自动驾驶占据感知网络那么厉害,为何仍未全面铺开?
- 2026-06-22 16:08:17
编者语:后台回复“入群”,加入「智驾最前沿」微信交流群
在自动驾驶的感知方案中,占据感知网络(Occupancy Network,简称OCC)近年来成为了行业热点。它不再像传统的检测方法那样,费力地去猜前方是一个行人还是一个消火栓,而是直接把三维空间划分成一个个微小的方块,通过判断这些方块是否被物体占据,来告诉车辆哪里可以开,哪里不能碰。这种从识别物体到感知空间的转变,虽极大地提升了系统对异形障碍物的避障能力,但在实际落地过程中,依然面临着诸多问题。
几何倍增的计算负担如何承受?
算力和内存的巨大消耗上是占据感知网络产业化需要解决的最大的问题。传统的视觉感知只需要在二维图像上画框,或者预测几个关键点,处理的数据量相对有限。
然而OCC需要将整个三维物理空间切分成密密麻麻的体素网格。如果想让感知结果更精细,就需要把网格切得更小。但问题在于,分辨率每提高一倍,三维空间的体素数量就会呈立方级增长。这种指数级的几何爆炸,对于算力资源本就紧张的车载芯片来说,无疑是一场灾难。

图片源自:网络
为了在实时性和精度之间找到平衡,必须在算法架构上绞尽脑汁。如果直接处理全量的高分辨率体素,芯片的内存带宽很快就会被占满,导致系统延迟大幅增加。
目前的折中方案是采用非均匀的网格划分,或者引入多尺度特征融合的技术,在关键区域使用高精细度,在远端或次要区域则保持模糊。即便如此,如何在有限的毫秒级时间内,完成海量空间数据的特征提取与推理,依然是大规模量产时最头疼的硬件适配问题。
二维向三维转换的视差怎么填补?
占据感知网络产业化另一个核心的技术痛点在于如何将多个摄像头的二维图像准确地投影到三维体素空间中。摄像头本质上是二维传感器,它能告诉你像素在画面中的位置,但丢失了最关键的深度信息。
OCC网络需要通过算法将不同视角的图像特征提取出来,然后像拼图一样还原成一个立体的世界。这个过程被称为视图转换,目前主流的做法是利用预测深度图或者通过注意力机制进行跨空间的关联。

图片源自:网络
即便如此,这种转换过程也充满了不确定性。由于摄像头之间存在遮挡、光照不均或者安装误差,算法在进行特征采样时,很容易出现错位或者拉伸变形。尤其是在面对远距离物体或者雨雾天气时,深度的预测精度会大幅下降。
如果深度估算错了,那么在三维空间里,原本在路边的电线杆可能会被错误地投影到路中间,直接导致车辆误刹车。如何确保这种跨维度的特征映射既快速又精准,是决定感知系统是否可靠的关键门槛。
谁来给海量的三维方块打标签?
在AI训练的过程中,高质量的数据标注是模型的基石。对于传统的物体检测模型,标注员只需要在图片上给车或人画个框,工作量尚可接受。但对于占据感知网络来说,标注任务变得异常繁重且复杂。
标注人员不仅要确认物体的位置,还要给三维空间里每一个被占据的小方块打上标签,并指明它是路面、路边石还是其他障碍物。这种纯人工的标注方式成本极高,效率极低,根本无法支撑模型动辄数千万帧的训练需求(相关阅读:自动驾驶占用网络还需要数据标注吗?)。
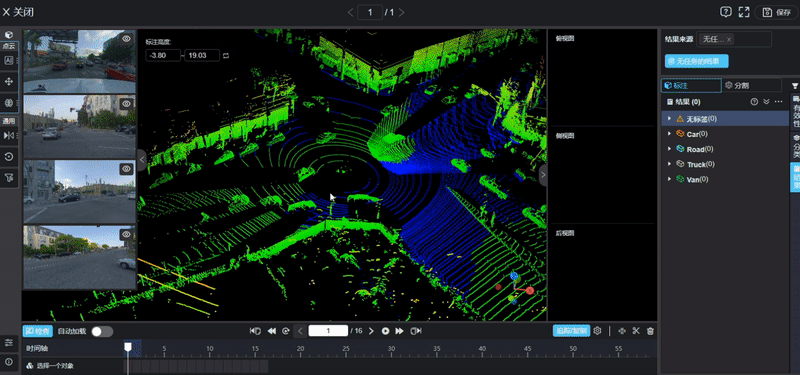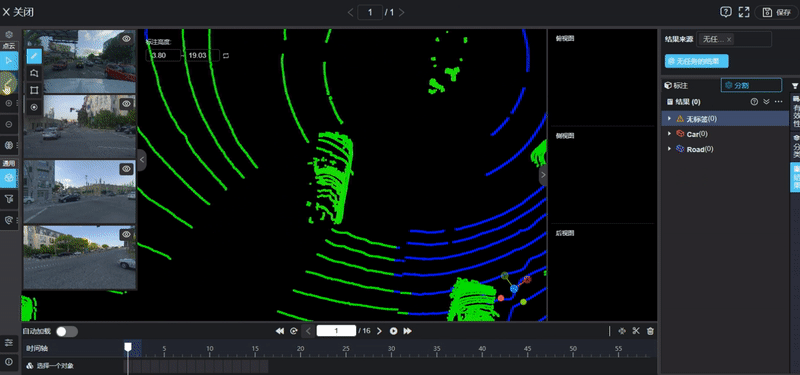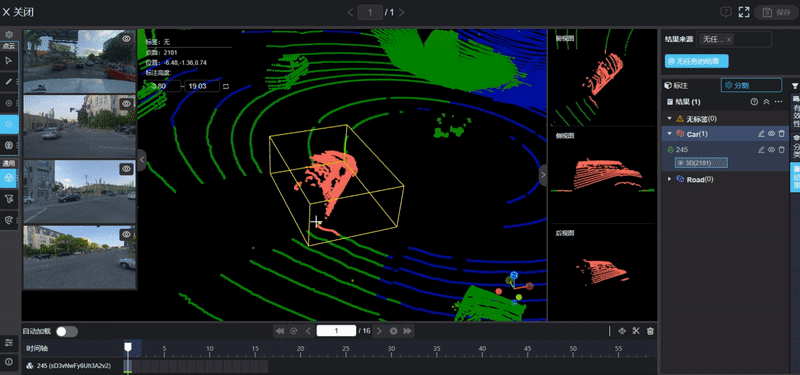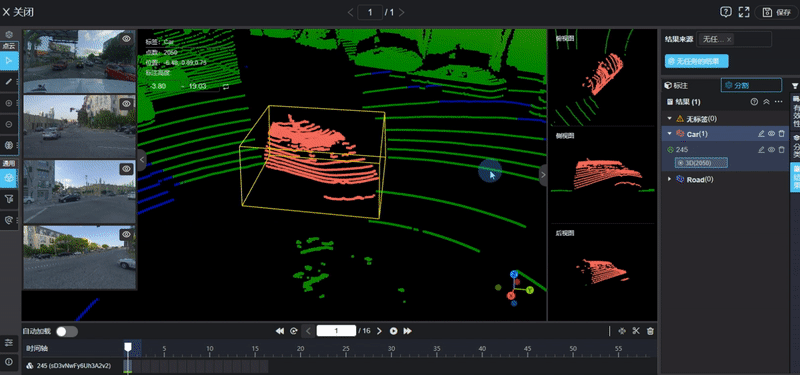
图片源自:网络
为了解决这个问题,行业内目前普遍转向了自动化标注流程。这需要利用昂贵的激光雷达数据作为真值,通过离线的点云处理算法来生成三维占据标签。然而,激光雷达和摄像头的视角并不完全重合,点云数据的稀疏性以及物体运动带来的重影问题,都会让生成的标签带有噪声。
如果训练数据本身的标签就是模糊甚至错误的,那么网络学习出来的结果自然也会打折扣。因此,如何构建一套精准、高效且能自我进化的自动化标注体系,成了各大车企暗自较量的软实力。

动态世界里的时间一致性如何维持?
占据感知网络在处理动态物体时也面临着严峻的挑战。现实世界的交通环境是随时间变化的,车辆、行人都在持续运动。如果OCC网络只是机械地一帧一帧去判断空间占据情况,那么感知的图像就会出现剧烈的闪烁或跳变。
比如一个行人走过,系统可能在前一毫秒感知到一个方块被占据,后一毫秒又觉得它是空的。这种感知上的不连贯性,会给后续的规划控制系统带来巨大的困扰,让车辆的行驶表现变得极其突兀和不稳。

图片源自:网络
为了解决这个问题,有技术方案中尝试引入时间序列的信息,也就是所谓的4D感知。通过融合前几帧的历史信息,让网络具备某种形式的“记忆”,从而平滑掉瞬时的噪声。
-- END --

随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 2027款兰博基尼SUV曝光,V12混动听着很猛但别急着上头
- 宝马X9看着很强,豪华SUV买家先算尺寸账
- 路虎卫士不适合“只想买一台豪华SUV”的人
- 旗舰SUV的价格买个”半成品”转向?魏牌V9X这道坎我必须说清楚
- 只有傻子才会买的5款SUV?老刘告诉你二手SUV买车避坑指南!
- L3/L4自动驾驶强制国标来了,自动驾驶行业彻底变天啦!
- 114码'自动驾驶'连睡6次!女乘客报警绝地求生:这哪是顺风车,这是'死神来了'体验卡!
- 为什么关于特斯拉自动驾驶的争论,一直没有结果?
- L3级自动驾驶落地在即!2027年7月:一场改变3万亿汽车产业的豪赌
- 捷达把中型SUV压到11万级,价格锚点正在松动
