点击下方卡片,关注“人工智能AI与算法”公众号
2025年被称为“VLA上车元年”。到了2026年6月,理想汽车在Livis Day上放出狠话:第四季度马赫VLA智驾能力全面对齐特斯拉FSD V14。小鹏汽车也不甘示弱,第二代VLA已实现从视觉信号到动作指令的端到端直接生成。中国科学院院士欧阳明高更是断言:L4级自动驾驶可能在未来两三年内完成。
VLA,正在以前所未有的速度重塑自动驾驶的底层逻辑。它到底是什么?从哪里来?要到哪里去?今天这篇文章,带你一次性看懂VLA自动驾驶的过去、现在与未来。
一、过去:从“昆虫智能”—“哺乳动物智能”
要理解VLA的颠覆性,必须先搞清楚自动驾驶是怎么一步步走到今天的。用理想汽车CEO李想的话说,自动驾驶经历了三个智能进化阶段。
第一阶段:规则驱动——“昆虫智能”(2021年前后)
最早的自动驾驶,本质上是工程师手写百万行C++代码,通过预设规则应对各类路况。感知、规划、控制各自为政,系统依赖高精地图和人工设定的规则运行。
这套系统的核心逻辑是“匹配规则、机械执行”——优点是稳定可控,缺点是极度僵化。面对未预设的突发场景,系统会直接决策失效。它就像一只被设定好程序路径的蚂蚁:只能在特定场景中爬行,缺乏对环境的真正理解和泛化能力。
第二阶段:端到端AI——“哺乳动物智能”(2023-2024年)
2023年起,行业开始抛弃模块化拆分与人工规则堆砌,搭建“像素输入、动作输出”的全神经网络架构。特斯拉FSD V12是这一阶段的标志性起点。
端到端系统通过海量真实路况数据训练,让AI自主学习行驶决策。它解决了规则算法僵化的问题,大幅提升了平顺性与场景适配性。但致命短板也随之暴露:只有感知能力,没有理解能力。AI能识别障碍物、车道线,却无法理解场景背后的逻辑。
这就好比一只会骑车的猩猩:虽然能完成任务,但并不真正理解交通世界的规律与逻辑。
从“蚂蚁”到“猩猩”,自动驾驶走了将近十年。但真正让机器拥有“人类智能”的,是VLA。
二、现在:VLA时代全面开启
VLA到底是什么?
VLA,全称Vision-Language-Action(视觉-语言-动作)模型。简单来说,它是一个把“看”“想”“做”融为一体的AI系统。
传统自动驾驶是“眼睛看到→大脑思考→手脚执行”的分工协作,每个环节独立运作。而VLA通过一个统一的神经网络,将视觉感知(Vision)、语言推理(Language)和动作执行(Action)在同一个语义空间内完成对齐。
VLA由三个核心组件构成:
VLA解决了什么?
VLA解决了传统自动驾驶最大的痛点:看得懂路况,却不懂路况逻辑。
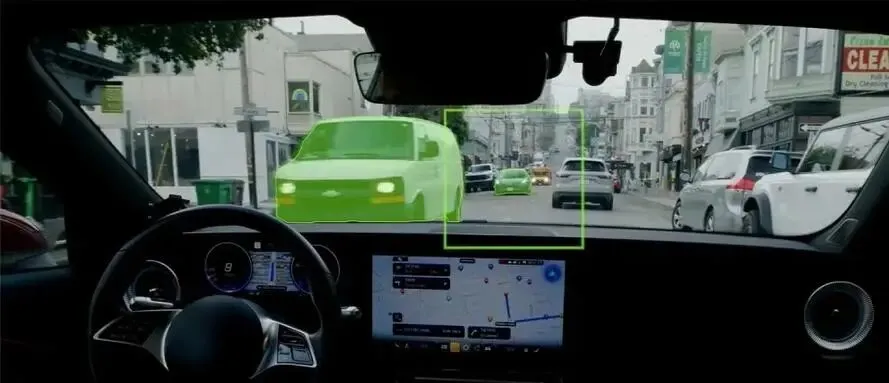
纯视觉端到端模型是“直觉式决策”——看到什么就做什么。而VLA可以像人类司机一样:先识别路况、再理解场景、最后制定策略。它能理解交警手势、提前应对红绿灯变化、识别施工改道中的临时标志。
理想汽车曾展示过一个典型场景:遇到施工改道,传统系统可能因为识别不到预设车道线而“懵掉”,而VLA能理解“前方施工请绕行”这个语义指令,自主规划新路线。
产业格局:群雄逐鹿
进入2026年,VLA已成为自动驾驶行业最主流的技术路线之一。
理想汽车是VLA量产先行者。2025年5月发布VLA司机大模型,2026年6月Livis Day上推出马赫VLA 2.1系统,多模态计算量提升10倍,配备3D ViT感知模型,可视距离提升50%。硬件层面,自研马赫M100芯片单颗算力达1280 TOPS,双芯协同达2560 TOPS。
小鹏汽车则走得更激进。2025年11月发布第二代VLA大模型,创新性地去掉了“语言转译”环节,首次实现从视觉信号到动作指令的端到端直接生成。通过3万卡算力集群训练720亿参数基座模型,第二代VLA已能识别交警手势、提前应对红绿灯。
英伟达在GTC 2026展示自研VLA模型AIpamayo,宣布将在奔驰CLA等车型量产落地。奇瑞汽车通过猎鹰900智驾系统,将VLA引入燃油车领域。
技术阵营也出现明显分化:理想与小鹏主推VLA路径,华为与蔚来倾向世界模型,吉利与Momenta站队世界模型阵营。
三、挑战:VLA并非万能钥匙
VLA虽好,但绝非没有争议。
第一大挑战:推理速度与实时性。 VLA依靠语言模型进行推理,需要经历“视觉→语言→动作”的两次翻译,而翻译就会导致误差,反应也更慢。在高速行驶中,毫秒级的延迟都可能造成事故。有业内人士直言:VLA在未来两三年内的表现可能赶不上一段式端到端。
第二大挑战:算力与工程落地。 VLA模型的参数量动辄数百亿,对车载芯片算力提出极高要求。虽然理想已实现2560 TOPS的芯片算力,但成本与功耗仍是规模化量产的瓶颈。
第三大挑战:VLA是否只是过渡技术? 华为、小米等玩家认为,VLA并不是自动驾驶的终极形态,只是从辅助驾驶走向全自动驾驶的过渡技术。真正的下半场竞争,早已瞄准VLA之后的下一代技术范式。
四、未来:VLA不死,只是进化
那么,VLA之后是什么?
方向一:VLA + 世界模型 = 超越人类
行业已经形成了一个共识:VLA学习“如何行动”,世界模型学习“行动之后世界会如何变化”。
世界模型可以推演未来5至10秒内各目标与智能体的交互行为。小鹏的架构中,第二代VLA从人类驾驶行为中学习“如何行动”,世界模型则通过对未来状态的预测学习“行动之后世界会如何变化”。
黑芝麻智能CEO单记章断言:“VLA加上世界模型,是高阶智能驾驶未来最有可能的技术路线,而且有机会超越人类的驾驶能力。”AlphaZero在围棋领域击败人类,预示着VLA+世界模型同样可能让机器在驾驶领域超越人类。
方向二:从“模态融合”到“物理世界智能建模”
站在2026年的技术节点,头部厂商正朝着跳出VLA的模态融合思维、转向物理世界智能建模的方向发展。VLA的核心是“看懂、读懂、动作”,而下一代自动驾驶技术的核心是“懂规律、会推演、能预判”。
理想汽车已在GTC 2026上发布了下一代自动驾驶基础模型MindVLA-o1,核心变化是将3D空间理解、多模态推理、行为生成整合至同一原生多模态模型框架。
方向三:L4级自动驾驶加速落地
欧阳明高院士预测,L4级自动驾驶可能在未来两三年内完成。L2.9将主导市场2-3年,L3渐进式扩面,L4先在封闭半封闭场景规模化。
有报告显示,VLA模型主导的端到端方案可能至2030年占据L4级市场60%份额。
写在最后
从“蚂蚁”到“猩猩”再到“人类司机”,自动驾驶用不到十年时间走完了人类数百万年的智能进化之路。
VLA不是终点。它是一场从“感知”到“认知”、从“模仿”到“理解” 的范式革命的开端。当机器不仅能看懂世界,还能理解世界、预判世界,那个曾经只存在于科幻电影里的“全自动驾驶”,正在以VLA为支点,一步步成为现实。
2026年被称为“全球自动驾驶开启元年”。而VLA,正是这个元年最硬核的技术注脚。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
