编者语:后台回复“入群”,加入「智驾最前沿」微信交流群
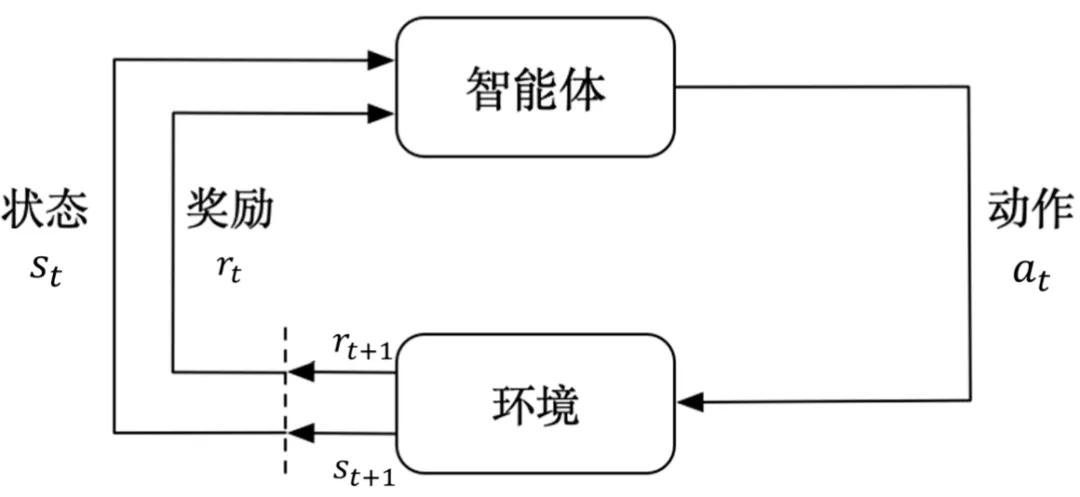
在之前谈及自动驾驶模型学习时,详细聊过强化学习的作用,由于强化学习能让大模型通过交互学到策略,不需要固定的规则,从而给自动驾驶的落地创造了更多可能。
强化学习示意图,图片源自:网络
但强化学习本身是需要不断试错的,如果采用这种学习方式在真实道路中不断尝试,一定会导致不可控的事故。于是就有人提出一种猜测,能不能利用已经存在的大量行驶日志、仿真记录和人类驾驶数据,在训练过程中完全不与真实环境交互,从而训练出一个靠谱的决策模块?
离线强化学习就是基于此提出的方案。离线强化学习先收集一大堆过去的经验(含状态、动作、后果/奖励等),然后把这些经验当成教材,让模型在离线状态下学习策略,而不是去真实交通场景中试错。这样做的好处是安全、低成本、能重复利用现有数据;但也带来了不少问题,我们后面会详细说。
离线强化学习的技术挑战
离线强化学习在训练阶段只能访问一个固定的数据集,这个数据集是由若干次交互生成的记录集合;训练算法不能再向环境发出动作来采集新的样本。这个改变会带来分布覆盖问题、估值偏差问题以及评估难题。
离线强化学习训练大模型时,提供的历史数据来源于某些已有的行为策略或人为驾驶习惯,数据中可能压根没有某些状态-动作对。如果训练出的策略在部署时选择了数据中极少或根本没有覆盖的动作,算法对这些动作的价值估计将会非常不可靠。
图片源自:网络
在离线数据里,有些动作要么出现得很少,要么干脆没出现过。按理说,模型对这些动作应该非常谨慎才对。但强化学习算法在估计动作价值(Q值)时,会因为缺少真实数据支撑,反而会把这些动作估得特别好。导致的结果就是,模型会觉得这个操作收益很高,然后在学策略时越来越偏向这些现实中并不安全、甚至根本不可行的行为。
除此之外,离线强化学习在训练时无法在真实交通环境中验证策略,只能依赖离线的估计方法或仿真,这使得对学习到的策略的可靠性验证变得更复杂。为了解决分布偏差和估值问题,离线强化学习算法还必须加入保守项、不确定性估计、行为约束等,这些都会增加实现难度与调参成本。
离线强化学习的主流思路
现阶段,离线强化学习使用较多的实现方式就是行为克隆,即把问题转成监督学习,直接用历史状态去预测历史动作,学会“模仿人类驾驶”。行为克隆实现简单、训练稳定,但它的上限被数据中人类驾驶的质量限制,且无法处理数据中没有覆盖到的新场景。
为了解决行为克隆存在的问题,出现了以价值估计为核心、但带有保守性约束的离线强化学习算法,主要有“行为约束”及“保守估值”两种策略。行为约束也就是在优化策略时,直接限制新策略不能偏离已有数据太远;保守估值策略是在估计行动价值时,对数据中不存在的行动进行刻意惩罚。这些做法都是为了压低不切实际的乐观估计,让学习过程更可靠。
图片源自:网络
还有一种思路是先学习一个环境动力学模型,然后在模型中进行规划或策略优化,这一思路的关键在于如何让模型在不确定或预测不可靠的区域加入惩罚或不信任度折扣,避免因模型错误导致的危险动作。
此外,还有一些如ensemble(集成)不确定性估计、用置信区间控制决策、或把离线学习作为预训练基座,然后在受控的仿真或沙箱里做有限的在线微调的方法用于实现模型学习。
在实际应用中,这些方法常会被组合使用,行为克隆可作为稳定的初始策略;保守Q学习或批量约束方法能进一步提升策略性能;而基于模型的规划与不确定性估计则充当风险控制的补充。需要强调的是,无论采用何种方法,数据的多样性与质量始终是决定成效的根本,如果缺乏对某些场景的覆盖,任何算法都难以实现安全可靠的泛化。
自动驾驶如何用好离线强化学习?
自动驾驶如何用好离线强化学习?首先要做的是要规划好数据收集体系。除了日常驾驶日志,还要主动合成和收集如夜间、逆光、大雨、大雾、临时施工场景、行人异常行为等边缘情况的样本。仿真在这里的作用非常重要,它可以弥补现实场景中稀缺的数据,但必须和真实数据结合。
接着就是要做好分阶段训练流程,在大模型学习的整个链路中,可以把离线强化学习当作预训练的手段,可以先在大规模历史数据上训练出一个“稳健基线”;然后在高保真仿真里对该策略做更多场景覆盖测试;最后就是进行受控上线(比如先在特定区域、低速、有人监控的条件下运行),在实际运行中以“shadowmode(影子模式)”不断记录策略决策与真实驾驶者行为的差异,收集新数据用于后续离线微调。
在进行大模型部署时,一定要有强制的安全层和退回机制。不管策略多完善,都要有独立的安全监控,当感知或决策模块检测到高不确定性、模型越界或可能造成人员伤害的风险时,系统应降级到更保守的控制逻辑,或者直接交由人为接管。
图片源自:网络
评估和指标体系的设定也要更加严谨。单靠训练时的“平均回报”或离线估计不足以判断部署的安全性,其中需要包括不确定性分布、最差-k%情况、OPE(离线策略评估)方法、以及通过仿真和小规模上线验证得到的指标等多维度指标。
对于自动驾驶来说,监管与责任框架必须要预先设计好。在真实交通环境中,任何决策一旦出问题,就会牵扯到责任认定、修复补救和合规审查,离线强化学习的训练日志与决策解释将是重要证据。因此,要保证数据可追溯、策略版本可回滚、并保留充分的审计记录。
最后的话
虽然离线强化学习面临着“数据决定上限”与“分布外泛化难”的问题,但其给现实世界应用,尤其是自动驾驶这类安全敏感任务,提供了一个非常有价值的实现路径。它缓和了“强化学习的潜力”与“现实世界的安全约束”之间的矛盾,使我们能利用海量历史经验去训练智能策略。
-- END --





 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
