacher Distillation for VLMs in Autonomous Driving. arXiv preprint arXiv:2601.21288, 2026. (本论文)[2] Xie, S., Kong, L., Dong, Y., et al. Are VLMs Ready for Autonomous Driving? An Empirical Study from the Reliability, Data and Metric Perspectives. In ICCV, 2025. (DriveBench基准)*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的"阅读原文",查看更多原论文细节哦!

🚗 想和更多自动驾驶、机器人领域的小伙伴一起“蒸馏”知识、交流前沿吗?欢迎加入龙哥读论文粉丝群,
扫描下方二维码或者添加龙哥助手微信号加群:kangjinlonghelper。
一定要备注:研究方向+地点+学校/公司+昵称(如 自动驾驶+北京+清华+龙哥),根据格式备注,可更快被通过且邀请进群。





 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
