视觉独大的自动驾驶,缺了关键一环 | 智能驾驶的耳朵,能多救一条命!
- 2026-02-23 13:37:36

你开过车,一定遇到过这种情况:导航说“前方路口右转”,你盯着屏幕上的3D地图,却死活找不到那个该拐的路口。或者,在嘈杂的十字路口,一个交警的手势让你瞬间迷惑:“他到底是指挥我走,还是让我停?” 更可怕的是,如果驾驶员因为疲劳或饮酒,反应变得迟钝,车辆却对此一无所知,悲剧可能就在下一秒发生。
我们总以为,让汽车变“聪明”就是给它装上更多、更清晰的“眼睛”——激光雷达、高清摄像头。但一个残酷的现实是:人类驾驶员超过30%的安全决策,依赖于“耳朵”。警笛声、喇叭声、行人的呼喊、甚至副驾驶的一句提醒,这些声音承载着视觉无法捕捉的紧迫性与意图。
然而,当前主流的自动驾驶系统,几乎都是“聋子”。它们能“看到”百米外的障碍物,却“听不到”身后疾驰而来的救护车鸣笛。这个致命的感知盲区,正在被一项名为 “内外视听”(Looking-and-Listening Inside-and-Outside, L-LIO) 的前沿框架所挑战。
今天,我们就来深度拆解这项研究。读完本文,你将彻底明白:为什么给智能车装上“耳朵”,不仅是锦上添花,更是安全底线上的生死攸关。这或许将重塑你对下一代人车交互的全部认知。
❓ 核心痛点:视觉独大的自动驾驶,缺了关键一环
当前的自动驾驶感知系统,陷入了一种“视觉霸权”的困境。无论是特斯拉的纯视觉方案,还是多数车企的多传感器融合,核心都围绕着“看”:
• 向外看(Looking-out):用摄像头、激光雷达、毫米波雷达感知车道线、车辆、行人、交通标志。 • 向内看(Looking-in):用舱内摄像头监测驾驶员状态,如视线、疲劳、分心。
这个“内外兼顾”(LILO)的范式,在过去十年推动了智能驾驶安全的长足进步。但它有一个与生俱来的阿喀琉斯之踵——它假定所有关键信息都是可视的。
现实却狠狠打了这个假设的脸:
1. 紧急事件,声音先行:救护车、消防车的警笛声,往往在你看到它之前就已响起。在视野被大车遮挡的十字路口,喇叭声是避免碰撞的最后警告。一个“聋子”系统,会错过这些黄金预警时间。 2. 意图传达,言胜于行:乘客说“过了那个红色邮筒再右转”,这比GPS坐标或预设路径点包含了更丰富的语义和上下文。人类驾驶员能瞬间理解,但现有系统却无法处理这种非结构化的口语指令。 3. 状态评估,听音识人:驾驶员是否清醒、紧张或疲劳?除了眼神和姿态,其语音的语调、节奏、清晰度变化,是更直接、更早期的生理状态信号。仅靠“看脸”,可能会漏掉关键风险。
更严峻的是,随着大语言模型(LLM)、视觉-语言模型(VLM)成为AI交互的核心,自然语言正在成为人与机器沟通的最高效桥梁。如果智能车的“耳朵”是聋的,它就无法真正融入这个以语言为中心的智能生态,永远只是个执行预设程序的“机器”,而非能理解人类意图的“伙伴”。
所以,问题来了:如果“听”的能力如此重要,为什么它一直被忽视?又该如何系统性地为智能车构建这套听觉感知系统?
为了帮你快速把握全局脉络,我们先看这张核心架构思维导图——它清晰地展示了L-LIO框架如何将车内外的听觉信息,系统性地融入感知、决策与交互的每一个环节。
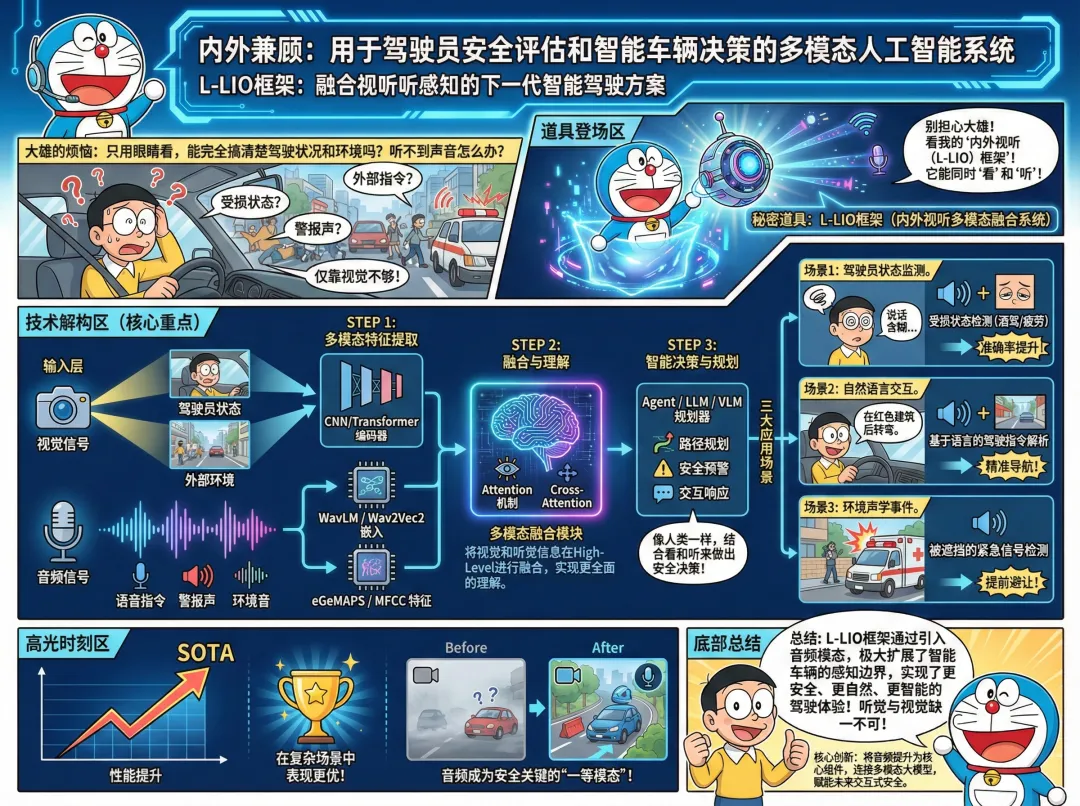
接下来,我们逐层拆解这张图中的三个核心战场,看看“听觉”究竟如何破局。
🚀 原理拆解:给智能车装上三只“耳朵”
L-LIO框架的精髓,在于它不再把音频当作背景噪音或附属品,而是将其提升为与视觉平起平坐的 “一等模态” 。它主要从三个维度切入,对应智能车需要倾听的三种关键声音。
💡 第一只耳:听诊器——诊断驾驶员状态
第一个案例研究,直指一个敏感而关键的问题:能否通过驾驶员短语音,判断其是否饮酒达到危险驾驶状态?
这并非要替代酒精检测仪,而是探索音频能否作为一种早期、非侵入式的软性风险预警信号。研究团队设计了一个严谨的实验:
• 数据收集:在受控环境下,让参与者摄入酒精,使其呼气酒精浓度(BrAC)达到0.08%(美国酒驾标准)。分别在清醒和饮酒后录制其朗读固定短语(如“请带我去最近的加油站”)的语音。 • 核心挑战:从可能只有几秒钟的语音中,剥离出与酒精相关的、且能跨不同说话人泛化的细微特征。
技术显微镜:如何从声音里“听”出异常?
这里的关键在于声学表征的选择。研究对比了四种从传统到最前沿的语音特征提取方法:
1. 传统手工特征(MFCC/eGeMAPS):类似于给声音做“体检”,测量其音高、能量、频谱等指标。这些特征可解释性强,但依赖人工设计,可能忽略深层模式。 2. 自监督学习特征(Wav2Vec2/WavLM):让AI模型在海量无标签语音数据中自我学习,获得更通用、更深层的语音表征。这好比让AI自己学会“听音辨位”。
实验发现了一个反直觉的结论:并非所有先进的语音模型都适合这个任务。专门为语音识别优化的模型(如Wav2Vec2),其目标是消除说话人口音、情绪等差异,只保留文字内容。但这恰恰过滤掉了我们需要的、与状态相关的副语言信息(如 slurred speech,含糊的发音)。
相反,专门为嘈杂环境、多人说话场景优化的模型(如WavLM),或保留更多细节的传统特征,表现更好。因为它们在设计上就需要保留区分不同说话人、不同状态的声学线索。
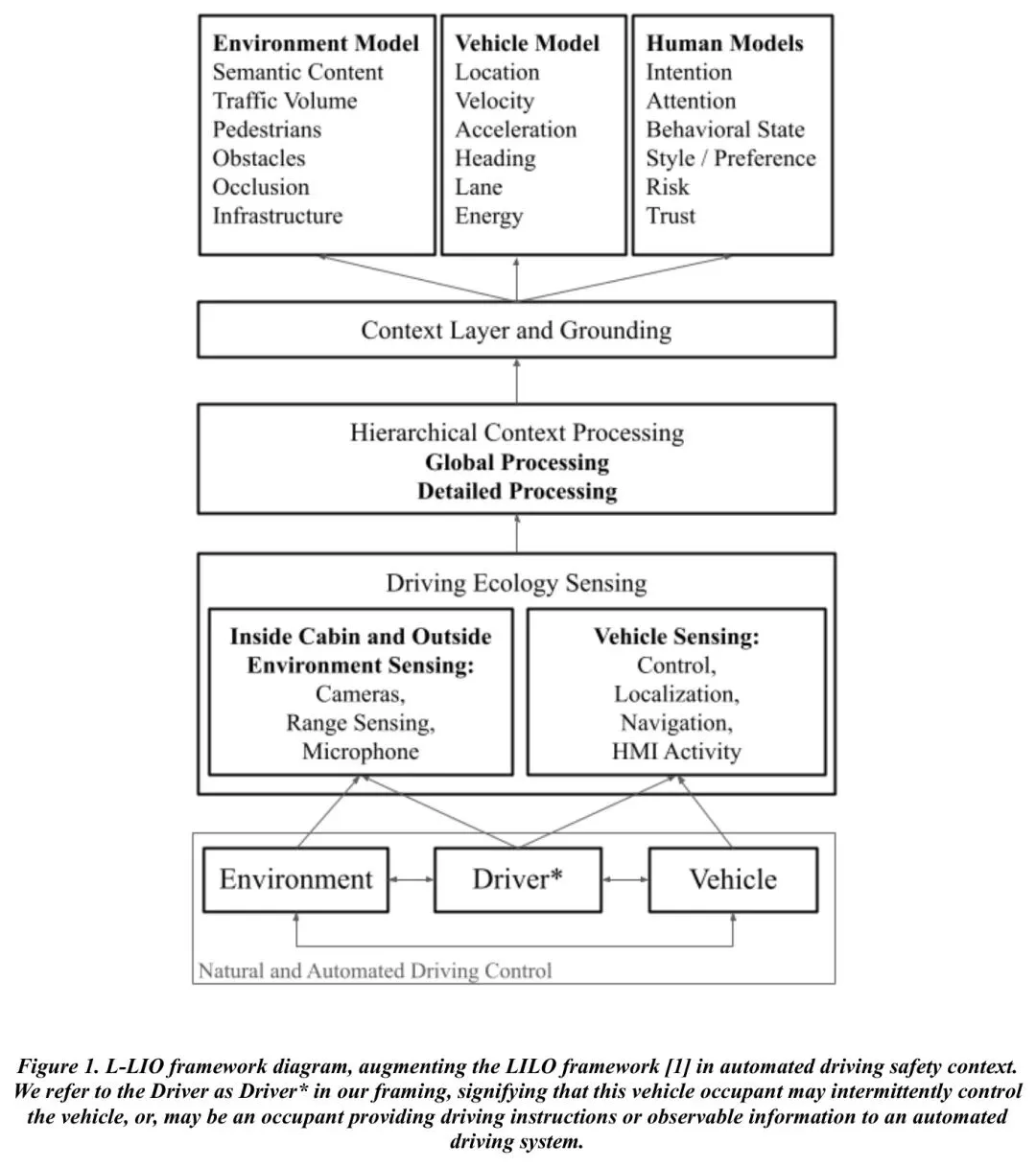
结果与启示:在严格的“留一受试者”交叉验证下(即训练时完全没见过测试者的数据),最佳模型达到了约0.65的AUC(Area Under Curve,可理解为分类能力,0.5为随机猜测)。这意味着,仅凭短语音,系统已经具备了显著优于随机的损伤辨别能力。
但这个数字也明确告诉我们:音频不能作为单一判据。不同人对酒精的语音反应差异巨大。它的真正价值在于,当系统检测到语音特征出现“轻微异常”时,可以触发更高级别的视觉监控(如更频繁地检测眼睑闭合),或采取更保守的驾驶策略(如增大跟车距离),实现 “多模态冗余校验”。
💡 实战思考:这个思路可以泛化。除了酒驾,是否也能通过语音实时监测驾驶员的疲劳、愤怒或突发疾病?这为主动安全打开了新维度。
💡 第二只耳:翻译官——理解乘客的意图
当车辆进入高阶自动驾驶,乘客从驾驶员变为乘员。交互方式也从“操控”变为“对话”。第二个案例研究,就是要解决这个问题:如何让车听懂乘客的自然语言指令,并安全地执行?
研究团队做了两件事:
1. 构建“指令-场景-轨迹”三元组数据集:他们观看真实驾驶视频,并假想自己是乘客,为车辆当时的行驶轨迹配上指令,例如:“绕过前面那辆双闪的卡车”。这样就得到了语言如何对应具体驾驶动作的样本。 2. 集成到规划器:将这些自然语言指令,输入一个开源的视觉-语言-动作(VLA)规划模型。
一个生动的例子揭示了关键:在没有指令时,规划模型可能对前方路况产生困惑。但当乘客说出“等那辆自行车过去后再左转”时,模型生成的轨迹明显变得更加谨慎、合理,更贴近人类的驾驶选择。

更深层的挑战与自动化工具:依赖乘客实时发出完美指令不现实。为此,研究团队提出了 ADVLAT引擎 的概念。它的核心思想是自动化收集“指令-动作”数据。例如:
• 利用GPS导航语音:录制“前方300米右转”等导航指令,并自动与车辆当时的视觉场景和实际行驶轨迹对齐。 • 这能大规模、低成本地构建训练数据集,让模型学习各种语言表述与驾驶动作的映射关系,最终实现即使乘客指令模糊(如“在那栋红房子那儿停”),车辆也能结合实时视觉,准确理解并执行。
这标志着,车载语音交互将从“语音控制”升级为“语义理解与协同规划”。
💡 第三只耳:顺风耳——感知车外的危险
第三个案例,直面当前纯视觉系统的软肋:理解复杂交通场景中,人类的手势和意图。想象一个场景:道路施工,交通指挥员用手势引导车辆逆行借道。他的手势到底是什么意思?仅靠摄像头,AI很可能误判。
研究团队测试了当前顶尖的视觉-语言模型(VLM),让它们描述或分类交通手势。结果令人警醒:模型表现远未达到可靠水平,手势分类F1分数(平衡准确率与召回率)远低于人类专家基准。
音频的破局点在于“消除歧义”:在真实的指挥场景中,手势往往伴随着哨声、大声的口头指令(如“走!”、“停!”)。这些声音提供了高精度的时间信号和明确的意图标签。
• 声学事件检测(AED):系统可以实时检测警笛、喇叭、哨音、特定关键词呼喊等声音,并标记为高优先级安全事件。 • 多模态融合:当视觉系统识别到一个“意义不明”的手势时,如果同时检测到“急促哨音”,系统就能以高置信度判断为“紧急通行指令”;如果听到“停车”喊声,则能确认手势是“停止”信号。
这相当于为视觉系统配备了一个“音频校对员”,在关键且模糊的时刻,提供第二意见,极大提升决策的鲁棒性。
📊 实验验证:数据不说谎,但需要被听见
为了量化音频的价值,研究团队在三个案例中都设置了严谨的评估体系。
🏆 驾驶员状态检测:WavLM显优势
在驾驶员状态分类任务中,不同声学特征的性能差异显著,这直接印证了特征设计对任务的重要性。
| WavLM (自监督) | ~0.65 | 最佳 | |
| 相对较差 |
表:不同声学特征在驾驶员损伤分类任务上的表现对比。AUC越接近1越好。
数据清晰地告诉我们:想要“听诊”驾驶员状态,必须选择那些能“听见”说话人自身特质变化的模型,而不是只专注于“听懂”他说了什么字。
🔬 指令跟随规划:语言降低轨迹误差
在将自然语言指令集成到规划模型的实验中,研究采用了平均位移误差(ADE) 来衡量预测轨迹与真实轨迹的接近程度。
关键结果是:在测试场景中,引入乘客自然语言指令的规划器,其ADE从2.879降低至2.732。更重要的是,它抑制了一些严重的规划失败案例。这说明,语言指令不仅提供了空间指引,更传递了驾驶意图和上下文约束,让规划更贴近人类的安全驾驶逻辑。
🧪 手势理解:纯视觉的瓶颈与音频的潜力
在交通手势理解任务中,当前先进视觉-语言模型(VLM)的表现为我们敲响了警钟:
• 句子相似度:模型生成的手势描述与人类标注的相似度低于0.59(满分1)。 • 手势分类F1分数:仅在0.14-0.39之间,远低于人类专家0.70的基准。
这些数字冰冷地揭示:在安全关键的手势理解上,纯视觉模型的可靠性目前还不可接受。 这恰恰反向证明了,引入音频作为冗余和消歧通道,不是“锦上添花”,而是弥补现有技术缺陷、迈向可靠安全的必经之路。
⚖️ 客观评价:前景广阔,挑战犹存
L-LIO框架为我们描绘了一个更安全、更智能的交互式驾驶未来,但它走向成熟,还必须跨越几座大山:
1. 数据规模与泛化性:当前研究基于小规模试点数据。要训练出真正鲁棒的模型,需要涵盖不同口音、方言、噪声环境、车辆型号的超大规模多模态驾驶音频数据集。这需要整个行业的共同努力。 2. 噪声与鲁棒性:车内环境嘈杂(音乐、空调、风噪、多人交谈),车外环境更是复杂多变。音频前端处理(降噪、声源分离、回声消除)技术必须足够强大。 3. 隐私与伦理:持续监听舱内对话涉及高度隐私。系统设计必须遵循 “隐私优先” 原则,例如,只在本地处理音频特征,不上传原始录音;或明确告知用户并征得同意。 4. 安全仲裁与责任:当音频信号与视觉信号冲突时,系统听谁的?必须建立一套可靠的多模态融合与置信度评估机制,以及在不确定性极高时的最小风险策略(如减速、停车、请求人工接管)。
🌟 价值升华:从“聋子”到“知音”,智能驾驶的必由之路
回顾全文,L-LIO框架的价值远不止于增加一个传感器。它代表着智能驾驶感知范式的根本性进化:
1. 从“监控”到“诊断”:音频让系统能更早、更细腻地感知驾驶员的内在状态,实现真正的预防性安全。 2. 从“执行”到“协同”:通过理解自然语言,车辆从被动执行命令的机器,变为能理解意图、协同规划的智能伙伴,人车共驾的体验将发生质变。 3. 从“脆弱”到“鲁棒”:音频为视觉提供了关键的冗余和消歧信息,尤其在视觉受限或模糊的复杂交互场景中,极大地提升了系统的整体鲁棒性和安全性。
给智能车装上“耳朵”,不是为了让它变得更“炫酷”,而是为了让它在关键时刻,能像人类驾驶员一样,“眼观六路,耳听八方”,真正守护每一段行程的安全。
🤔 深度思考:你认为“听觉智能”最先会颠覆哪个汽车场景?是提升高速自动驾驶的鲁棒性,还是彻底改变城市人车混行路口的通行效率?欢迎在评论区留下你的真知灼见!
💝 支持原创:如果这篇近5000字的硬核解读,帮你洞见了智能驾驶的未来一角,点赞 + 在看 就是对我最大的支持!分享 给你身边对技术感兴趣的朋友吧!
🔔 关注提醒:点击右上角关注,设为星标,第一时间获取最前沿、最深度的AI技术拆解!
#AI技术 #自动驾驶 #多模态AI #人机交互 #论文解读 #智能座舱
参考
LOOKING AND LISTENING INSIDE AND OUTSIDE: MULTIMODAL ARTIFICIAL INTELLIGENCE SYSTEMS FOR DRIVER SAFETY ASSESSMENT AND INTELLIGENT VEHICLE DECISION-MAKING
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 追觅三款SUV亮相外观惹争议,腾势2026狂推12款新车!
- 长城汽车魏牌全新SUV外观曝光
- 56 当自动驾驶撞上人类道德:三份报告如何将一场事故变成整个时代的“数据罗生门”?
- 36万拿下玛莎SUV,5.6秒破百值不值?
- 自动驾驶百年进化史:从遥控车到无人车,中美路线彻底拉开差距
- 不愧为沃尔沃“王牌SUV”,油耗5.8L,喝92油,318马力比2.0T强_1
- 1月中型SUV销量榜单第二名,卖了22626辆,1.6T+7速双离合,92号油随便造
- 2026必等5款长续航纯电SUV!CLTC全超700km,家用硬派豪华全覆盖
- 25万级家用SUV新卷王:激光雷达标配,这谁顶得住?
- 特斯拉Cybercab量产:自动驾驶的“iPhone时刻”到来,万亿市场如何掘金?
