25年12月来自UT Austin、Nvidia 和斯坦福大学的论文“Latent Chain-of-Thought World Modeling for End-to-End Autonomous Driving”。
近期用于自动驾驶的视觉-语言-动作(VLA)模型探索推理-时推理的方法,以提高在复杂场景下的驾驶性能和安全性。大多数现有工作使用自然语言来表达思维链(CoT)推理,然后再生成驾驶动作。然而,文本可能并非最有效的推理表示方式。本文提出 Latent-CoT-Drive (LCDrive) 模型:该模型使用一种潜语言来表达思维链,该语言能够捕捉所考虑的驾驶动作可能结果。该方法通过在动作对齐的潜空间中表示思维链推理和决策,从而统一两者。该模型不使用自然语言,而是通过交替使用以下两种tokens进行推理:(1)动作提议tokens,这些tokens使用与模型输出动作相同的词汇;(2)世界模型tokens,这些tokens基于学习的潜世界模型,并表达这些动作的未来结果。通过监督模型的动作提议和世界模型tokens,并基于场景的真实未来演变轨迹,对潜思维链进行冷启动训练。然后,用闭环强化学习进行后训练,以增强推理能力。在大型端到端驾驶基准测试中,与非推理和基于文本推理的基线模型相比,LCDrive 实现更快的推理速度、更好的轨迹质量,并且从交互式强化学习中获得更大的性能提升。
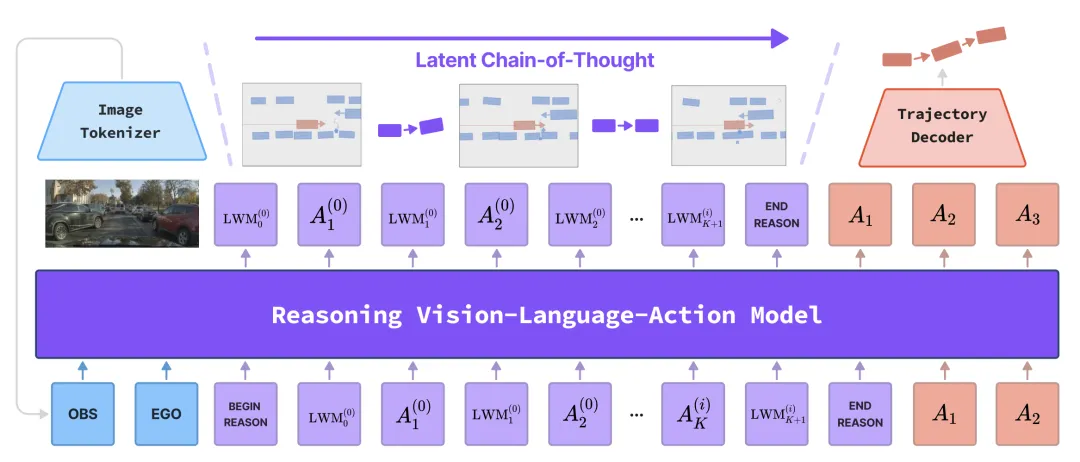
LCDrive 是一种用于驱动 VLA 模型的潜思维链框架。与依赖文本思维链不同,LCDrive 通过基于学习的潜世界模型 (LWM) 的向量空间监督思维链tokens进行推理,如图所示。潜推理过程在动作提议tokens和潜世界模型预测tokens之间交替进行,从而直接在潜空间中模拟反事实的未来,并利用这些未来信息来指导下一个动作的选择。这种交替的潜思维链形成一个结构化且紧凑的推理轨迹,该轨迹基于多智体交互过程,从而实现更高的动态精度和显著更高的推理效率。
前沿条件
端到端驾驶被建模为对token序列的自回归分布建模,该序列连接输入信息、(可选的)推理轨迹以及自车未来的轨迹 τ:[o_image, o_ego, REASON, τ],其中每个组件都以前面的所有组件为条件。模型的输入包括 o_image,即过去 L 步的 M 帧前视图(或多摄像头)图像;以及 o_ego,即自车运动历史。给定这些输入,模型会生成(可选的)REASON token,然后是自车未来的轨迹 τ。将 τ 参数化为以 10 Hz 采样率表示的完整 6.4 秒未来轨迹,从而得到包含 64 个未来路点的序列。
图像token化器:遵循标准的VLM(视觉-语言模型)实践,o_image中的每一帧都使用基于ViT的编码器(例如,[1, 28])独立进行token化,生成一系列视觉token o_img。来自不同相机视角和时间戳的视觉tokens 被连接起来,形成完整的视觉tokens 序列。
自运动token化器:自车历史运动学信息(速度、偏航率、过去k个控制动作)被嵌入到一组紧凑的token o_ego中,并使用学习的位置编码。
轨迹token化器:以10 Hz的频率表示未来6.4秒的轨迹,使用64个离散轨迹tokens τ = a_1:64,每个时间步一个标记。每个a_i索引对应于自车坐标系下的∆姿态(∆x,∆y,∆ψ)的运动基元。通过对训练数据中的∆姿态进行k-means聚类构建一个1024个码字的词汇表。通过将连续轨迹量化为索引a_1:64,并使用最近邻码字分配来编码连续轨迹。通过码本查找将离散索引解码回∆姿态,并随着时间积分以恢复连续轨迹τˆ。
潜世界模型(LWM):引入一个以自我为中心的潜世界模型状态LWM_t,它捕获来自在线感知的矢量化智体边框和姿态。每个LWM_t以10Hz的频率(10帧)总结一个固定的1.0秒窗口,作为一组固定大小的矢量化表示(自车+ K个最近的智体)。LWM_0编码直到当前时间的最新历史窗口,从而启动推理过程。它可以来自在线感知(检测、跟踪),也可以由VLA模型本身预测。LWM_1、LWM_2等表示在潜推理过程中生成的未来1.0秒窗口,以建议的动作作为条件。用一个轻量级的Transformer模块将每个LWM编码成一小组潜世界模型tokens LWM_0。
推理tokens:REASON 的存在是可选的,并且在不同的模型中用法也不同。对于非推理基线模型,将 REASON 设置为 ∅。为了进行公平比较,基线模型可以选择性地仅以 REASON = LWM_0 作为上下文。对于基于文本的 CoT 模型(例如 AR1 [24]),REASON 由一系列自然语言tokens组成,这些tokens以文字形式描述行动预测之前的中间推理过程。本文提出潜思维链(LCoT),其中 REASON 被实例化为由动作提议token和反事实潜世界模型 tokens组成的简短交错序列,并从潜状态 LWM_0 初始化。默认情况下,LWM_0 由 VLA 模型本身根据传感器输入作为上下文进行预测。
如图所示潜推理框架的概述:
潜思维链推理
目标是设计一种紧凑、与动作对齐的推理过程,该过程在潜世界模型状态下执行潜反事实推演,并将思维链(CoT)保持与最终轨迹输出相同的词汇表。
Token 方案。将每个推理分支表示为交错的动作和潜世界模型轨迹 R^(i)^。
动作提议。在步骤 t,VLA 根据传感器 token、当前世界状态和先前的推理 token 序列提出 A^(i)^_t。这些提议仅用作推理上下文,并不代表最终确定特定的规划。
LWM 预测。给定提议作为上下文,预测下一个潜世界状态。
多分支推理。为了让模型能够将更多推理 token 用于不同的策略和路径,启用固定数量分支 B 的自回归生成(默认 B = 2)。所有分支共享历史锚点 LWM_0 并按顺序生成:对于 i = 1...B,在以先前形成的轨迹 R^(<i)^ 为条件的情况下生成 R^(i)^。这使得模型在提出下一个分支时可以参考先前的潜推理,从而在有限的 token 预算下促进多样性,并产生更合理、互补的反事实未来。
动作预测。完整的推理上下文为REASON = [LWM_0, R^(1)^, ..., R^(B)^]。以传感器输入和公式中的 REASON 为条件,模型预测 64 个分步轨迹 token a_1:64 并解码最终轨迹 τˆ。最终动作会关注所有提议及其相关的潜世界模型推演,形成丰富的反事实上下文,这会产生更高保真度、更安全、更稳定的轨迹。
训练策略
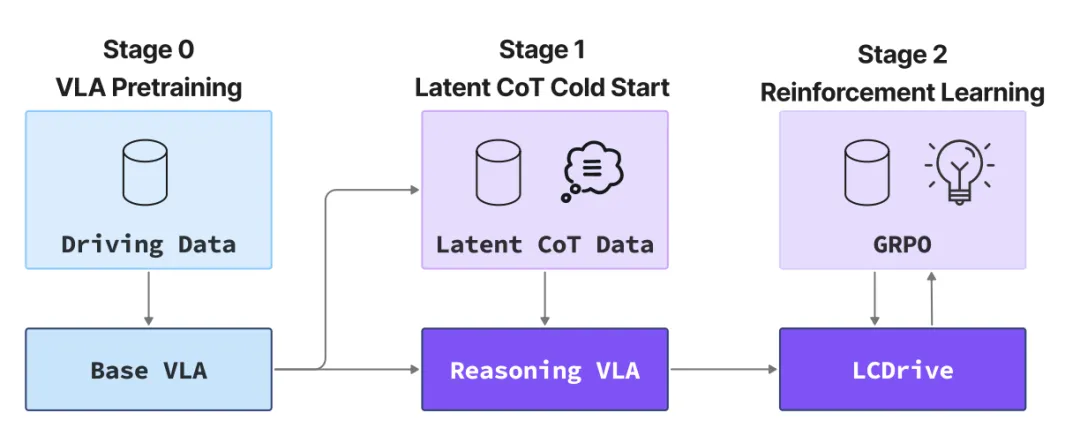
本文通过三阶段流程(如图所示)训练 LCDrive。首先,从预训练的非推理 VLA 模型开始,通过教师强制学习的方式,使用真实世界模型状态和模型自身提出的推理动作来对模型进行冷启动,从而初始化潜思维链。在此过程中,同时训练一个小型 LWM 预测头,用于在推理过程中根据提出的动作预测 LWM 嵌入。接下来,应用强化学习 (RL) [16] 来改进这种初始的潜推理框架,并使用轨迹级奖励来提高最终动作预测的性能。