一场雨夜,老司机一眼就能分辨出街头的危险元素,而自动驾驶的AI却还在纠结每一块路面是否都是障碍。在这个让人又期待又焦虑的AI时代,机器的视觉到底能不能真正替人“看懂”世界?这不仅仅是算力堆积,更是对“理解力”的深度追问。最近,清华大学智能产业研究院的研究在Nature子刊发表,将这个难题抛到了桌面上:自动驾驶算法的视觉注意力,和人类司机的决策方式有着天壤之别。
自动驾驶AI从一开始就以“捕捉每个像素”的姿态示人,在规则道路上表现得相当稳妥。它不会漏掉任何细节,但这种全面扫描其实是一种机械式的观察。机器对远处的广告牌和天上的云朵同样认真,但却无法判定哪些东西是真正影响行车安全的“关键点”。这种“万物皆平等”的视角,使得AI面对罕见场景总是感到迷茫,比如塑料袋飘过会紧急刹车,而隐身行人可能完全不被发现。实际上,人类司机的常识和意图,才是安全驾驶不可或缺的底层逻辑。
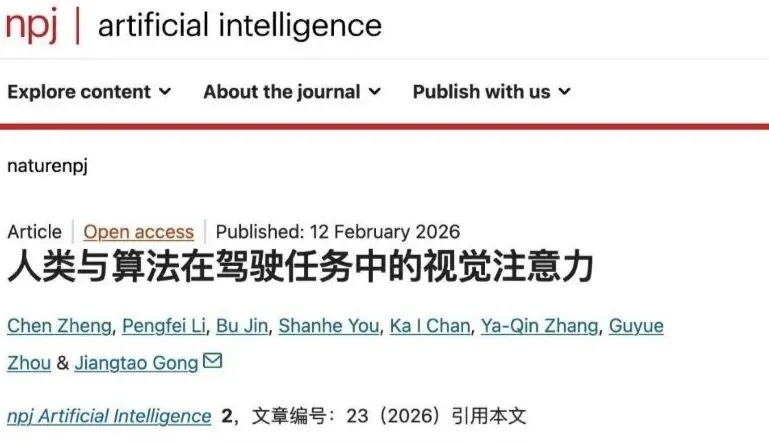
人类司机的看路方式是“看懂”为先:当遇到复杂路口时,目光先快速扫描(类似雷达搜查),锁定重点后马上进入语义分析阶段。比如,一个手持手机的行人正欲过马路,司机会关注他的移动方向、行动速度甚至情绪状态,判断其危险等级。随后,视线回归整体环境,再次确认决策安全。这种动态分配注意力的过程,把关键目标的语义价值最大化,这正是AI始终学不会的“老司机智慧”。
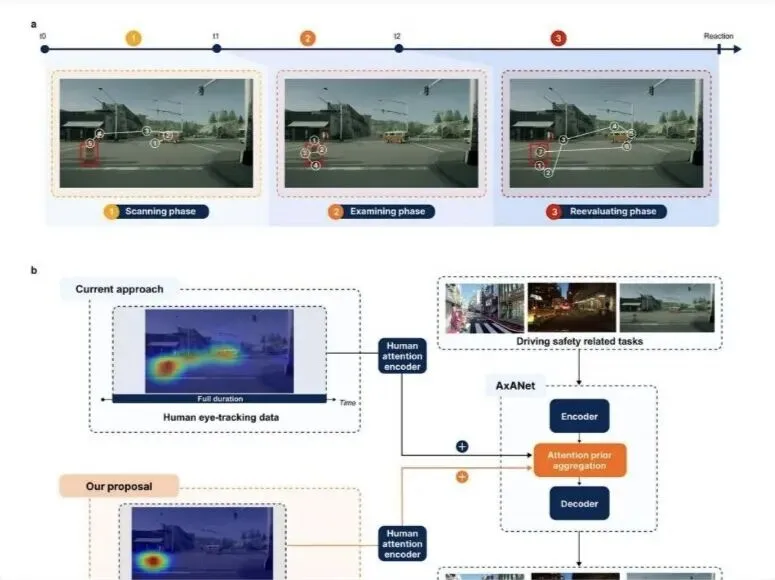
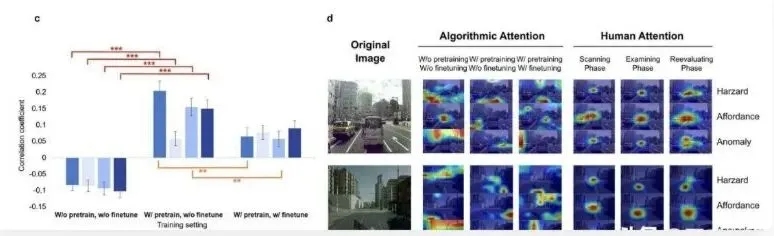
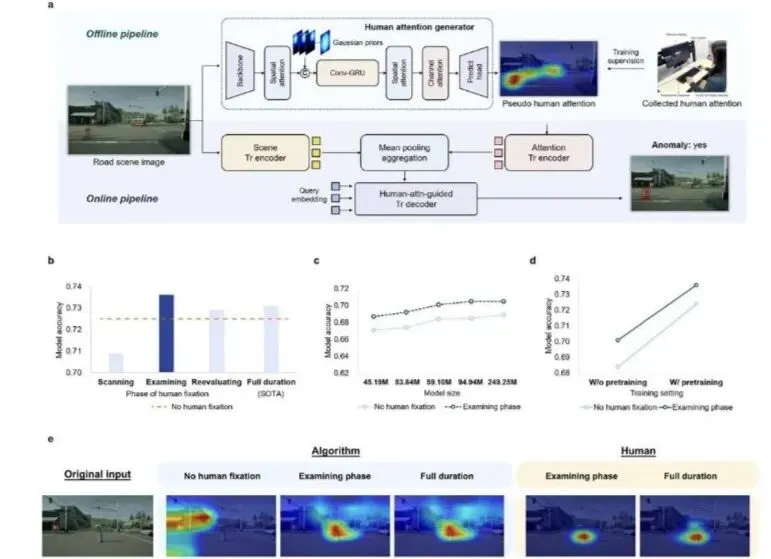
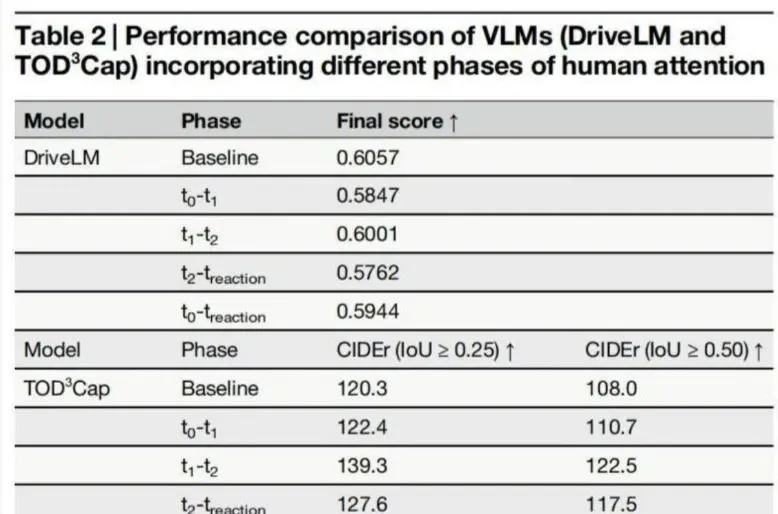
清华团队把人类司机这三个阶段的眼动数据分别导入自动驾驶模型,结果发现,模仿人类的初步扫描反而降低AI的表现。原因很直接:人类受限于生理结构,只能串行浏览,而AI原本具备同时关注所有角落的优势。强迫机器像人那样“顺序扫描”,本质是在削弱它的眼力。反过来,给AI注入司机们锁定关键目标时的关注数据——即“语义审视”——却使算法在异常检测和运动规划方面大幅提升。最简单的说法就是:AI懂得了“哪儿才是最重要的地方”,学会了老司机的注意力分布。
不过,不是所有人类注意力输入都能让AI变得更聪明。在高层逻辑推理任务里,模型已经能通过大量预训练填补“推理鸿沟”,人类的关注点没能带来多少提升。例如,德国宝马集团测试自动驾驶AI时,也发现辅助决策中人类注意力并无明显作用。而在细粒度视觉接地任务上——比如夜晚识别模糊行人、复杂场景下精确定位目标,来自人类司机深度审视阶段的数据改变了模型表现,帮助AI弥补了将抽象逻辑与具体像素精准对接的“接地鸿沟”。同理,在日本东京近期自动驾驶出租车实验中,算法加入行车经验的语义关注点后更少出现误判和不必要的刹车,有效提升运营效率。
自动驾驶领域风险随时存在:如果一味追求全覆盖和数据堆积,最终可能只是让机器陷入“看但不懂”的怪圈。美国凤凰城曾有无人出租车因为过度依赖数据处理,把街头艺术墙误判成行人,造成不必要的停车,这就是典型的反例。要想让自动驾驶变得可靠、经济并且安全,仅靠规模化算力并不足够,反而是适度引入人类认知过程,特别是司机在决策关键时刻聚焦的“语义点”,更容易让AI听懂世界、理解风险、解释决策。
未来,自动驾驶不需要成为全知全能的“上帝”,而是要像老司机一样,清楚抓住路上那些最敏感、最有意义的细节。与其一味相信黑箱模型能包治百病,不如把人类的经验巧妙注入其中,让机器学会“看懂”那些真正决定安全的瞬间。这也是普通司机和技术迷更愿意信赖的自动驾驶路径。