1、Xiaomi OneVL:让大模型推理“既快又准”
今年 3 月,小米正式发布全新小米 XLA 认知大模型架构,标志着小米辅助驾驶技术路线从“感知与模仿”迈向“理解与推理”。相比传统 VLA,XLA 强调更丰富的多模态认知输入,以及更强的场景认知、行为推理与真实世界理解能力。
在 XLA 的技术方向下,一个核心问题随之浮现:当大模型具备了推理能力,如何让这种推理既快又准?
行业过往的解决方案都有明显的缺陷:显式思维链(CoT)能显著提升轨迹规划质量,但逐 token 生成带来的额外时延,也对真实驾驶场景中的实时决策提出了更高挑战;而跳过推理直接输出答案,又会丢失关键的因果判断能力。
为了解决这些缺陷,此前行业内提出了潜空间思维链(Latent CoT)作为核心推理机制——用高维机器语言替代逐字生成的文本推理,在保持认知质量的同时大幅压缩推理时延。
而今天,小米技术研发团队在 Latent CoT 的基础上进一步探索自动驾驶大模型中的潜空间推理问题,正式推出——Xiaomi OneVL:一步式潜空间语言视觉推理框架。
作为 XLA 架构中 Latent CoT 能力的首次学术验证,Xiaomi OneVL 是首个在精度上超越显式思维链、在速度上对齐“仅答案”预测的潜在推理方案,并实现了 VLA 与世界模型的统一。
通过“语言推理 + 视觉未来预测”的双重监督,Xiaomi OneVL 将可解释性与世界模型的未来预测能力统一到 latent reasoning 中,为自动驾驶大模型探索出一条新的精度—效率平衡路径。
从这个意义上说,Xiaomi OneVL 进一步验证了 XLA 架构方向的技术潜力:真正面向现实世界的辅助驾驶,不只要看见当下,更要理解因果、预判未来,并在有限时间内完成高质量决策。
从家庭场景的具身智能到城市道路的辅助驾驶,小米正推动智能技术向“可用、可信、可扩展”的现实世界稳步迈进,为小米“人车家全生态”注入核心技术动能!
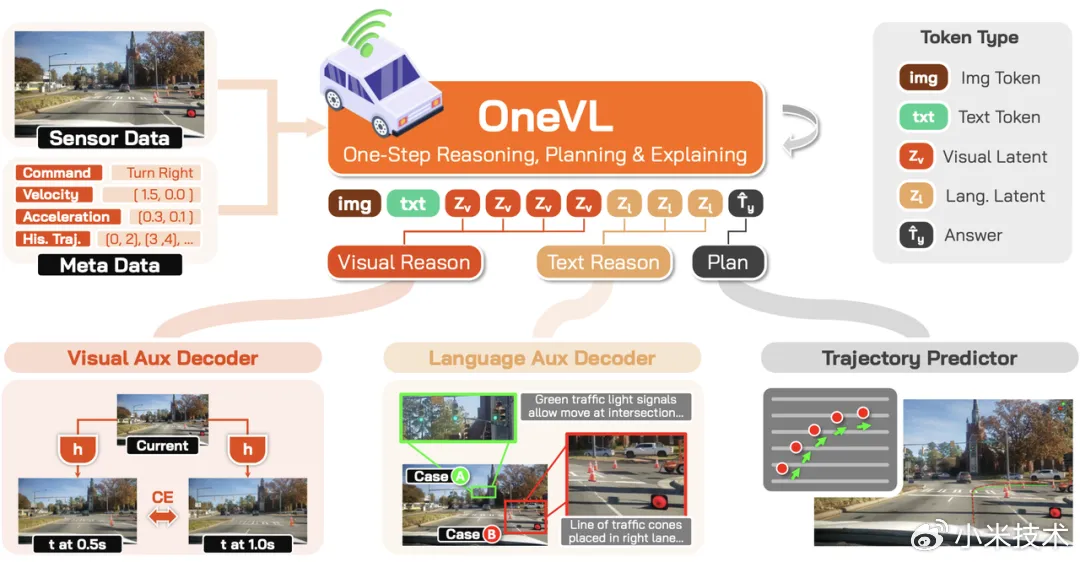
2、三项关键技术,统一 VLA、世界模型、潜空间推理三大技术路线
过去,VLA 和世界模型是自动驾驶领域两条相对独立的技术路线:VLA 专注于理解场景并输出驾驶动作,世界模型专注于预测未来场景的演变。Xiaomi OneVL 通过潜空间推理,首次将两者统一到同一套框架中。
它的核心洞察是:自动驾驶要压缩的,不只是语言推理,而是对未来世界变化的理解。 驾驶决策真正依赖的,并不只是“前方有车”“道路变窄”这样的语义描述,而是车辆运动、道路几何、障碍物演变等时空因果信息。压缩语言,丢掉的恰恰是最关键的因果结构;而压缩成“对未来视觉世界的预测”,才保留了真正决定驾驶结果的东西。
基于这一洞察,Xiaomi OneVL 提出三项关键技术。简单来说:让模型用自己的“内部语言”思考、让它学会预测未来画面、并把整个推理过程压缩到一步完成。
- 双模态 latent token,各司其职:视觉 latent token 编码“场景的物理因果结构”,语言 latent token 编码“驾驶意图的语义表达”,让模型“在心里想清楚”,而不是“边说边想”。
- 双辅助解码器,训练时用、推理时丢:视觉解码器预测未来 0.5s / 1s 的画面,让模型同时具备世界模型的未来预测能力;语言解码器重建人类可读的思维链文字,保障可解释性——两个解码器在训练中提供双重监督信号,推理时全部移除,零额外开销;
- 「预填充式」一步推理,快到极致:推理时丢掉两个解码器,所有 latent token 直接预填充进上下文,一次并行完成,延迟和“仅答案”模型几乎一致,比显式 CoT 最高快 2.3 倍。
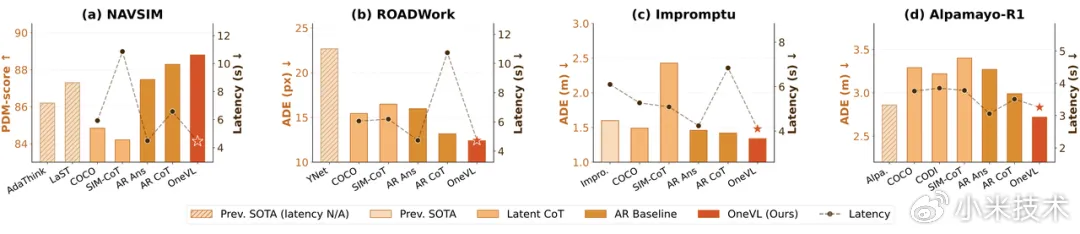
3、多基准全面 SOTA,刷新潜在推理方法性能上限
在涵盖感知、推理与规划的多个主流基准上,Xiaomi OneVL 全面刷新了潜在推理方法的性能上限:
- 在 ROADWork、Impromptu、Alpamayo-R1 三项基准上均达到 SOTA,并在 NAVSIM 上取得优越性能,PDM-score 达到 88.84,首次在潜空间推理中超越显式 CoT(88.29);
- 目前唯一在所有基准上超越显式自回归 CoT 的隐式推理方法;
- 挂载 MLP 回归头变体,延迟进一步压到 0.24s(4.16 Hz),仅为 VLA 自回归推理的 5.4%,为量产车端实时部署提供了可行路径。
- 消融实验进一步验证,压缩物理世界的动态信息能带来显著的性能提升。
同时,Xiaomi OneVL 能为模型决策提供语言和视觉双维度的可解释性——既能用文字说明“为什么这样开”,也能用预测画面展示“接下来会发生什么”,将 XLA 所追求的“理解与推理”能力,真正落到了可验证、可解释的工程实践中。







 点亮5分❤
点亮5分❤ 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
