⚡ 自动驾驶高效视觉问答管道SRC-Pipeline:66%算力削减+性能相当,适配实时安全需求
📖 导读
针对自动驾驶视觉问答(VideoQA)的时序特性(后期帧更关键),提出SRC-Pipeline高效框架,通过“早期帧场景-区域压缩+后期帧密集补丁保留”策略,在LingoQA数据集上实现66%浮点运算(FLOPs)削减,同时保持与基线模型相当的性能。其核心创新是场景区域压缩视觉Transformer(SRC-ViT),将早期帧转化为1个场景令牌+4个区域令牌,既保留全局上下文,又大幅降低计算负担,完美契合AI与传感融合的“协同设计”趋势(传感器数据与AI算法联合优化),解决了大型视觉语言模型(VLMs)在自动驾驶中延迟过高、难以实时部署的核心痛点。
该研究的关键价值在于:首次针对性利用自动驾驶VideoQA的“时序优先级”特性,避免传统令牌剪枝引入的额外计算开销,实现“无冗余降算力”,为安全临界的自动驾驶场景提供了兼具效率与精度的多模态理解方案。
📷图1. 通用视频问答与自动驾驶视频问答的区别。通用视频问答的问题涵盖所有帧的信息,而由于自动驾驶视频的时效性,自动驾驶视频问答的问题大多聚焦于后面的帧。左:SRC-Pipeline整体架构(SRC-ViT+VLM解码器);中:自动驾驶VideoQA时序特性(后期帧更关键);右:SRC-ViT注意力掩码设计(区域令牌仅关注对应象限补丁)
原论文信息
- 论文题目:Efficient Visual Question Answering Pipeline for Autonomous Driving via Scene Region Compression
- 核心发现:FLOPs削减66%(仅保留33.3%算力消耗);LingoQA数据集上,5帧场景下Ling-Judge得分59.10(基线QWen2VL为58.20),1帧场景下得分57.28(优于LingoQA的57.00);SRC-ViT在图像-文本检索任务上超越CLIP ViT(ItoT 86.5 vs 84.3);
- 关键创新:SRC-ViT(场景+4区域令牌压缩)、时序令牌选择策略(早期压缩+后期密集)、两阶段训练(视觉编码器预训练+VLM管道微调);
- 数据覆盖:LingoQA数据集(41.99万自动驾驶QA对)、CC3M子集(图像检索验证);
- 实验基准:Ling-Judge(语义相似度)、BLEU(文本匹配)、FLOPs(算力)、图像-文本检索准确率;
- 核心团队:Yuliang Cai(南加州大学)、Dongqiangzi Ye(小鹏汽车)等;
- 发表状态:2026年arXiv预印本(arXiv:2601.07092v1 [cs.CV]);
- 核心应用:自动驾驶感知系统、实时场景理解、多模态决策辅助;
- 关键方法:SRC-ViT设计、对比学习预训练、时序令牌压缩、VLM管道微调。
❓ 自动驾驶视觉问答的三大“核心痛点”
- 算力与延迟矛盾:传统VLMs处理每帧数百个密集补丁令牌,FLOPs过高,无法满足自动驾驶“数百毫秒”的实时响应要求;
- 令牌剪枝冗余:现有令牌剪枝方法需额外计算识别冗余令牌,反而降低整体效率;
- 时序特性未利用:自动驾驶问答聚焦实时感知与决策,依赖后期帧细节,早期帧仅需提供全局上下文(如天气、路况),传统模型同等处理所有帧导致算力浪费。
🔧 核心突破:SRC-Pipeline的“三维高效创新”方案
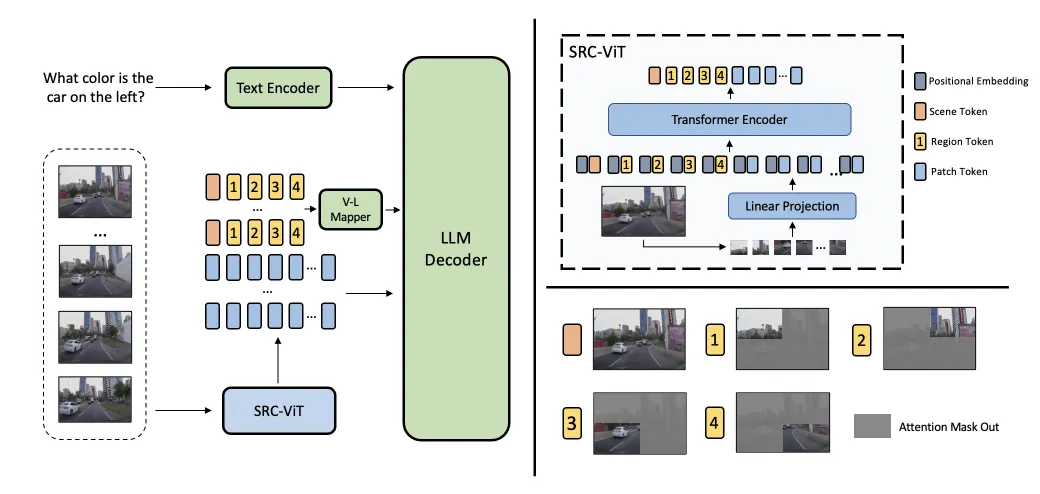
1. SRC-ViT视觉编码器(创新点1):场景-区域多尺度压缩
- 结构设计:在传统ViT基础上,新增1个可学习场景令牌(全局语义)和4个区域令牌(左上/右上/左下/右下象限),结合注意力掩码约束(区域令牌仅关注对应象限补丁);
- 核心优势:无需密集补丁即可保留关键信息,1个场景+4个区域令牌替代数百个补丁令牌,压缩比显著;
- 预训练优化:通过对比学习将场景/区域令牌与CLIP文本编码器输出对齐,提升语义表达能力,图像-文本检索准确率超越原生CLIP ViT。
2. 时序令牌选择策略(创新点2):适配自动驾驶特性
- 核心逻辑:自动驾驶VideoQA中,后期帧包含实时决策关键信息(如交通灯颜色、行人位置),早期帧仅提供上下文;
- 实现方式:前M帧用SRC-ViT生成的压缩令牌(场景+区域),后N-M帧保留完整密集补丁令牌;
- 关键效果:在5帧视频中,前4帧压缩、最后1帧密集,仅消耗33.3% FLOPs,性能无显著下降。
3. 两阶段训练流程(创新点3):兼顾压缩质量与问答性能
- 第一阶段:SRC-ViT预训练,通过场景/区域文本描述与令牌的对比损失,让压缩令牌具备语义表达能力;
- 第二阶段:VLM管道微调,冻结SRC-ViT参数,训练视觉-语言映射器与LLM解码器,适配压缩令牌与密集令牌的混合输入;
- 核心优势:避免从头训练VLMs,仅微调关键模块,降低训练成本,同时保证多模态融合质量。
关键内容
1. 核心性能对比(LingoQA数据集)
2. SRC-Pipeline架构细节
- 视觉编码:SRC-ViT接收视频帧,输出压缩令牌(场景+4区域)和密集补丁令牌;
- 令牌选择:根据帧时序位置,早期帧输出压缩令牌,后期帧输出密集令牌;
- 模态融合:视觉-语言映射器将压缩令牌投影至VLM共享嵌入空间,与文本查询编码融合;
- 解码生成:LLM解码器处理混合视觉令牌与文本编码,生成问答结果。
3. 消融实验关键结论
- 场景+区域令牌缺一不可:仅用场景令牌(无区域)时,Ling-Judge降至56.42;移除场景-区域压缩(仅平均池化),得分进一步降至56.20;
- 时序策略验证:反向策略(早期密集+后期压缩)导致Ling-Judge骤降至41.02,证明后期帧密集令牌的必要性;
- 预训练有效性:SRC-ViT预训练后,零样本Ling-Judge从51.15提升至52.40,验证压缩令牌的语义质量。
💬 Q&A
Q1:SRC-Pipeline为什么聚焦自动驾驶VideoQA的时序特性?A:自动驾驶问答多是实时感知(如“当前交通灯颜色”)或决策类问题,后期帧包含最关键的动态信息(行人、车辆、信号灯状态),早期帧仅需提供全局上下文(如道路类型、天气),无需密集细节,这种特性是其他通用VideoQA不具备的,针对性压缩早期帧可最大化降算力。
Q2:SRC-ViT相比传统ViT的优势是什么?A:传统ViT输出数百个补丁令牌,计算量大;SRC-ViT新增场景-区域令牌,通过注意力掩码约束实现空间定位,压缩后仅5个令牌即可保留核心信息,且预训练后语义表达能力超越原生CLIP ViT,同时无需额外冗余计算。
Q3:如何契合AI与传感融合的“协同设计”趋势?A:SRC-Pipeline并非独立优化模型或数据,而是让视觉编码器(传感器端)生成适配VLM(算法端)的压缩令牌,传感器输出与算法需求协同优化,既减少数据传输量(降低延迟),又降低算法计算量,完美契合综述提出的“传感器与AI协同设计”方向。
Q4:两阶段训练的作用是什么?A:第一阶段预训练SRC-ViT,确保压缩令牌具备足够的语义表达能力,避免因压缩导致信息丢失;第二阶段微调映射器与解码器,让VLM适配“压缩令牌+密集令牌”的混合输入,兼顾效率与问答性能,无需从头训练庞大的VLMs。
🎯 点评
- 核心贡献:首次针对性利用自动驾驶VideoQA的时序特性,提出无冗余的令牌压缩策略,解决VLMs实时部署难题;SRC-ViT通过场景-区域多尺度设计,平衡压缩比与语义质量;两阶段训练流程降低落地成本,性能与算力达到最优平衡;
- 创新点:时序感知的令牌选择策略、带注意力约束的多尺度压缩ViT、轻量化VLM适配方案,三大创新直击自动驾驶多模态理解的核心痛点;
- 不足:仅在LingoQA数据集验证,未测试更长视频序列(如30帧以上);未探索不同自动驾驶场景(如高速、雨夜)的适配性;未对比TinyML等边缘计算方案的效率差异。
🌟 总结金句
自动驾驶视觉问答的高效化,关键在于“算力用在刀刃上”——SRC-Pipeline的突破不仅是技术上的令牌压缩,更在于精准捕捉场景特性,让早期帧“瘦身”保上下文,后期帧“全力”保细节,在AI与传感的协同设计中,实现了“降算力不降性能”的核心目标,为实时安全的自动驾驶感知提供了新范式。
📌 互动引导
你认为SRC-Pipeline下一步最该扩展的场景是什么?● ✅ 长时序视频(30帧以上)适配;● ✅ 恶劣天气(雨/雾)与复杂路况(施工/拥堵)验证;● ✅ 边缘计算硬件(如车载芯片)部署测试;欢迎在评论区分享观点,一起探讨高效视觉问答的落地路径 👇
🧩 科研 Idea 彩蛋
- 长时序适配优化:设计动态压缩阈值(根据场景复杂度调整早期帧数量),适配30帧以上长视频,适合投稿《IEEE Transactions on Intelligent Transportation Systems》;
- 多模态融合扩展:集成雷达/激光雷达数据,将SRC策略扩展至多传感器令牌压缩,适合投稿《Sensors》;
- 边缘硬件部署:结合TinyML优化SRC-ViT,适配车载低功耗芯片,测试延迟与能耗,适合投稿《IEEE Embedded Systems Letters》;
- 场景自适应压缩:通过AI判断场景复杂度(如拥堵/空旷),动态调整区域令牌数量(2/4/6个),提升极端场景性能,适合投稿《Neural Computing and Applications》;
- 跨数据集泛化验证:在DriveLM、Drama等自动驾驶QA数据集测试,验证模型通用性,适合投稿《Computer Vision and Image Understanding》。



