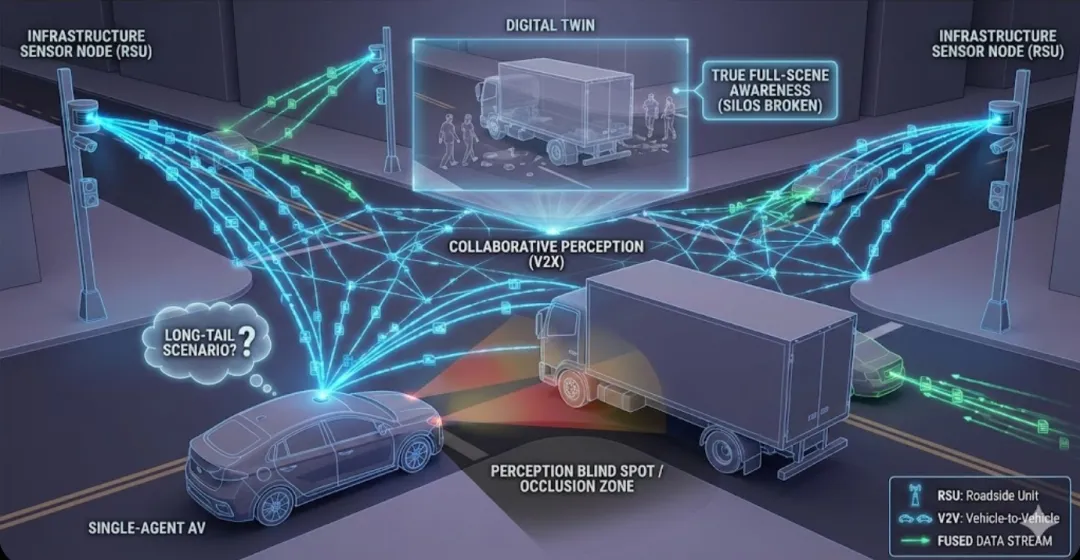
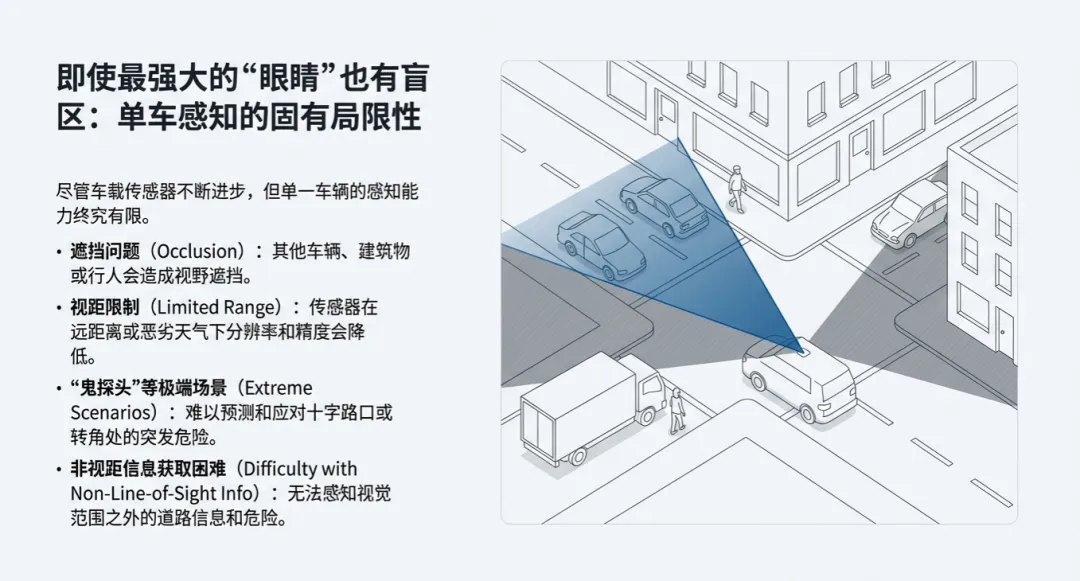
在自动驾驶的讨论圈子里,大家往往习惯性地盯着特斯拉的视觉方案或者国内各家车企的多传感器融合。但坦白说,如果只靠车子本身的那几个传感器,自动驾驶可能永远无法走出“长尾场景”的泥潭。单一车辆的感知局限性极其明显:由于物理遮挡、远距离目标分辨率低,以及转角处的盲区等硬伤,单纯靠“加码”车载硬件,安全性和可靠性的提升正面临严重的物理天花板。
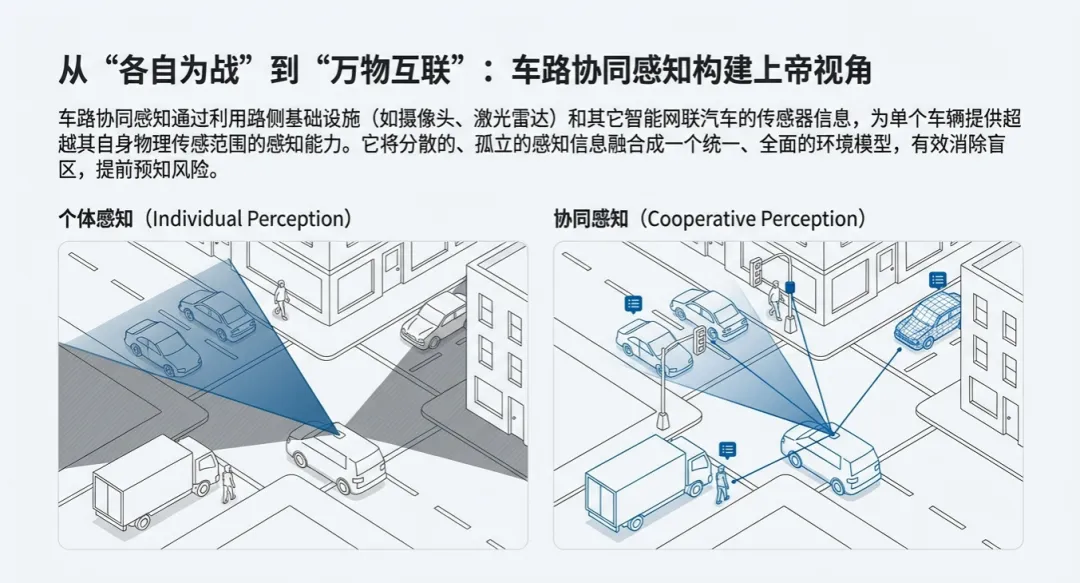
在我看来,车路协同感知(Collaborative Perception)不是一个“备选项”,而是通往高级别自动驾驶的“必经之路”。 这种技术通过打破单车的感知孤岛,利用多个智能体(包括其他车辆、路侧基础设施等)进行信息互补,从而实现真正的全景视野。
一、 协同策略背后的“权衡博弈”:为什么中间路线最受宠?
很多技术解读在谈到协同策略时,只是简单列举。但从工程落地的角度看,这实际上是一个在通信带宽、计算延迟与感知精度之间的残酷博弈。
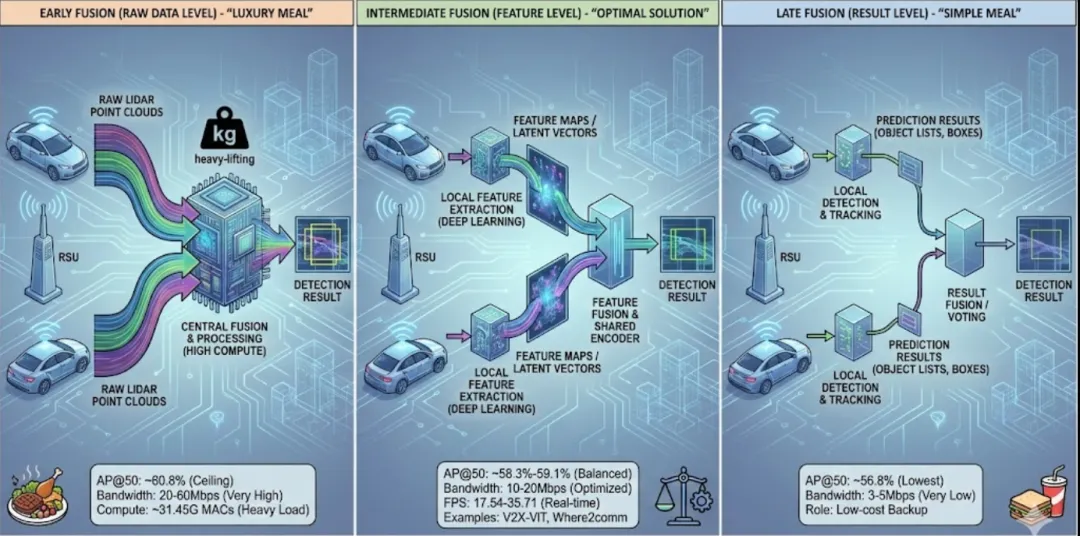
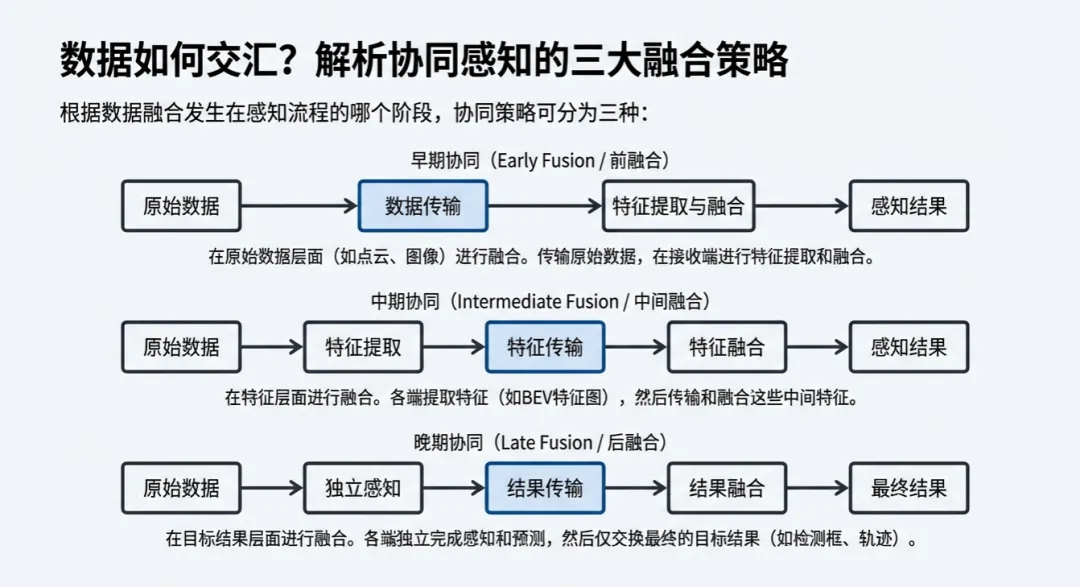
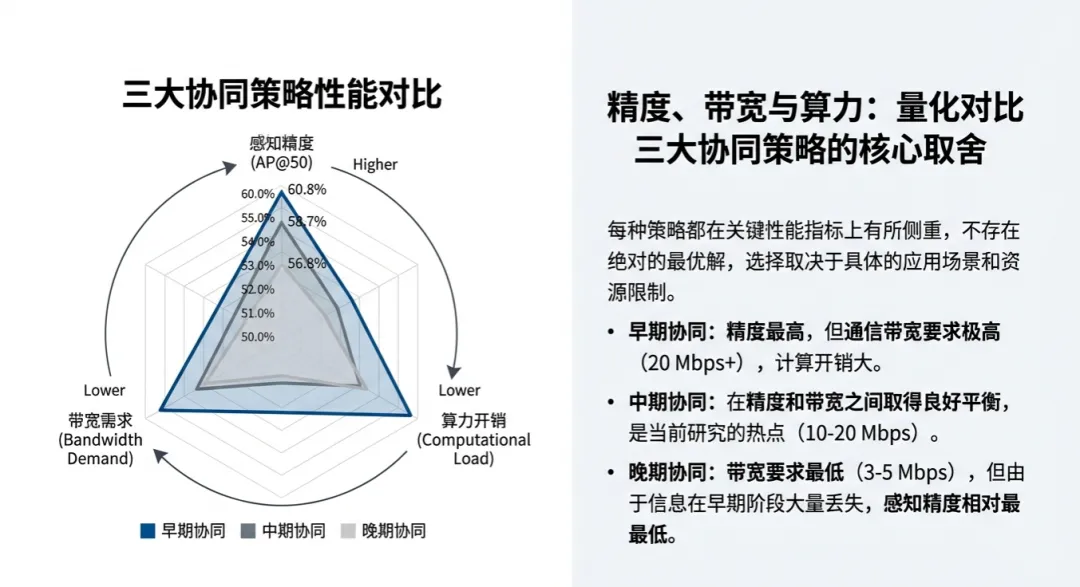
早期协同(原始数据级):感知的“豪华餐”早期协同要求智能体之间直接传输原始的点云或图像。在DAIR-V2X等数据集的评估中,它的目标检测平均精度(AP@50)能达到惊人的60.8%,是目前的精度“天花板”。但它的代价非常昂贵:对通信带宽的要求高达20Mbps至60Mbps,且在当前车辆端进行融合时的计算量高达31.45G MACs,这在目前的大规模商用中几乎是不可能承受的重担。
中期协同(特征级):工程派的“最优解”这是目前行业研究最密集的领域,也是V2VNet、V2X-ViT、Where2comm等主流模型的选择。它不传原始数据,而是先通过深度学习网络提取高维特征,再进行传输。这种做法巧妙地将带宽需求压低到了10Mbps-20Mbps,同时还能保持接近60%的检测精度(58.3%~59.1%)。更重要的是,它的推理速度极快,在特定配置下每秒帧数(FPS)可达17.54甚至35.71,真正满足了实时安全驾驶的需求。
后期协同(结果级):经济型的“简餐”这种策略仅传输感知后的预测结果(如目标的位置和类别),带宽占用极低,仅需3Mbps-5Mbps,。虽然它比单体感知要强,但由于丢失了大量底层关联信息,其56.8%的精度表现是三种方案中最低的,通常被视为一种低成本的兜底方案。
二、 核心感知的技术跃迁:从“平面成像”到“上帝视角”
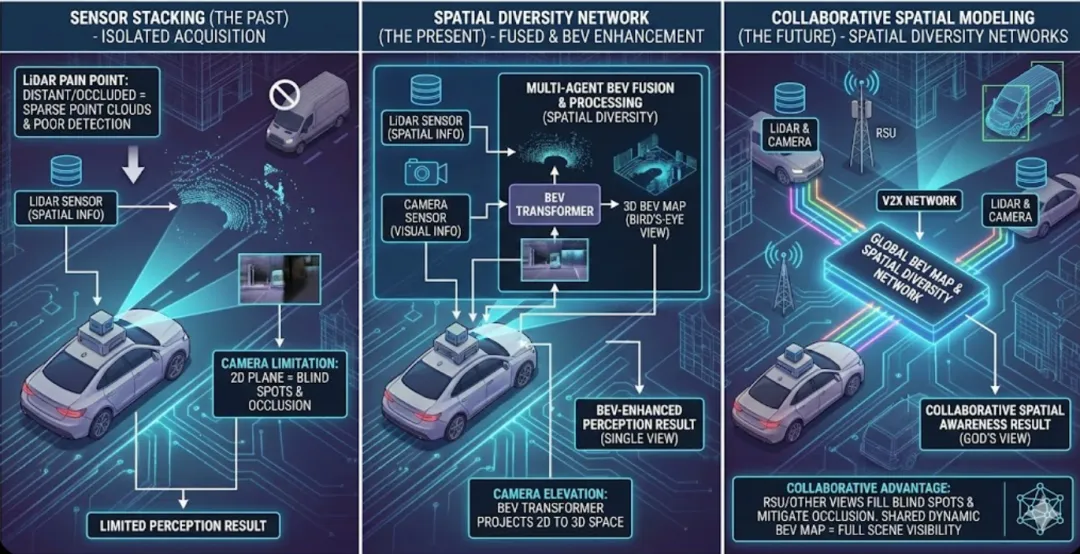
目前的感知技术正在经历一场从传感器堆叠到空间建模的革命。我们不能再把LiDAR和相机看作独立的采集工具,而要看作空间多样性(Spatial Diversity)的传感器网络。
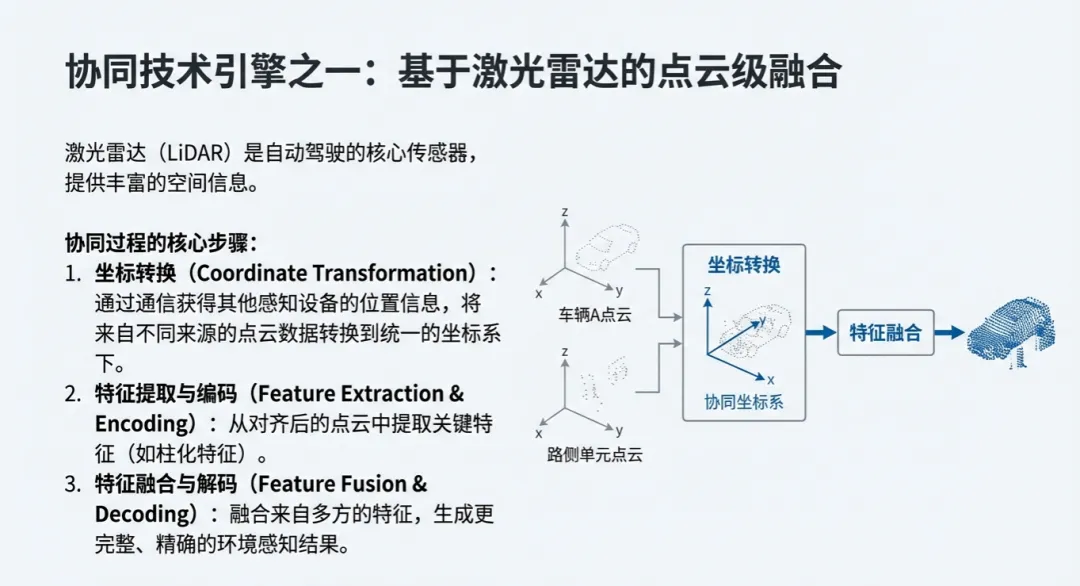
- LiDAR感知的深层痛点: 激光雷达虽然能提供精准的空间信息(位置、大小、方向),且受光照影响小,但它有一个致命弱点——远距离物体的点云极其稀疏。当物体被遮挡时,返回的点云数量极少,导致检测性能大幅下降。通过协同,路侧或其他车辆的视角可以弥补这种稀疏性。
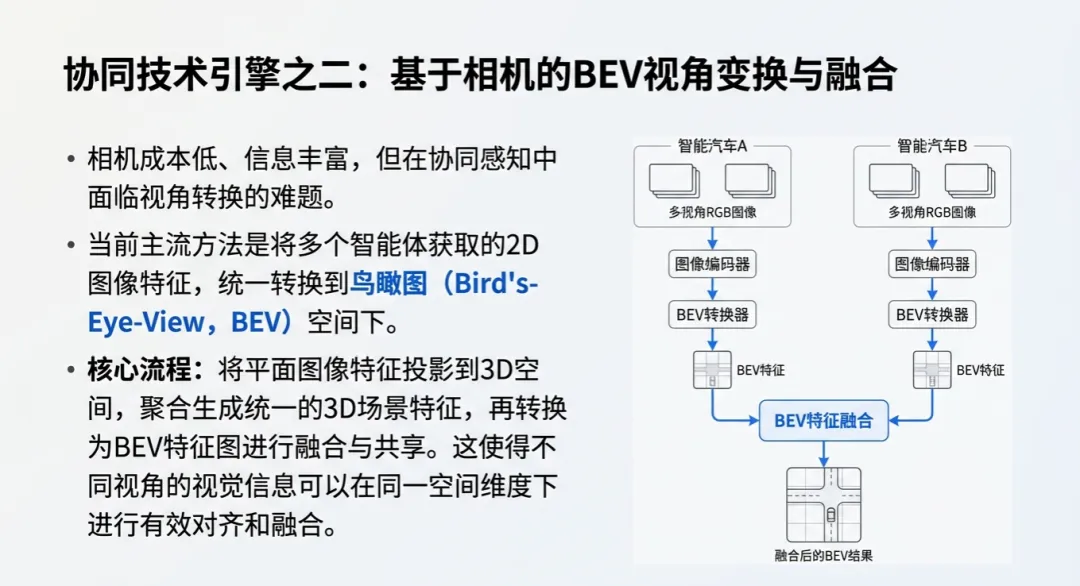
- 相机感知的“升维”: 现在的尖端方法不再满足于2D图像处理,而是将多个智能体获取的图像特征直接转换并聚合到鸟瞰图(BEV)视角中。通过BEV Transformer等技术,平面图像特征被投影到3D空间,形成一份“上帝视角”的动态地图。这种方式的妙处在于,路口的摄像头或LiDAR可以提供高位视角,完美补全车辆在转弯、并线时的视觉盲区。
三、 通信与信息“减肥”:如何给数据流瘦身?
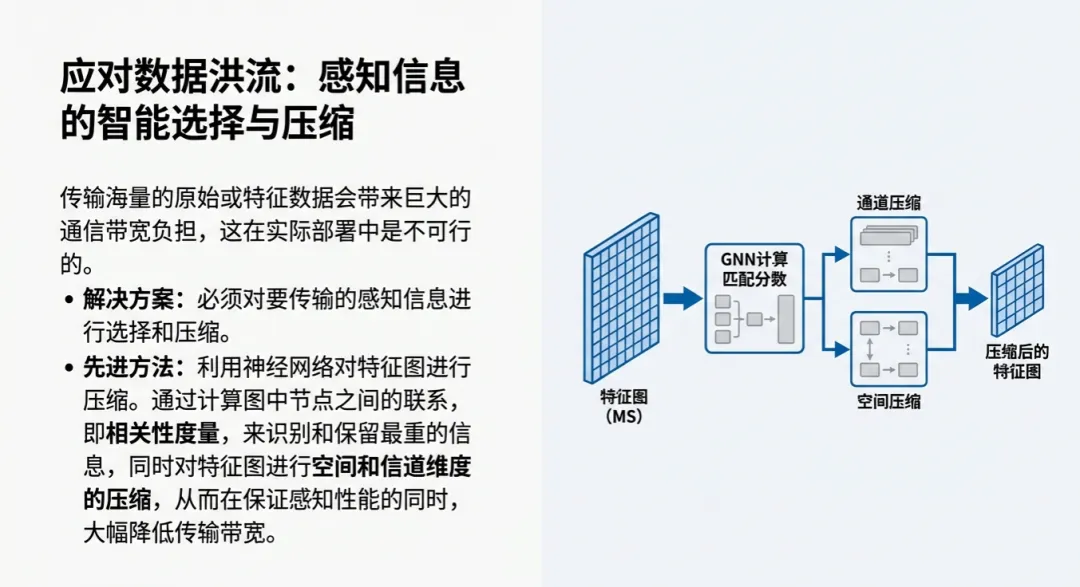
车路协同面临的一个巨大难题是:我们不可能把路口所有摄像头的数据都塞给车辆。这要求系统必须具备感知信息选择与压缩的能力。
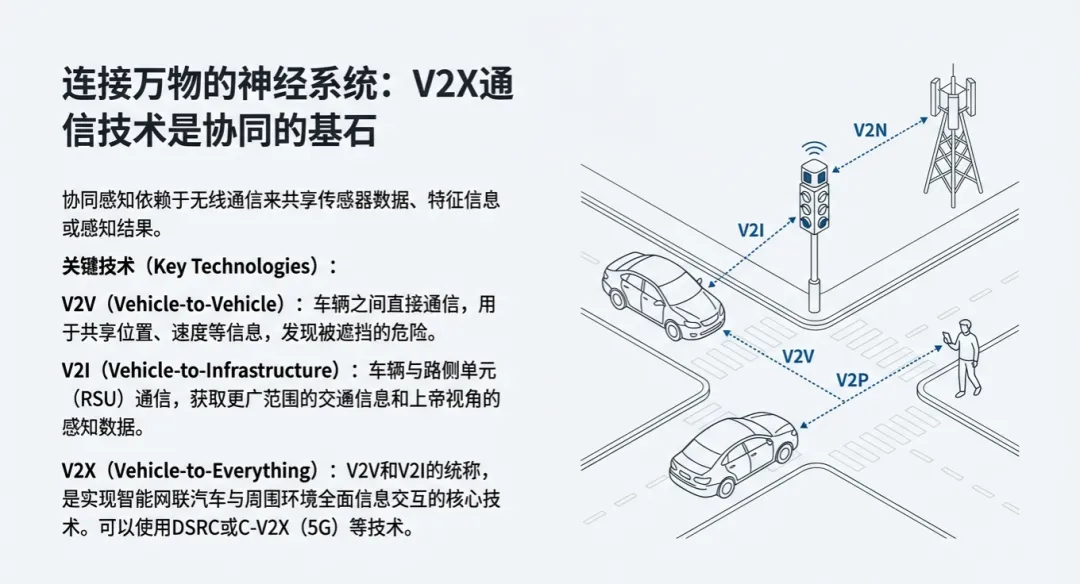
目前的前沿研究利用图神经网络(GNN)来对感知信息进行智能筛选。系统会根据图中节点(感知特征)之间的联系权重,利用通道压缩和空间压缩技术,只传输那些对当前决策“最有价值”的特征。这种在传输前进行的“瘦身”操作,极大地缓解了V2X通信(尤其是C-V2X或5G)的带宽负载压力,。此外,V2I技术通过路侧传感器提供的高视角信息,为系统构建了一个完整、多层次的路况视图,这比单纯依靠V2V(车间通讯)要稳健得多。
四、 隐形的防线:安全防御与数据隐私
车路协同虽然强大,但也更复杂、更脆弱。作为深度解读,我们必须正视其背后的三个“硬骨头”:
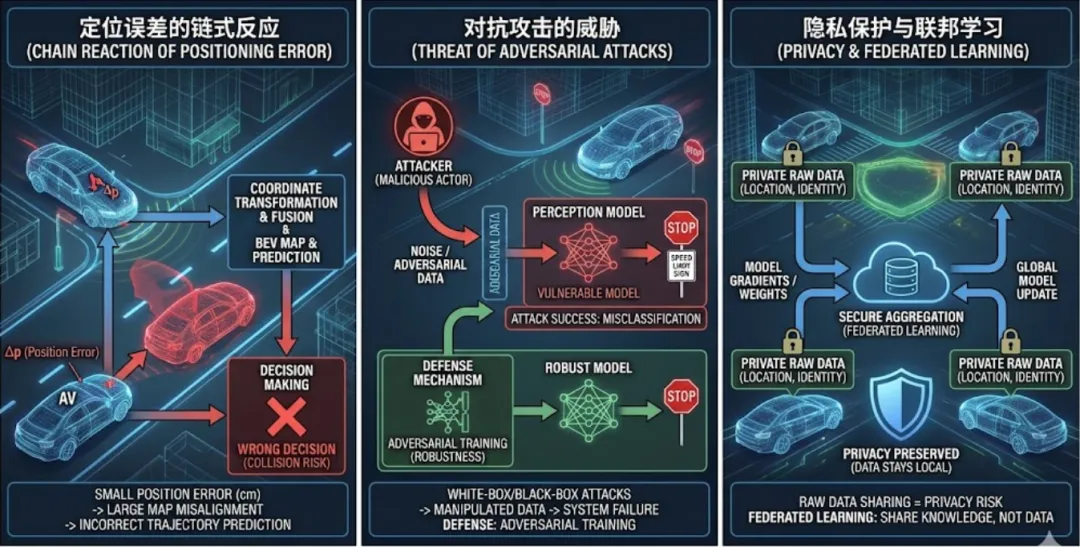
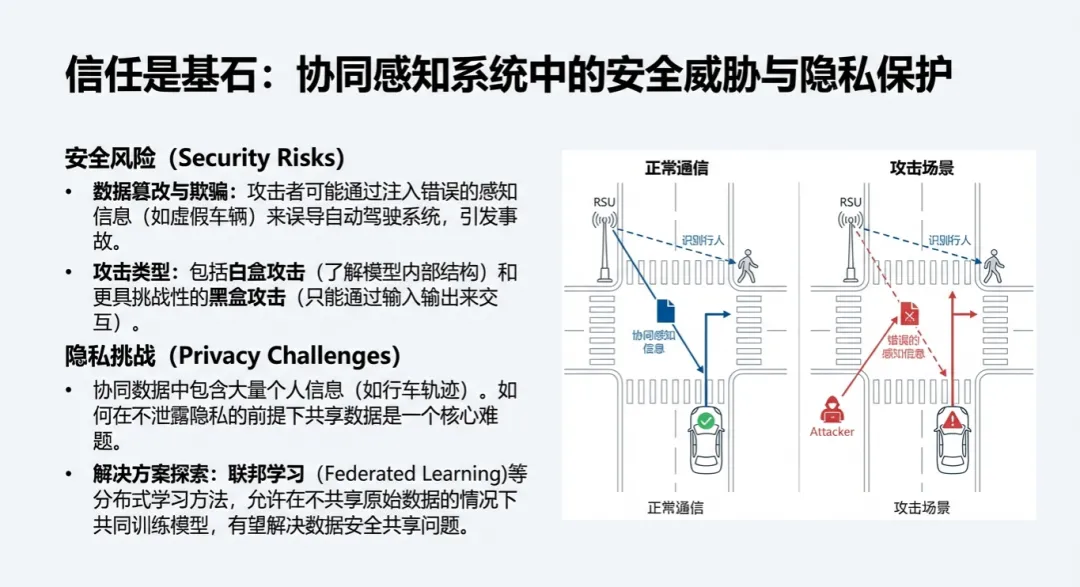
- 定位误差的链式反应: 协同感知高度依赖精准的位姿信息。一旦传感器受环境干扰产生定位偏差(比如几厘米的误差),在进行坐标转换和特征融合时,就可能导致周围车辆位置的预测出现巨大偏移,从而引发错误的驾驶决策,。
- 对抗攻击的威胁: 恶意攻击者可能通过操纵数据或引入噪声,实施白盒攻击或黑盒攻击。白盒攻击者拥有感知模型的完整信息,而黑盒攻击则通过输入输出进行交互攻击。目前的防御策略主要是将对抗样本纳入训练阶段,即所谓的“对抗训练”,以提高系统的鲁棒性。
- 隐私保护与联邦学习: 车辆捕获的数据包含大量位置和身份隐私,直接共享原始数据存在巨大的安全隐患和商业秘密泄露风险。联邦学习(Federated Learning)作为一种分布式学习方案,被视为解决这一难题的关键。它允许各方在不交换原始数据的前提下共享知识,有望实现不同车辆、不同组织之间资源的安全互补。
五、 行业“燃料”:主流车路协同数据集横评
技术的成熟度最终要靠数据说话。目前行业内已经形成了从仿真到实景的完整数据集矩阵:
- DAIR-V2X(实战标杆): 这是首个大规模、多模态的真实场景数据集,涵盖了城市道路、高速公路及28个十字路口,拥有超过7万帧同步的点云和图像数据,。
- DOLPHINS(极限挑战): 如果你想测试系统在隧道、坡道、互通立交等复杂地形下的表现,这个数据集是首选。它将目标检测难度分级,专门考验算法在动态天气和复杂光照下的鲁棒性。
- V2X-Sim 与 OPV2V(仿真先锋): 它们利用CARLA等模拟器生成了数万帧高质量数据,支持从3D目标检测到语义分割等全方位的算法验证,极大降低了开发初期的试错成本,。
六、 商业价值与推广前景:单车智能的“经济化救赎”
谈到车路协同的推广,很多人觉得成本太高。但我们得换个思路看:
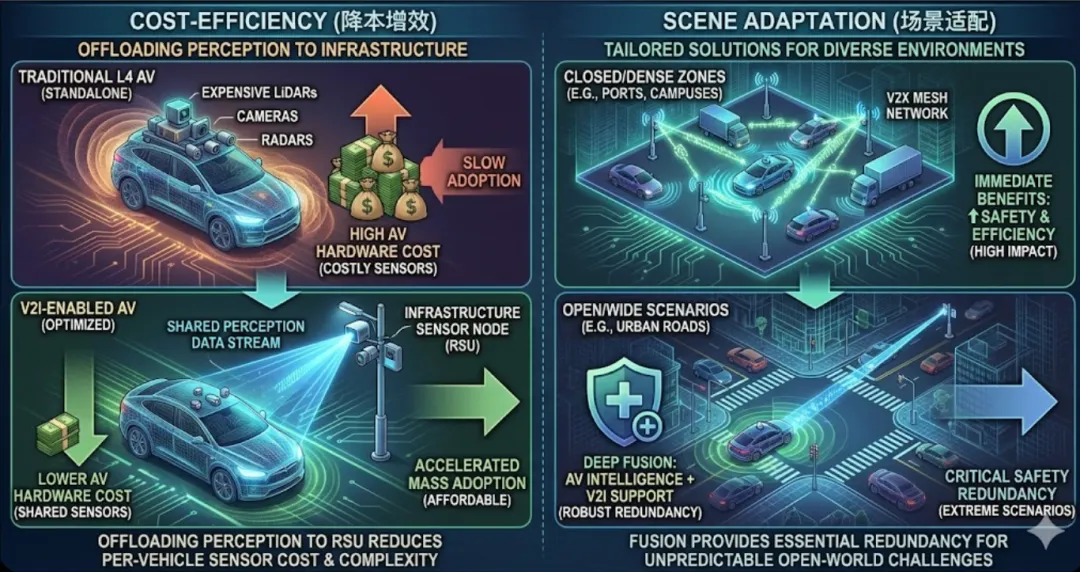
首先是降本增效。 目前L4级的单车硬件成本极高,普及难度大。通过V2I(车路协同),我们可以把部分昂贵的感知能力“外挂”在路端基础设施上。这样一来,单车就不再需要堆叠最顶级的传感器,整体制造成本反而可能下降,从而加速自动驾驶的平民化,。
其次是场景适配。 在封闭园区或车辆密集的特定区域,车路协同感知的优势立竿见影,能显著提升安全性与运行效率。而在开放的大范围场景中,未来更可能的路径是单车智能与车路协同的深度融合,确保在各种极端场景下都有充足的安全冗余。
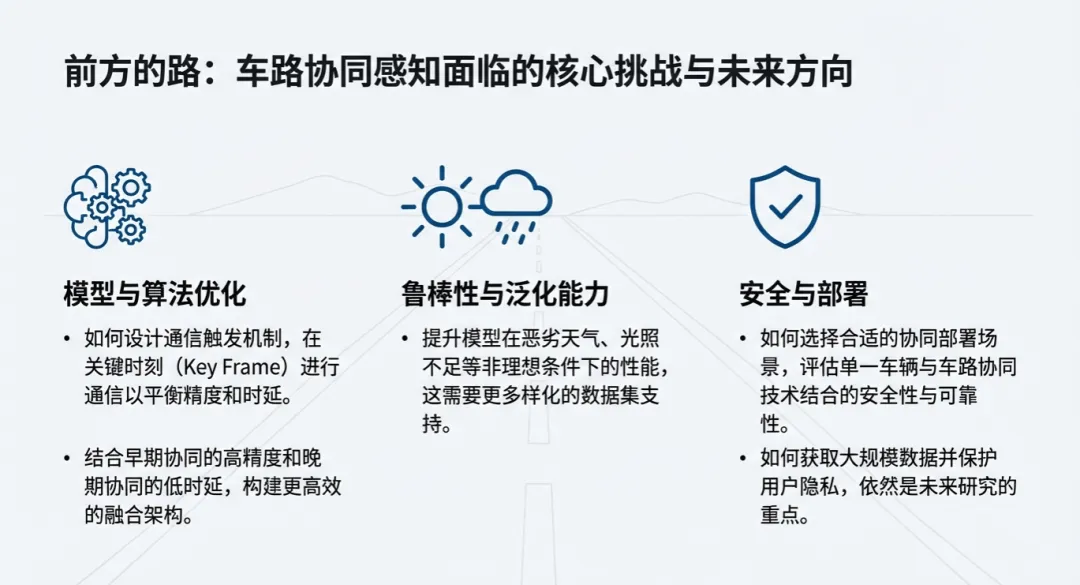
展望未来:车路协同感知的研究重点正在发生转移。后续我们将看到更多关于空间-时间维度深度耦合的研究,以及如何优化协同的时机以降低系统成本。车路协同感知不再仅仅是单车智能的“辅助工具”,它是构建未来智慧交通系统的核心神经元,也是自动驾驶真正从实验室走向千家万户的最后一块拼图。