ResWorld:端到端自动驾驶的时序残差世界模型(北航&中关村实验室)
- 2026-02-23 13:36:49

点击下方卡片,关注“自动驾驶之心”公众号
作者 | Jinqing Zhang等
编辑 | 自动驾驶之心
本文只做学术分享,如有侵权,联系删文
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
面向驾驶场景的世界模型具备的综合场景理解能力,显著提升了端到端自动驾驶框架的规划精度。然而,对静态区域的冗余建模以及与轨迹间缺乏深度交互,限制了世界模型发挥其全部效能。本文提出时间残差世界模型(TR-World),该模型聚焦于动态目标建模任务。通过计算场景表征的时间残差,无需依赖检测与跟踪任务即可提取动态目标的信息。时间残差世界模型仅将时间残差作为输入,从而能更精准地预测动态目标未来的空间分布。将该预测结果与当前鸟瞰图(BEV)特征中包含的静态目标信息相结合,便可得到准确的未来鸟瞰图特征。此外,本文提出未来引导的轨迹精修(FGTR)模块,实现了由当前场景表征预测得到的先验轨迹与未来鸟瞰图特征之间的交互。该模块不仅能利用未来道路状况对轨迹进行精修,还能为未来鸟瞰图特征提供稀疏的时空监督,防止世界模型发生坍缩。在nuScenes和NAVSIM数据集上开展的全面实验表明,本文提出的ResWorld方法取得了当前最优的规划性能。
论文链接:https://arxiv.org/abs/2602.10884 项目主页:https://github.com/mengtan00/ResWorld.git
一、背景回顾
端到端自动驾驶框架是近年来涌现的重要研究方向,为自动驾驶应用提供了兼具成本效益与高可扩展性的解决方案。传统自动驾驶系统通常先执行环境感知任务,包括三维目标检测、地图分割以及语义占据预测等;随后通过基于规则的方法或独立的深度神经网络(DNN)模型融合多维度的感知结果,生成本车的未来行驶轨迹。与之不同,端到端自动驾驶框架将上述多项任务整合至单个模型中,这种设计不仅减少了从原始数据到最终规划结果的信息损失,还能实现各模块间的协同优化,因此对复杂驾驶场景具备更强的适应性。
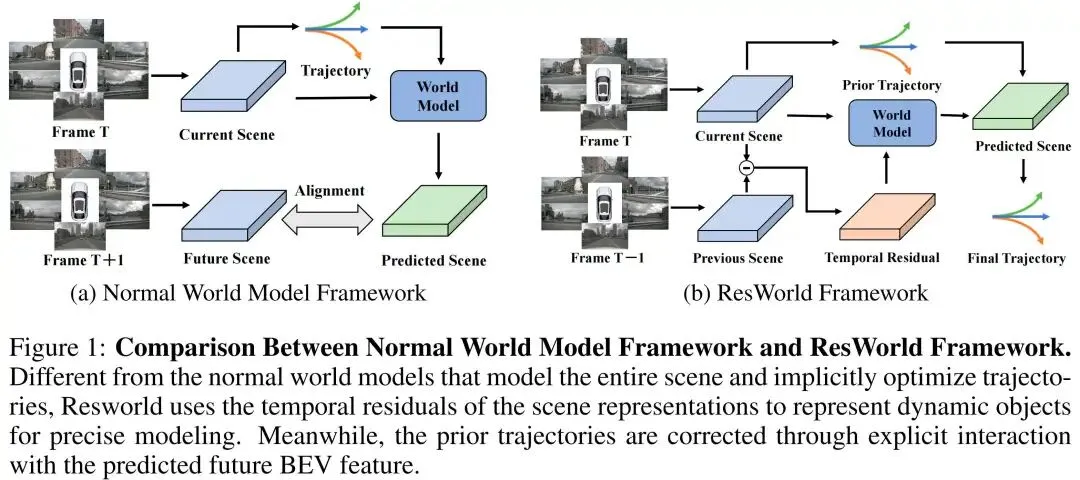
近年来,由于训练多个感知和预测模块需要高昂的标注成本,多款端到端自动驾驶方法采用世界模型替代这些辅助任务模块。如图1a所示,将未来场景预测作为代理任务,世界模型框架能有效增强模型对驾驶场景的理解与建模能力,进而提升规划精度。但场景表征中的大部分信息来自地面、建筑等静态目标,这类目标在未来场景中可直接保留,无需进行冗余建模;而车辆、行人等动态目标则需要更精细的建模,却难以脱离感知任务从环境中精准识别。此外,现有方法中,轨迹与世界模型预测的未来场景表征之间缺乏深度交互。
为解决上述问题,本文提出如图1b所示的时间残差世界模型(TR-World),能够对动态目标进行精准建模并预测得到准确的未来场景表征。首先,将不同时间戳的鸟瞰图特征转换至当前鸟瞰图的坐标系中,并利用相同的空间注意力掩码提取其稀疏场景查询;随后,将相邻时间戳的场景查询相减,得到场景查询的时间残差。该时间残差表征了同一位置在不同时间戳的变化,因此可用于表示场景中的动态目标。在预测未来鸟瞰图特征时,模型仍采用当前鸟瞰图坐标系,这使得当前鸟瞰图特征可直接刻画静态目标的未来分布,从而避免对静态目标的冗余建模。时间残差世界模型仅对时间残差进行处理,并将预测得到的动态目标未来空间分布映射至当前鸟瞰图特征上,最终得到对未来鸟瞰图特征的准确预测。
为充分利用预测得到的未来鸟瞰图特征,本文进一步提出未来引导的轨迹精修模块。首先,利用一系列路点查询表示本车的未来行驶轨迹,其中每个查询对应本车在某一未来时间戳的位置;由路点查询解码得到先验轨迹后,将该轨迹作为一组参考点,引导路点查询与未来鸟瞰图特征进行交互。该操作能有效验证先验轨迹是否会与其他目标发生碰撞或偏离可行驶区域,从而对先验轨迹进行修正,提升规划性能。同时,未来引导的轨迹精修模块还能为未来鸟瞰图特征施加稀疏的时空监督,有效缓解世界模型坍缩问题。值得注意的是,若利用任意未来时间戳的真实标签对未来鸟瞰图特征进行监督,会丢失其他时间戳下动态目标的空间分布信息;因此,不施加监督反而能让模型自主优化未来鸟瞰图特征,并保留其中的关键信息。
本文将上述提出的模块整合为一款全新的端到端自动驾驶模型——ResWorld。在nuScenes和NAVSIM基准数据集上的实验表明,ResWorld取得了当前最优的规划精度。本文的研究贡献可总结如下:
采用当前鸟瞰图坐标系表示世界模型预测的未来鸟瞰图表征,摒弃了对静态目标的冗余建模; 利用场景表征的时间残差提取动态目标信息,无需依赖辅助任务;时间残差世界模型对时间残差进行处理,实现对动态目标未来空间分布的预测; 提出未来引导的轨迹精修模块,通过先验轨迹与未来鸟瞰图特征的交互提升规划精度,同时防止世界模型坍缩; ResWorld在nuScenes和NAVSIM基准数据集上取得了当前最优的实验结果,验证了本文所提框架的有效性。
二、ResWorld算法详解
先验轨迹预测
要提取鸟瞰图(BEV)特征的时间残差,要求鸟瞰图特征具备较高的几何质量,这有助于实现不同时间戳下鸟瞰图特征的空间对齐。因此,本文选用GeoBEV作为模型基础,该方法能高效生成高几何质量的鸟瞰图特征。如图2所示,将各时间戳的多视角图像转换为鸟瞰图特征,得到特征集合。其中为当前时间戳的鸟瞰图特征,、、分别为特征的通道数、高度和宽度维度,为历史时间戳的数量。本文借鉴BEVDet4D(Huang & Huang, 2022)的方法,将全部转换至的坐标系中,并通过下述公式完成特征融合:
本文采用SSR的规划模块实现无感知规划。首先通过令牌学习器(TokenLearner)模块对稠密的融合特征进行处理,得到个稀疏场景查询特征,其计算方式为:
其中表示生成空间注意力图的操作,为全局平均池化操作。对执行自注意力操作以进一步提取特征信息:
本文采用一组路点查询特征表征自车的未来状态,其中为需要预测的未来时间戳数量。对路点查询特征与融合场景查询特征执行交叉注意力操作后,通过多层感知机(MLP)解码得到先验轨迹,计算公式为:
其中的每一行对应自车在某一未来时间戳的坐标。
时间残差提取
由于共享的坐标系,因此这些特征表征了同一场景在不同时间戳下的信息。通过计算该特征集合的残差,可从场景中提取动态目标的相关信息。
融合特征包含了不同时间戳的空间信息,可利用其预测出聚焦于动态目标区域的空间注意力图。对每个时间戳的鸟瞰图特征,通过该空间注意力图进行加权处理,提取稀疏场景查询特征,公式为:
得到稀疏场景查询特征集合后,将相邻时间戳的场景查询特征相减,得到时间残差特征集合,计算过程如图2所示。
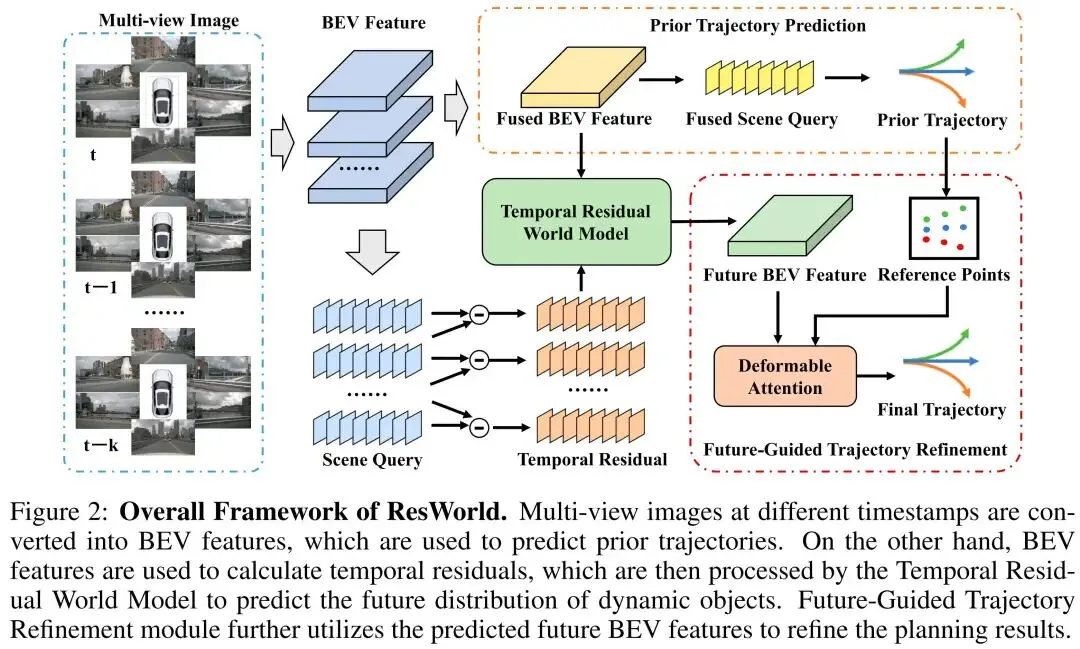
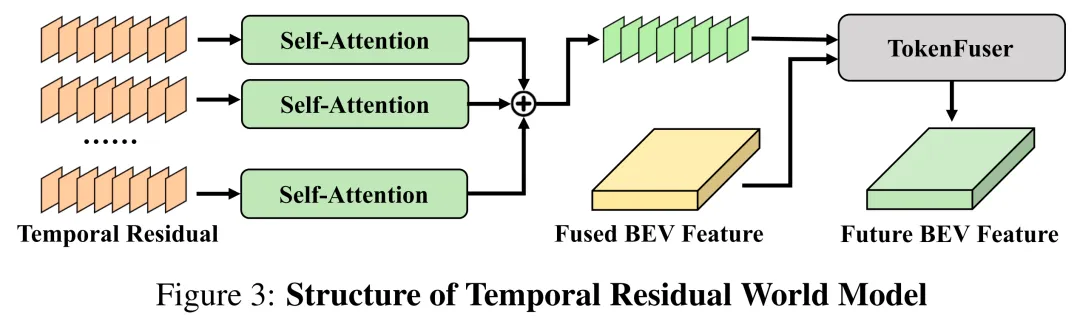
时间残差世界模型
以往应用于端到端自动驾驶的世界模型不会区分场景中的动态目标与静态目标,而是投入相同的建模资源预测二者的未来空间分布。但如果在预测未来鸟瞰图特征时仍采用的坐标系,静态目标的空间分布可视为保持不变。因此,融合特征可直接作为静态目标的未来表征,无需额外建模。此外,对静态目标的场景理解在先验轨迹预测阶段已完成,无需世界模型参与这一过程。
为避免对静态目标的冗余建模,让世界模型更聚焦于动态目标的建模任务,本文提出如图3所示的时间残差世界模型(TR-World)。该模型仅将时间残差作为输入,实现对动态目标未来空间分布的预测。具体而言,对每个时间残差特征执行自注意力操作以提取信息,再对不同时间戳的处理结果进行累加,得到动态目标的未来表征,计算过程为:
需要将映射至鸟瞰图特征空间,以精准还原动态目标的未来空间分布。本文采用okenFuser——令牌学习器的逆变换,以为基础对进行特征扩展,公式为:
其中MLP将映射至维度,表示结合矩阵转置与矩阵乘法的运算,最终输出的即为预测的未来鸟瞰图特征。
未来引导的轨迹精修
现有端到端自动驾驶方法通常以间接方式利用世界模型优化规划性能:将未来场景表征的预测作为代理任务,提升模型对自动驾驶场景的整体理解能力。但预测得到的未来场景表征可作为轨迹规划的重要参考,目前这一价值尚未得到有效挖掘。另一方面,当未来场景表征缺乏任何辅助任务的监督时,难以避免世界模型发生坍缩——即模型会将多样的驾驶场景映射为完全相同的场景表征。
为解决上述问题,本文设计了未来引导的轨迹精修(FGTR)模块。如图2所示,该模块在路点查询特征与未来鸟瞰图特征之间执行可变形注意力操作,并将先验轨迹作为上的参考点。随后通过多层感知机解码得到最终轨迹,计算公式为:
由于路点查询特征中的每个查询向量对应自车在某一未来时间戳的状态,FGTR模块能以先验轨迹为依据,从未来鸟瞰图特征中提取自车周边的未来环境信息。利用该信息可检验先验轨迹是否会与其他目标发生碰撞或偏离可行驶区域,进而及时对进行修正。这一过程不仅充分利用了的特征信息,还为其施加了稀疏的时空监督:参考点的坐标提供了空间监督,而路点查询特征对应的不同时间戳则提供了时间监督。该监督机制能促使精准表征跨时间的空间信息(如动态目标的未来位置),从而有效防止世界模型坍缩。
损失函数
模型训练阶段,本文仅对先验轨迹和最终轨迹采用L1损失进行优化,损失函数表达式为:
其中为自车轨迹的真实标签。与常规世界模型不同,本文未利用真实的未来数据生成标签对进行监督。该方式能让保留多个未来时间戳下动态目标的空间分布信息,而非局限于单一时间戳。实验结果证实,不对施加监督能让模型取得更优的规划性能。
三、实验结果分析
主要实验结果
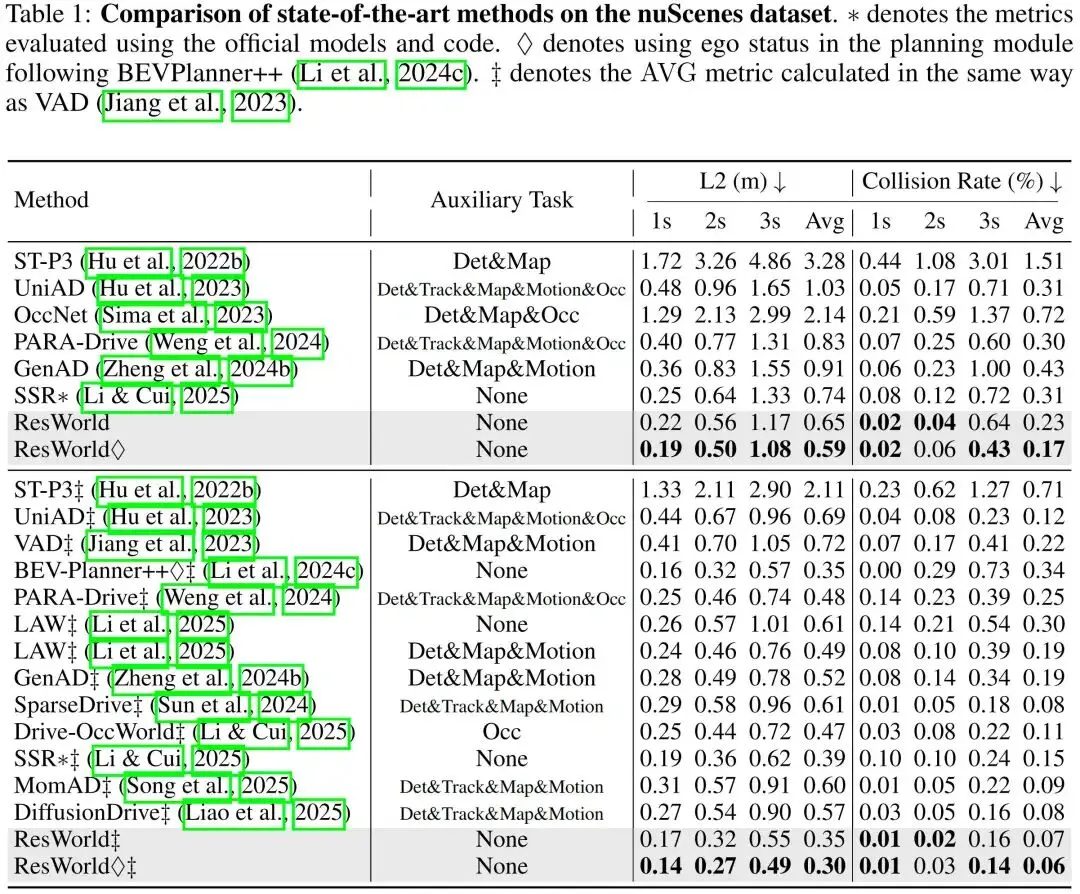
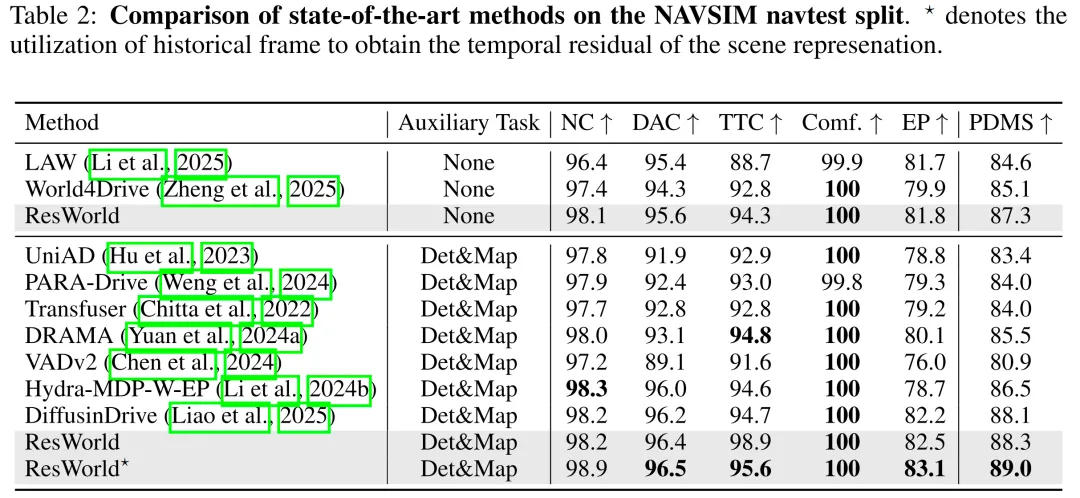
nuScenes数据集:本文在nuScenes基准数据集上,将ResWorld与现有端到端自动驾驶方法进行全面对比,结果如表1所示。可以发现,ResWorld取得了当前最优的规划精度:在规划模块中不融入自车状态时,本文方法的性能优于GenAD、DiffusionDrive等依赖辅助感知/预测任务实现场景理解的方法,也比SSR、LAW等无辅助任务、完全依靠世界模型进行场景理解的方法更具优势;在融入自车状态以提升先验轨迹预测精度时,ResWorld的最终规划精度得到大幅提升,性能超越BEVPlanner++。这表明本文提出的框架具备鲁棒的场景理解能力,能避免因过度依赖自车状态导致的模型过拟合问题。
NAVSIM数据集:本文在NAVSIM基准数据集上对ResWorld的闭环规划精度进行评估,结果如表2所示。为与未利用历史帧数据的方法进行公平对比,本文将目标检测的智能体查询特征替代时间残差输入至TR-World,即便如此,ResWorld仍取得了88.3%的PDMS当前最优规划精度,性能超越Hydra-MDP和DiffusionDrive;在未使用检测、鸟瞰图分割等辅助任务时,本文方法的性能也优于LAW、World4Drive等基于世界模型的方法。此外,融入历史帧数据的完整ResWorld模型取得了89.0%的PDMS,验证了时间残差在表征驾驶场景动态信息方面的有效性。
消融实验
组件有效性:本文通过实验验证时间残差世界模型(TR-World)和未来引导的轨迹精修(FGTR)模块的有效性,结果如表3所示。仅使用TR-World并采用SSR的方式隐式优化轨迹时,模型的场景理解能力得到显著提升,规划精度也随之提高;仅使用FGTR模块并利用当前鸟瞰图特征精修先验轨迹时,也能有效提升轨迹的预测质量;而将TR-World与FGTR结合后,模型的规划性能得到进一步优化。在规划模块不融入自车状态时,两个模块共同作用使基线模型的平均L2误差降低8.4%,平均碰撞率降低25.8%;在融入自车状态时,两个模块让基线模型的平均L2误差降低9.2%,平均碰撞率降低39.3%。
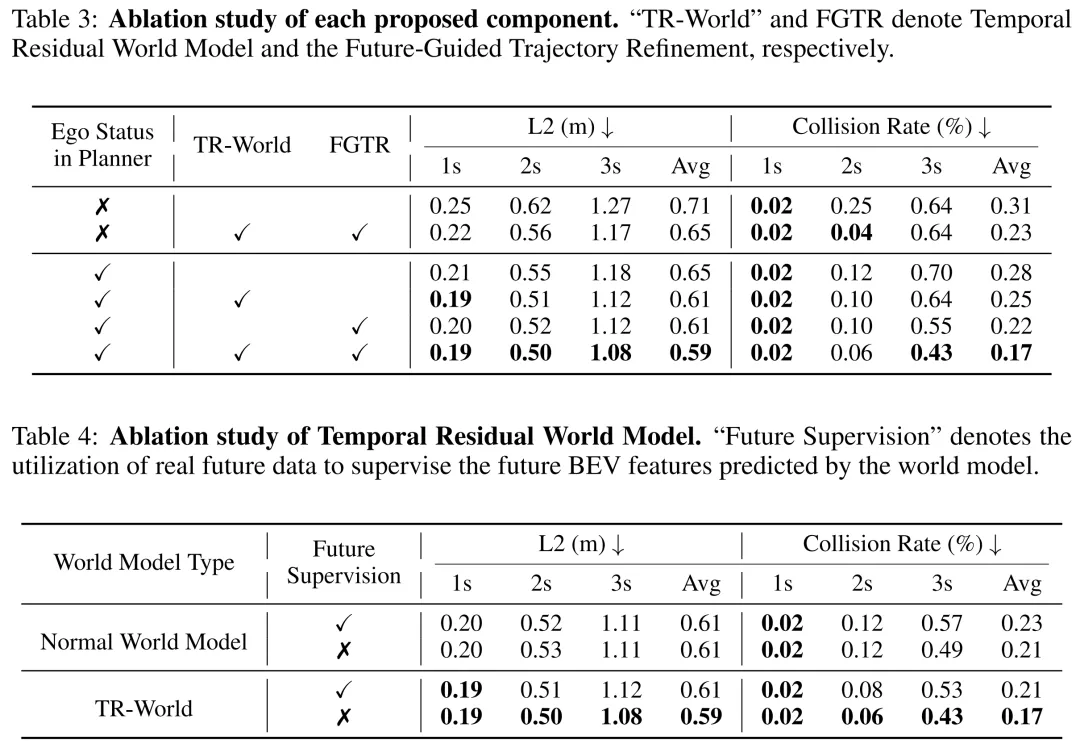
时间残差世界模型:表4对比了TR-World与常规世界模型的性能,同时评估了利用真实未来数据对世界模型预测结果进行监督所产生的影响。结果表明,以时间残差为输入、聚焦于动态目标建模的TR-World,能比常规世界模型预测出更精准的未来鸟瞰图特征,进而实现更优的规划精度。此外,FGTR模块的稀疏时空监督作用,能让TR-World预测出未来一段时间内的场景信息,而非局限于时间戳的单一场景。因此,若利用时间戳的数据进行未来监督,反而会导致未来鸟瞰图表征丢失更丰富的时间信息,造成规划性能下降。与之相反,常规世界模型将大部分建模资源投入到静态目标的冗余建模中,对动态目标的预测精度较低,这也解释了为何未来监督对常规世界模型的性能几乎无影响。
未来引导的轨迹精修模块:为验证FGTR模块在缓解世界模型坍缩方面的作用,本文对世界模型预测的未来鸟瞰图特征进行可视化,结果如图4所示。可以发现,未搭载FGTR模块的世界模型,在不同驾驶场景下预测的未来鸟瞰图特征几乎无差异,且无法完整表征场景的空间信息;而FGTR模块通过让先验轨迹与预测的未来鸟瞰图特征在特定空间点进行交互,能促使世界模型预测出精准的空间信息,从而有效防止世界模型坍缩。

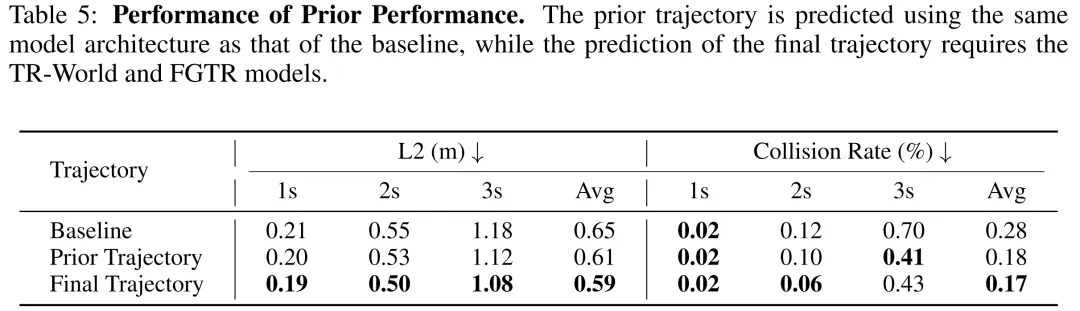
先验轨迹性能:本文还对先验轨迹的预测性能进行了评估,结果如表5所示。可以发现,尽管生成先验轨迹的模型结构与基线模型完全一致,但其预测精度相较于基线模型仍取得了显著提升。这是因为TR-World和FGTR模块对场景的鸟瞰图特征进行了有效优化,进而提升了基础模型的规划能力。这一结果也为模型设计提供了新思路:训练阶段利用更大规模的TR-World和FGTR模块以得到最优的鸟瞰图特征,推理阶段则直接输出先验轨迹,以提升模型的推理效率。
可视化分析
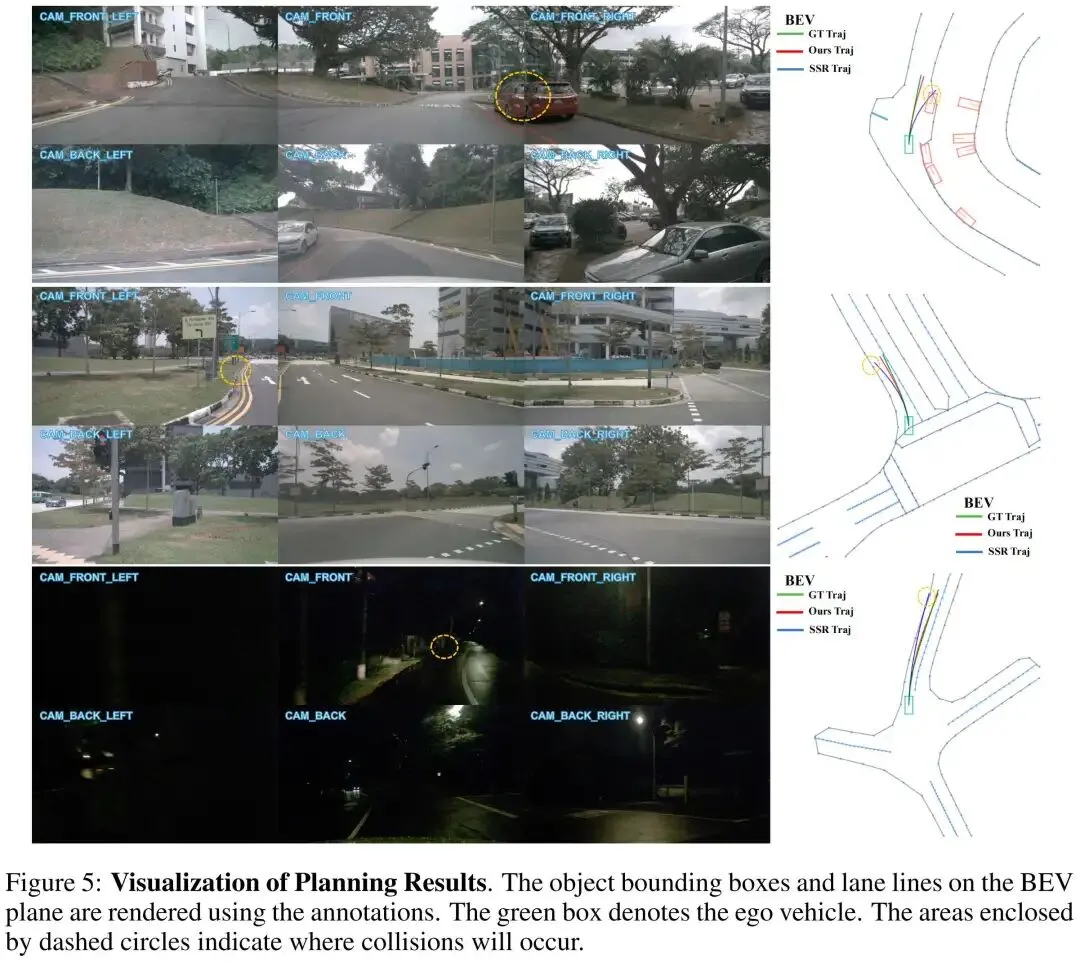
本文将ResWorld与SSR的规划轨迹进行定性对比,结果如图5所示。可以发现,本文方法预测的轨迹能有效规避与其他车辆或路缘石的碰撞,体现出更强的场景理解能力。
四、结论
本文提出的ResWorld采用了全新的时间残差世界模型框架,通过计算场景表征的时间残差捕捉动态目标的信息,让由时间残差驱动的世界模型能够明确聚焦于动态目标未来空间分布的预测,同时摒弃了对静态目标的冗余建模。此外,通过未来引导的轨迹精修模块,模型利用预测得到的未来鸟瞰图特征对先验轨迹进行修正,降低了驾驶事故的发生概率;先验轨迹与未来鸟瞰图特征之间的时空交互,还能对隐式世界模型施加稀疏监督,有效缓解模型坍缩问题。ResWorld在nuScenes和NAVSIM两大基准数据集上均取得了当前最优的规划性能。
局限性与未来工作
尽管TR-World对动态目标的细微运动表现出比现有世界模型(如SSR、LAW)更高的敏感性,但该模型无法通过时间残差充分捕捉潜在动态目标(如行人、停放的车辆)的信息,导致这类目标只能与静态目标一起由先验轨迹预测分支处理。本文的未来研究工作将聚焦于如何通过粗粒度感知从场景中提取潜在动态目标的信息,并对其进行预防性建模,从而进一步提升框架规划结果的安全性。
自动驾驶之心


求点赞

求分享

求喜欢

随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 视觉独大的自动驾驶,缺了关键一环 | 智能驾驶的耳朵,能多救一条命!
- 小鹏G02全新SUV谍照曝光,定位中大型SUV.
- 自动驾驶中的传感器技术47——Radar(8)
- 丰田铂智7将于3月上市!中大型纯电轿车,价格锚定20万级,剑指比亚迪汉
- 合资轿车销冠!最新设计语言,媲美日产N7,全新轩逸将于2月24日上市!
- 宝马X5,豪华SUV的常青树还能火多久?
- 40万买豪华SUV,为何聪明人都选雷克萨斯RX350h
- 全新宝马iX4要来了,新能源SUV,两种动力配置可选,外形有些像卡宴,很漂亮!
- 斯巴鲁调研用户是否愿买手动挡SUV
- 长安启源Q05紧凑型SUV:精简前脸+个性车身设计
