自动驾驶+百亿向量,全球GPU龙头如何用Milvus加速模型训练
- 2026-05-14 17:23:11
自动驾驶+百亿向量,全球GPU龙头如何用Milvus加速模型训练
自动驾驶的研发,离不开三要素:算法、算力与数据。 今天的投稿用户,本身已经是全球最顶尖的GPU玩家,也是自动驾驶赛道上的重磅算法解决方案提供商,对他们而言,唯一让他们困扰的,只剩下了数据。 而这种困难,又可以被拆解为三个维度:数据总量多、模态复杂、检索难度大。 看似都是行业共性问题,但当规模达到一定量级,就会影响整体技术的演进与成本的管控。但好在,通过Milvus搭建多模态数据挖掘系统,这家巨头一举解决了扩展性、成本、召回率等多方面的问题。 以下是对这家巨头如何建立多模态数据挖掘系统的复盘(根据工程师采访口述内容整理)。 说起多自动驾驶中的模态数据利用,很多人第一反应会是corner case挖掘。这确实是我们的核心诉求,但绝不是全部。 除了挖掘corner case,多模态数据还支撑着我们另外两大核心工作:模型训练与模型测试。 懂行的人都清楚,自动驾驶模型的迭代升级,离不开海量、高质量且多样化的训练数据支撑。我们需要收集足够多晴天与雨天、城市与高速、白天与夜间等各类场景的样本,用丰富的场景覆盖,让模型变得更聪明,才能应对真实道路上的各种突发情况。 而模型训练完成后,测试环节同样离不开多模态数据。工程师们会从已有数据中,按时间、地域等不同维度,筛选出各种特定测试场景,再对比不同版本模型的识别精度、反应速度等表现差异,快速找到新模型的优化点和不足,推动模型持续迭代。 除此之外,我们还会用这些数据测试各类自研的embedding模型。不同模型生成的embedding数据,会被单独存放在不同集合中,既不会干扰生产系统的正常运行,也不用投入大量精力做定制化开发适配,原本需要几天甚至几周才能完成的模型测试分析,现在一键就能实现,效率提升尤为明显。 详情可见:深度分析 | 自动驾驶数据挖掘的三座大山与向量数据库胜负手 先给大家一组直观的数据:自动驾驶实车路测每小时会产生TB级多模态数据,涵盖摄像头画面、激光雷达点云、定位及车辆状态元数据等,即便经过精选,累计的向量数据也达到了百亿规模。 为实现高效检索,我们组建数百人工程师团队,infra初期选型 FAISS,但其短板很快就随数据增长迅速暴露。 最直观的就是数据管理的瓶颈:路测数据转化为embedding数据后,会对应一个FAISS索引文件,日积月累竟达到了数十万之多,这些文件孤立又重叠,跨天跨区域查询时,工程师得手动调取上百个文件,不仅成本高,效率也完全失控。 除此之外,FAISS的灵活性也远远无法满足生产级的复合检索需求。比如我们想筛选城市道路、小雨天气、前视摄像头的相关场景,FAISS需要单独部署元数据库并开发工具,检索后还得手动过滤;而且它没有内置分组、分区功能,版本控制与查询过滤都需要自定义代码,可扩展性非常差。 最棘手的还是扩展性难题:平台每日都会新增大量数据,再加上embedding模型的持续迭代,在FAISS中每次都需要全量重索引,手动更新数百万索引文件;更关键的是,FAISS没有自动分片、负载均衡能力,根本支撑不了平台数据从十亿到百亿的10倍增长,这也让我们不得不重新寻找更合适的解决方案。 也正因为这些痛点,我们明确了对data infra的新需求:能支撑百亿级向量的秒级检索,分布式架构要具备10倍扩容潜力,能实现向量-元数据混合检索,还能自动管理不同embedding模型的数据(用于模型测试),同时具备生产级的可靠性。 而当时,Milvus几乎是我们唯一的选择。 用4-5亿向量数据完成POC后,我们迅速将Milvus落地生产,而它带来的价值,甚至超出了我们的预期——不仅稳定支撑了百亿向量的写入与查询,实现了降本增效,版本升级与监控变得便捷,数据分发、segment管理、查询路由也都能自动完成,团队研发效率大大提升。 更惊喜的是,将Milvus从2.4版本升级至2.5版本后,依托Mmap、disk ANN,团队的基础设施成本再次降低了 30%,能够以更小规格的 AWS 实例支撑同等负载,索引更多数据。 基于Milvus,我们新的自动驾驶数据处理的新架构设计如下: 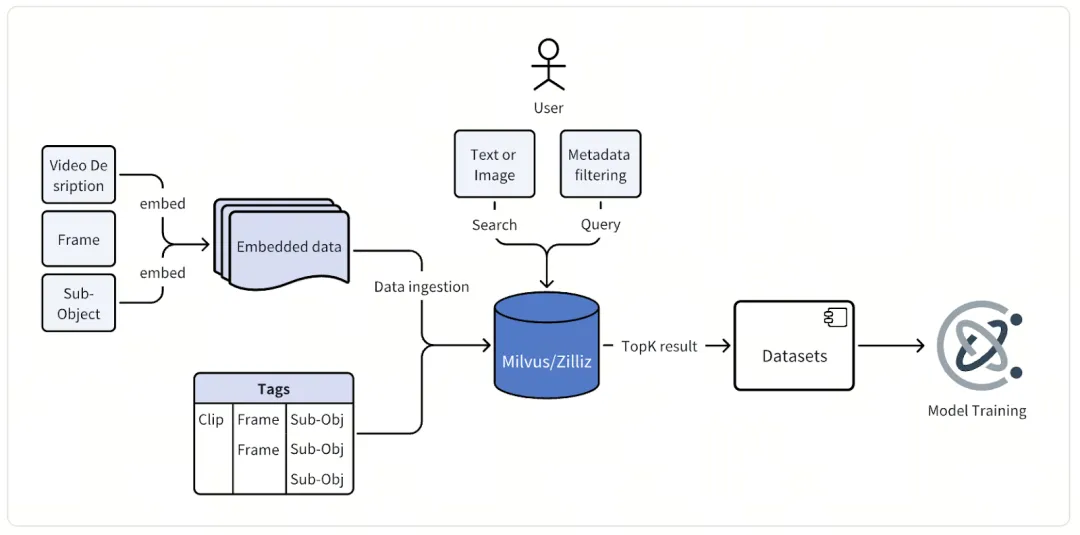
首先,路测车辆传回的连续视频数据,会先被拆解成一帧帧图像或几秒长的短视频片段;接着,这些视觉数据会经过我们两套自研模型的处理——一套专门处理图像数据,基于CLIP架构优化,核心作用是捕捉道路场景的语义特征;另一套则处理视频数据,采用我们自研的物理AI基础模型。经过这两套模型的处理,原本的视觉数据就转换成了蕴含丰富场景信息的高维向量数据。 之后,这些embedding数据会和详细的元数据一起,被存入并索引到Milvus中。这里的元数据,包含了路测会话信息、摄像头位置、时间戳、车辆状态、地理位置、天气条件等关键属性,我们也会为这些元数据单独建立索引,为后续的精准过滤提供支撑。 到了最后的交互环节,工程师们可以通过统一的查询界面,用多种方式检索数据:输入一段文字描述(比如“夜间城市路口行人横穿”)、上传一张参考图片或视频,甚至直接组合向量搜索与元数据过滤条件,Milvus都能快速返回最相关的图像或视频片段,供团队开展分析和模型训练工作。 最值得一提的是,Milvus 还支持了NVIDIA cuVS 索引。该技术通过GPU建立索引、CPU完成检索的模式,既加快了索引构建速度,又保证了成本效益。这对于需要频繁更新索引、依赖新鲜数据迭代模型的自动驾驶业务来说,无疑是雪中送炭。 详情可见:英伟达首席工程师Corey: HNSW+CPU过时了!GPU+RAPIDS cuVS才是向量检索最优解 在大规模落地Milvus的过程中,我们积累了不少实操经验,也踩过一些坑,以下是具体复盘。 先说说索引的选择。 Milvus支持多种索引,每种索引在速度、内存占用和精度上,都有不同的取舍。而在我们的核心场景——corner case挖掘中,我们最终选定了IVF_FLAT索引。这种索引会先将向量聚类,再在相关簇内做精确搜索。虽然这不是速度最快、占用空间最小的索引类型,但对于我们百亿级向量规模和秒级延迟的需求来说,它能在性能和精度之间实现很好的平衡,同时保证较高的资源利用效率。 详情可见:向量数据库是如何检索的?基于 Feder 的 IVF_FLAT 可视化实现 再聊聊成本管控。 我们做的一个明智选择,是启用了Mmap功能。在传统架构下,要把所有向量数据放在内存中,就必须配置高昂的大规格实例;而开启Mmap后,大部分数据会存储在磁盘上,操作系统会自动将高频访问的数据加载到内存中。当然,这会带来一点点延迟,毕竟磁盘读取速度比不上内存,但对于我们离线的内部数据挖掘场景来说,这个代价完全可以接受。工程师们的分析查询对延迟并不敏感,系统并发量也不高,用一点点延迟,换来了基础设施成本的大幅降低,是一笔划算的买卖。 详情可见:数据处理量翻倍! Milvus MMap 一触开启 而我们踩过的最大的坑,来自一个看似简单的操作:删除数据。 Milvus采用的是追加式架构,被删除的向量不会立刻清理,而是先标记删除,再通过后台的合并操作完成清理。在测试期间,我们删除数百万向量时,意外触发了数十亿向量的重新索引,原因是Bloom filters在数千个数据段上产生了误判,导致数据节点负载过高,业务直接停滞。 后来,我们通过调整Bloom filters参数、用分区键精准定位删除范围、切换到只插入的批量加载模式,才彻底解决了这个问题。 这件事也给我们提了个醒:在大规模系统中,只有吃透系统底层逻辑,才能真正保证业务稳定运行。 目前,我们团队已经在筹备将Milvus升级至2.6版本。据悉,新版本引入的RaBitQ索引和架构优化,有望在大型离线批处理工作负载中,进一步提升性能和成本效益,让多模态数据挖掘变得更高效、更经济。 详情可见1bit压缩+高召回,RaBitQ如何成为AI infra的embedding 量化最优解 除此之外,我们也在持续挖掘Milvus的混合搜索功能——计划通过融合文本和向量查询,解锁多模态数据探索的新方式;而Milvus强大的数据库级过滤能力,也能帮助我们进一步简化复杂的业务流程,让多模态数据的价值得到更充分的释放。 详情可见实战Milvus 2.5:语义检索VS全文检索VS混合检索 Milvus Week | 向量搜索遇上过滤筛选,如何选择最优索引组合? 

01
我们用多模态数据在做什么?
02
我们需要怎样的多模态数据管理infra?
03
如何用 Milvus 重构底层data infra
04
踩坑经验复盘
05
长期规划
阅读推荐 高效索引之HNSW_SQ:如何同时兼顾RAG的速度、召回率与成本 Spark做ETL,与Ray/Daft做特征工程的区别在哪里,如何选型? RAG优化不抓瞎!Milvus检索可视化,帮你快速定位嵌入、切块、索引哪有问题 Milvus+印度最大电商平台,如何打造服务两亿月活用户的商品比价系统 都有混合检索与智能路由了,谁还在给RAG赛博哭坟?
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 智享升级,焕新体验|梅赛德斯-奔驰S级轿车
- 何小鹏官宣AI新豪华大六座旗舰SUV——小鹏GX
- Waymo千亿估值融资背后:自动驾驶“军备竞赛”进入决战阶段
- 【司法拍卖】鲁P5B277奥迪牌小型轿车一辆
- 七旬夫妇开“老头乐”闯红灯,与正常行驶轿车相撞,获赔36万元!详情披露
- 驶过关键里程碑:自动驾驶迈向多元场景
- 真强!12月插电混动轿车销量榜:比亚迪大胜,银河A7第5,汉L第18
- 从自动驾驶 SoC 到 OBC:AI 车载时代被放大的电流感测战场
- 10万级燃油轿车销量,朗逸第2,帝豪仅第14怎一个惨字了得
- “平民轿车”年度销量王:需求量没想到这么大,一年狂销38万台
