自动驾驶的发展始终围绕着架构设计有很多争议,是坚持逻辑清晰、可解释性强的模块化工程路径,还是拥抱数据驱动、高度集成的端到端?本文将详细解读。
一、传统自动驾驶与端到端自动驾驶
在深入历史脉络之前,必须厘清两种路线的本质区别。传统模块化架构遵循“感知-预测-决策-控制”的流水线,其优势在于分工明确、可调试性强,符合经典工程思维,也是推动自动驾驶早期落地的主力。然而,其信息在模块间传递时可能失真,误差存在累积风险,且面对复杂场景时系统耦合性与维护成本剧增。
端到端自动驾驶则旨在构建一个统一的深度神经网络,直接从原始传感器数据映射到最终的车辆控制信号。其核心思想是模仿人类驾驶的“直觉”过程,通过数据驱动来隐式地学习驾驶所需的一切特征与规则,从而在理论上实现更优的信息利用和更紧密的跨模块协同。
二、技术演进四十年:从朴素网络到统一认知架构
1. 1980s-1990s:思想萌芽与早期实践
端到端的思想远早于深度学习时代。1989年,卡内基梅隆大学的ALVINN系统首次验证了这一可能性。这个仅有三层的前馈神经网络,以30x32像素的灰度图像为输入,直接输出方向盘转角。尽管模型简单、场景受限,但它奠定了“从像素到控制”的理论基石。同期,欧洲PROMETHEUS项目虽更接近模块化方案,但其在高速公路上实现的长距离自动驾驶,证明了视觉到控制闭环的可行性,为后续研究提供了重要工程参考。
2. 2010s:深度学习驱动的复兴
随着卷积神经网络在图像识别领域取得革命性成功,端到端自动驾驶迎来复兴。2016年,NVIDIA的PilotNet成为标志性事件。它采用更深的CNN网络和模仿学习,在高速公路场景中表现稳定。其关键贡献在于引入了闭环仿真测试框架,使得模型能在虚拟环境中进行长期行为评估,这为此后研究建立了方法论基础。
为解决PilotNet无法处理复杂意图(如转弯)的问题,2018年的条件模仿学习(CIL)引入高层指令(如“左转”、“直行”)作为条件输入,使模型能够根据任务目标调整驾驶策略,显著提升了在复杂路口等场景下的泛化能力。
3. 2018-2020:从模仿到交互与探索
单纯的模仿学习存在“协变量偏移”的固有缺陷——模型在训练数据分布之外容易失效。研究开始引入强化学习来赋予系统“试错”与“自我优化”的能力。
模仿与强化结合:如CILRS模型,在CIL基础上加入速度输入,并在CARLA仿真器中利用奖励函数(车道保持、避免碰撞)进行微调,实现了初步的在线自适应。
纯强化学习探索:Wayve的“Learning to Drive in a Day”工作展示,仅用约20分钟的真实世界交互数据,通过深度确定性策略梯度算法和“无接管即奖励”的简单设定,车辆就能学会车道保持。这验证了强化学习从零直接学习驾驶策略的潜力。
4. 2020s至今:规模化、统一化与认知深化
当前阶段的核心在于构建能够处理大规模、多模态数据,并进行时空统一推理的架构。
三、核心挑战与未来发展
尽管进展迅速,端到端自动驾驶迈向大规模落地仍面临严峻挑战:
可解释性与可验证性:“黑箱”特性难以满足汽车行业对功能安全的严苛要求。未来趋势是发展“灰盒”模型,通过引入可解释的中间表示、辅助任务或与符号化推理结合,使决策过程可追溯、可审计。
长尾场景与安全性:如何确保模型在极端罕见或危险场景下的可靠行为,是最大挑战之一。解决方案包括合成数据生成、对抗性测试、以及与世界模型结合进行安全推演。
数据与仿真依赖:高性能严重依赖海量高质量数据与高保真仿真。构建更高效的闭环数据采集系统和更逼真的数字孪生环境是关键。
未来趋势将聚焦于三个方向:
世界模型与内部模拟:让智能体在潜在空间中“想象”不同行动的未来后果,从而进行更安全、更拟人的规划。
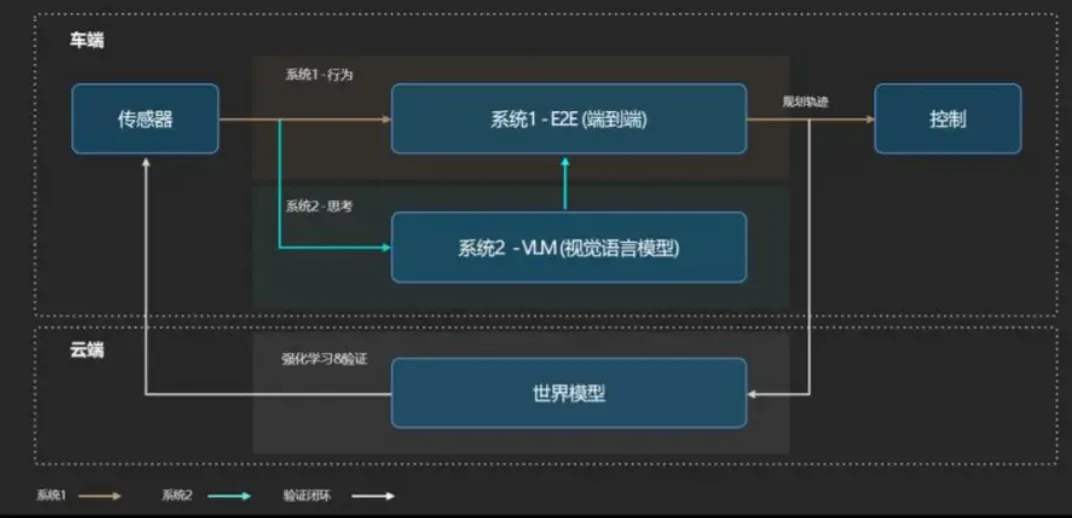
大模型与认知能力:借助大型语言模型和视觉-语言模型的世界知识、推理能力与泛化性,提升系统对复杂场景的语义理解和因果推理水平。
融合架构:纯粹的端到端与传统的模块化并非零和博弈。未来更可能涌现“混合架构”,即核心的感知-预测部分采用数据驱动的统一模型以保证性能,而在规划控制层则结合可验证的规则与优化算法,以实现安全、性能与可解释性的平衡。
结论
端到端自动驾驶的四十年历程,是一部从朴素思想到复杂系统、从孤立学习到统一认知的演进史。它并非要完全取代模块化方法,而是提供了另一种通过数据驱动来逼近驾驶智能本质的路径。其发展深刻受益于深度学习、算力提升与仿真技术的进步。
未来,端到端范式将继续向可解释、可验证、具有认知深度的方向演进,并与模块化工程的严谨性相结合,最终推动实现更安全、更智能、更通用的自动驾驶系统。这场架构之争的答案,或许正是两者优势融合所诞生的新一代自动驾驶大脑。