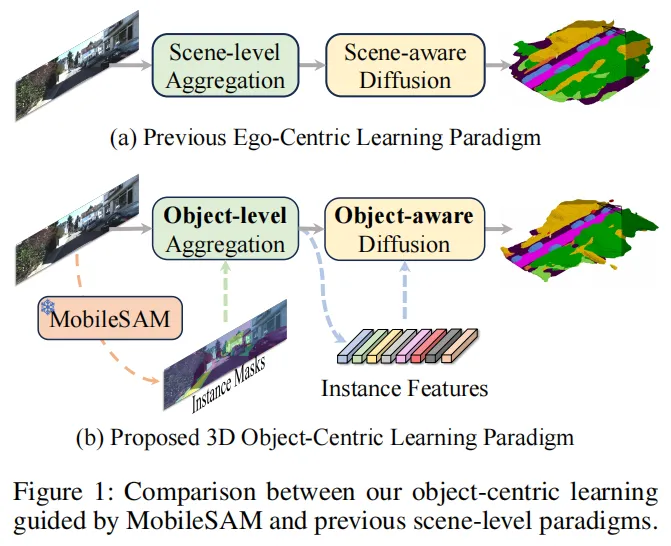
在自动驾驶的感知环节中,3D语义场景补全(SSC)是核心任务之一——它能将3D空间划分为体素并预测每个体素的语义标签,生成密集的3D环境结构化表示,为下游的路径规划提供关键支撑。但传统以自我为中心的学习范式,始终难以解决复杂场景下的语义和几何模糊问题。
近日,一篇发表于AAAI 2026的研究论文《Towards 3D Object-Centric Feature Learning for Semantic Scene Completion》给出了全新解法:提出以物体为中心的Ocean框架,通过三大核心创新模块,在SemanticKITTI和SSCBench-KITTI360两大权威基准上刷新SOTA,mIoU分别达到17.40和20.28!今天我们就深度拆解这一突破性工作。
论文信息
题目:Towards 3D Object-Centric Feature Learning for Semantic Scene Completion
面向语义场景补全的三维以物体为中心的特征学习
作者:Weihua Wang, Yubo Cui, Xiangru Lin, Zhiheng Li, Zheng Fang
一、传统范式的痛点:语义与几何的双重模糊
基于视觉的3D语义场景补全因低成本、易部署的优势成为研究热点,但主流的以自我为中心范式存在致命缺陷:
这类方法通过相机-自我关系将2D视觉特征转换为3D特征后全局扩散,却无法有效区分不同体素的特征归属。比如路边多辆相邻汽车的场景中,全局融合会让汽车间的空区域被错误赋予汽车特征,既造成语义混淆(不同物体特征融合),又引发几何混淆(空区域与占据区域特征融合),最终导致细粒度场景理解失效。
 ▲ 以自我为中心范式的缺陷:相邻汽车间的空区域被错误分配汽车特征
▲ 以自我为中心范式的缺陷:相邻汽车间的空区域被错误分配汽车特征
虽然以物体为中心的学习范式已被初步探索,但缺乏明确的物体级对应关系,性能提升有限。而MobileSAM等视觉基础模型虽能提取细粒度实例掩码,却受限于2D平面,且掩码错误/遗漏会直接导致性能下降——这成为了Ocean框架需要攻克的核心挑战。
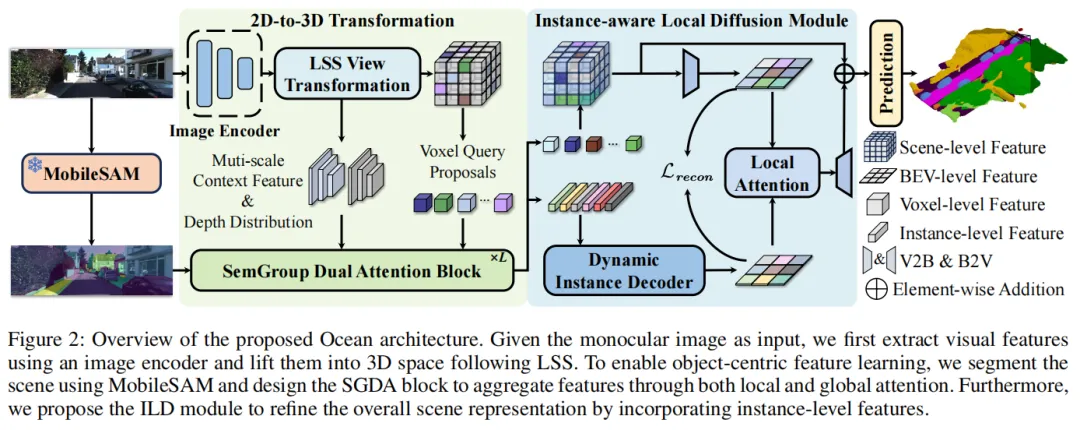
二、Ocean框架:以物体为中心的3D特征学习核心设计
Ocean框架的核心思路是:将场景分解为独立物体实例,以MobileSAM的实例掩码为先验,通过特征聚合与扩散,实现更精准的语义体素预测。其整体架构如下图所示,涵盖图像特征提取、3D体素提升、语义分组双重注意力(SGDA)、实例感知局部扩散(ILD)四大核心环节。
 ▲ Ocean框架整体结构图(方法总览)
▲ Ocean框架整体结构图(方法总览)
创新点1:语义分组双重注意力模块(SGDA)—— 精准聚合3D物体特征
SGDA是Ocean的核心模块,由3D语义分组注意力(SGA3D)和全局相似性引导注意力(GSGA)组成,既解决2D先验的3D扩展问题,又弥补掩码缺陷。
1.1 3D语义分组注意力(SGA3D):从2D实例到3D特征聚合
首先,MobileSAM从输入图像中提取每像素实例掩码(背景标记为0,不同物体对应不同实例ID):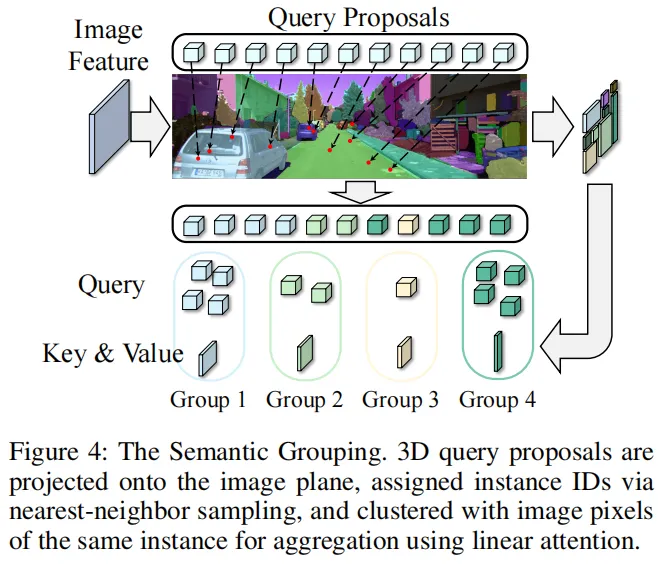 ▲ MobileSAM提取的实例掩码:每个像素被赋予唯一实例ID
▲ MobileSAM提取的实例掩码:每个像素被赋予唯一实例ID
随后将3D查询提议投影到图像平面,按最近邻规则为投影点分配实例ID,将同一实例的像素和投影点归为一簇。为了聚合多尺度图像特征,SGA3D对不同尺度的特征按掩码分组,在簇内采用分散线性注意力完成特征聚合;同时整合深度信息,将2D实例先验扩展到3D空间,弥补几何感知的不足——这让模型既能捕获语义细节,又能理解3D几何结构。
1.2 全局相似性引导注意力(GSGA):修正掩码错误,补充缺失实例
SGA3D专注于单实例内的局部交互,但MobileSAM的掩码难免存在错误/遗漏。GSGA通过可变形注意力机制,以MobileSAM全局特征为引导,动态聚合全局图像特征到查询提议: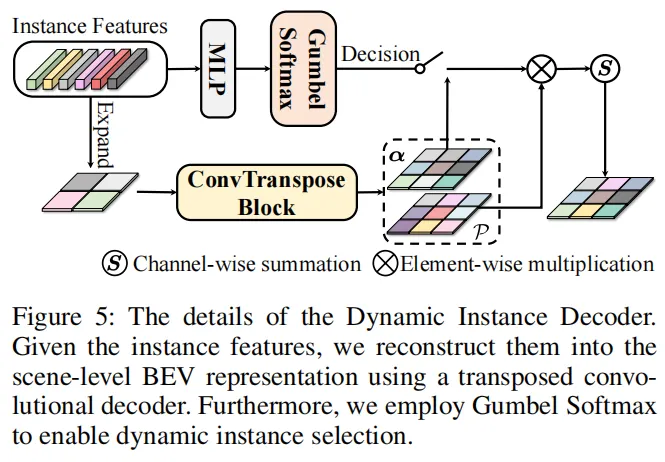 ▲ GSGA模块:通过相似性引导和可变形注意力校正掩码错误
▲ GSGA模块:通过相似性引导和可变形注意力校正掩码错误
它计算查询提议与MobileSAM中间特征的相似性,过滤并强调同一物体实例的特征,既保留以物体为中心的范式,又缓解了掩码不准确带来的性能损失。
创新点2:实例感知局部扩散模块(ILD)—— 细化场景语义表示
即便SGDA能聚合丰富特征,仍有大量体素因投影限制缺乏语义信息。ILD模块通过“动态实例解码器+局部注意力细化”,将实例特征扩散至整个场景:
- 动态实例解码器:先聚合实例级特征,再以生成式策略重建富含实例信息的鸟瞰图(BEV)表示,通过加权融合不同实例的BEV特征,增强场景语义的完整性;
- 局部注意力细化:利用窗口注意力,以聚合特征为查询、实例感知BEV特征为键值,局部细化BEV特征,最后转换回3D形状完成预测。
这一过程既提升了场景的空间一致性,又弥补了体素语义信息不足的问题。
创新点3:以物体为中心的预测范式—— 从全局模糊到实例精准
Ocean最核心的创新,是跳出“自我中心”的全局特征融合思路,首次将MobileSAM的2D实例先验有效扩展到3D空间,通过“实例分组-特征聚合-全局校正-局部扩散”的全流程设计,实现了真正的物体级3D特征学习。
三、实验验证:刷新两大基准SOTA
1. 核心性能对比
Ocean在SemanticKITTI和SSCBench-KITTI360数据集上均超越现有方法:
- SemanticKITTI:IoU 46.40,mIoU 17.40,超过CG-Former 1.21(IoU)和0.77(mIoU);
- SSCBench-KITTI360:mIoU 20.28,超过利用遥感模态的SG-Former,验证了纯视觉方案的优越性。
可视化结果清晰显示,Ocean能精准捕捉汽车、道路等物体的细粒度结构,即使是自行车、植被这类难分割的物体,也能输出更准确的语义预测: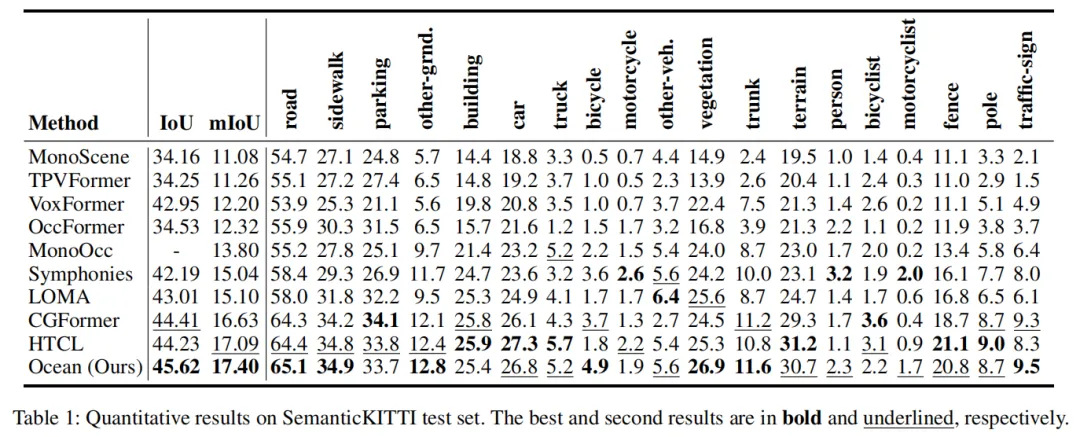 ▲ SemanticKITTI验证集可视化:Ocean(右)精准捕捉物体边缘和细节
▲ SemanticKITTI验证集可视化:Ocean(右)精准捕捉物体边缘和细节
2. 消融实验:验证核心模块有效性
- SGA3D:引入后IoU/mIoU提升1.15/0.69,移除多尺度特征或3D扩展设计,性能显著下降;
- GSGA:移除后IoU/mIoU明显降低,证明其能有效缓解掩码错误带来的信息丢失;
- ILD动态解码器:动态加权融合策略相比直接求和,mIoU进一步提升0.3,验证了生成式BEV重建的价值。
四、总结与展望
Ocean框架的提出,为基于视觉的3D语义场景补全提供了全新的“物体中心”思路:
- 首次将MobileSAM的2D实例先验有效扩展到3D空间,解决了语义/几何模糊问题;
- SGDA和ILD模块的协同设计,既保证了实例特征的精准聚合,又实现了场景级的语义扩散;
- 两大权威数据集的SOTA性能,充分验证了以物体为中心范式的有效性。
这一工作不仅提升了3D语义场景补全的精度,也为自动驾驶感知、3D场景理解等领域提供了新的研究方向——未来结合时序信息、多模态融合,物体中心的学习范式有望进一步释放潜力。


